Applying Domain-Driven Design in Practice

By Kevin Campusano
May 26, 2026

Photo by Josh Ausborne, 2007.
This is part 4 of a series of blog posts on Domain-Driven Design:
Domain-Driven Design is an approach to software development that focuses on, as Eric Evans puts it, “tackling the complexity in the heart of software”. And what is in the heart of software? The business domain in which it operates. Or more specifically: a model of it, made of code. That is, the code that implements the business logic that comes into play when solving problems within the realm of a particular business activity.
DDD is not just about writing code though. It’s a whole methodology that touches on business needs, requirements gathering, organizational dynamics, high level architectural design, and lower level patterns for implementing software intensive systems.
As a result, DDD offers a treasure trove of concepts, patterns and tools that can be applied to any software project, regardless of the size and complexity.
In this series of blog …
software architecture design books
Solving High-Resolution Video Stutter with GStreamer Hardware Acceleration

By Alejandro Ramon
May 18, 2026

Photo from the VisionPort website.
In April, a client at Auburn University reached out to VisionPort Support to ask us to look into an issue with video playback for an upcoming presentation. They were running into performance issues attempting to play a video matching the full resolution of the seven-screen video wall, across all screens.
We have other clients playing video across all screens normally, on the same hardware and software, with no issue, so this was a strange report to the team. The seemingly simple request ended up leading us down a rabbit hole into how video playback works on the VisionPort platform and ultimately led to some serious modernization of our video rendering stack, the process of which we would like to share with you today.
Why was a system designed to play high-resolution video seamlessly across seven screens performing so poorly?
The System: A GStreamer Pipeline
The VisionPort video player is a custom application built on top of the GStreamer framework, initially developed to synchronize video across separate computers on our legacy Liquid Galaxy hardware configurations.
Each instance of the player renders a single video. This can be the full …
video visionport hardware ubuntu
Building a Multi-Agent Travel Planner with Microsoft Agent Framework and .NET

By Bimal Gharti Magar
May 15, 2026

Photo by Seth Jensen, 2022.
Large language models can answer travel questions well enough, but a single prompt is rarely enough to produce a plan you can trust end to end. Budget math can drift, travel times can be unrealistic, and a confident recommendation may not be grounded in the data the model actually saw.
One way to improve that is to split the work across specialized agents. In this project, one agent researches the destination, another builds the itinerary, another checks the budget, another audits the result, and the last one turns everything into a polished response.
In this post, we will build that workflow in .NET 10 using the Microsoft Agent Framework (MAF). The project supports both local Ollama models and Anthropic through a shared IChatClient abstraction, exposes a Web API with a streaming endpoint, and includes evaluation tests using Microsoft.Extensions.AI.Evaluation.
The source code is available on GitHub.
What we’ll build
- A sequential multi-agent pipeline: Researcher -> Planner -> Accountant -> Auditor -> Aggregator
- Provider-swappable LLM integration with Ollama and Anthropic
- Deterministic validation tools for budget, timing, groundedness, …
dotnet csharp artificial-intelligence programming
Introducing EP Audit

By Dan Briones
May 11, 2026

Photo by Bimal Gharti Magar, 2026.
In the complex landscape of cloud security, staying compliant and prepared for audits is important. Enter EP Audit, a compliance-focused audit process, AI-powered but led by senior engineers. It’s designed for Azure, AWS, and Google Cloud setups. EP Audit emerged from necessity: When a financial services client required an Azure security audit, we at End Point built a solution that not only met their immediate needs, but also evolved into an internal tool we continue to refine. Today, it serves as a key part of our multi-cloud security audit framework and is tested against our own cloud accounts before being used in client engagements.
The Problem
Cloud environments are dynamic: New projects, personnel changes, and vendor updates can significantly alter configurations over time. As environments evolve, the security posture originally reviewed and approved by your engineers may no longer fully match what is running in production. Unused resources, overly permissive access, and orphaned infrastructure can also accumulate over time, increasing both risk and monthly costs. This often goes unnoticed until an audit, customer review, or security …
security hosting tools
Designing software architecture with Domain-Driven Design
By Kevin Campusano
May 5, 2026

Photo by Juan Pablo Ventoso, 2023.
This is part 3 of a series of blog posts on Domain-Driven Design:
Domain-Driven Design is an approach to software development that focuses on, as Eric Evans puts it, “tackling the complexity in the heart of software”. And what is in the heart of software? The business domain in which it operates. Or more specifically: a model of it, made of code. That is, the code that implements the business logic that comes into play when solving problems within the realm of a particular business activity.
DDD is not just about writing code though. It’s a whole methodology that touches on business needs, requirements gathering, organizational dynamics, high level architectural design, and lower level patterns for implementing software intensive systems.
As a result, DDD offers a treasure trove of concepts, patterns and tools that can be applied to any software project, regardless of the size and complexity.
In this series of …
software architecture design books
Implementing business logic with Domain-Driven Design
By Kevin Campusano
April 21, 2026

Photo by Bimal Gharti Magar, 2026.
This is part 2 of a series of blog posts on Domain-Driven Design:
Domain-Driven Design is an approach to software development that focuses on, as Eric Evans puts it, “tackling the complexity in the heart of software”. And what is in the heart of software? The business domain in which it operates. Or more specifically: a model of it, made of code. That is, the code that implements the business logic that comes into play when solving problems within the realm of a particular business activity.
DDD is not just about writing code though. It’s a whole methodology that touches on business needs, requirements gathering, organizational dynamics, high level architectural design, and lower level patterns for implementing software intensive systems.
As a result, DDD offers a treasure trove of concepts, patterns and tools that can be applied to any software project, regardless of the size and complexity.
In this series of …
software architecture design books
Observing End Point Dev's Approach to AI

By Jesse Gardner
April 16, 2026

Photo by Garrett Skinner, 2022.
When I joined End Point Dev in October of 2025, there was one clear directive among a wide-ranging set of responsibilities: AI is causing drastic changes in our industry, and we need to tackle it head-on.
As a non-engineer working in a software development consultancy, there is a double edged sword in focusing my work on AI. The downside, of course, is my lack of expertise in anything involving code. I’ve sold software for a majority of my career, but I haven’t been the one building it. A reasonable person could wonder: how would I have a useful perspective on the developments around AI?
To that there are a few answers. For starters, I don’t get bogged down in the “how” AI is working as much as I am interested in the results of its work. I’ve certainly learned context windows, token usage, rate limits, and other immediately useful information around utilizing AI.
I also get to be a guinea pig for End Point’s suite of AI services. Our team might be primarily technical users, but that does not mean our clients necessarily have that same background. I get to approach AI tools as an interested user, not a development wizard.
With that said, these past …
artificial-intelligence vibe-coding
Getting the Most from your Claude Subscription
By Dan Briones
April 14, 2026

Photo by Josh Ausborne, 2006.
Every prompt you send to Claude Code costs tokens. If you understand where those tokens go and how to control them, you can stretch your subscription dramatically further. This guide covers the practical steps I have taken to keep my usage lean without sacrificing capability.
What are Tokens?
A token is the smallest unit of text Claude processes. A token is roughly three-quarters of a word. The sentence “Hello, how are you today?” is about seven tokens. Every interaction, yours and Claude’s, is measured in tokens drawn from a fixed context window.
Think of the context window as a whiteboard. Everything Claude needs to know must fit on it: your instructions, the conversation so far, any files it reads, and its own responses. When the whiteboard fills up, older content must be erased to make room.
What Loads with every Prompt
Most people assume they are only paying for the text they type. In reality, Claude loads a stack of context before it even reads your message.
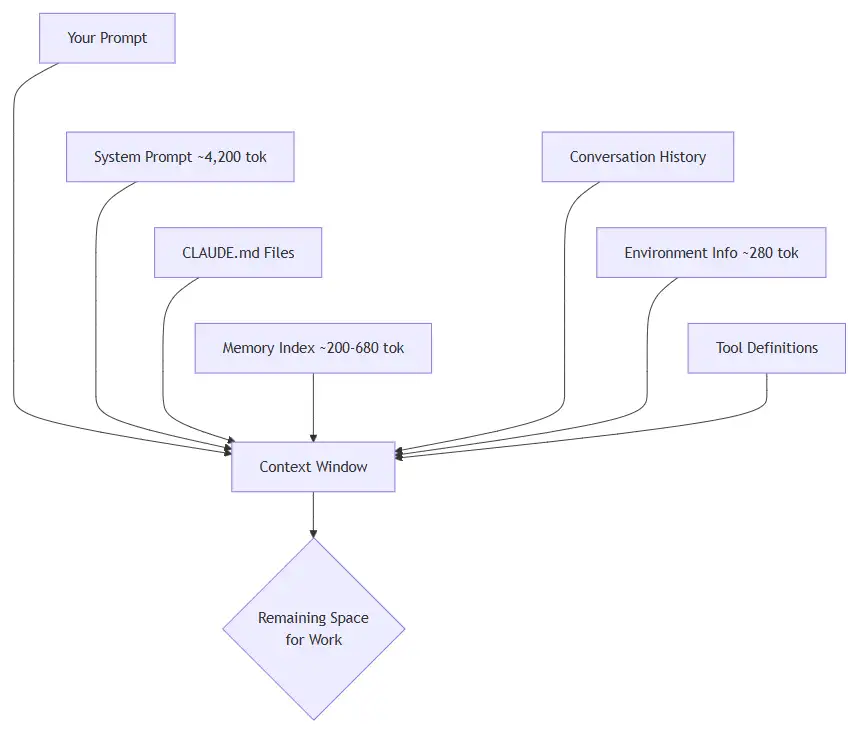
Breakdown of what gets loaded:
| Source | Tokens | When |
|---|---|---|
| System prompt | ~4,200 | Every … |
artificial-intelligence tools