Vector Search: The Future of Finding What Matters

By Kürşat Kutlu Aydemir
July 1, 2025

Photo by Ann H on Pexels
In a world flooding with data in several different formats like images, documents, text, and videos, traditional search methods are starting to not be modern anymore. Today, the vector search technique is revolutionizing how we retrieve and understand information. If you wonder how Spotify can recommend the perfect song or how Google can find almost perfectly accurate image matches, vector search is kind of the wizard behind the curtain. Let’s see how it has become a game changer.
What Is Vector Search?
At its core, vector search is a method of finding similar items in a dataset by representing them as vectors — essentially, lists of numbers in a multi-dimensional space. Unlike keyword-based search, which relies on exact matches or predefined rules, vector search focuses on semantic similarity. This means it can understand the meaning or context behind data, not just the words or pixels on the surface.
Imagine you’re searching for a cozy cabin in the woods. A traditional search might get stuck on the exact words in this query, missing a listing for something similar like a snug retreat nestled in a forest. Vector search, however, can connect the dots because it understands that cozy and snug or woods and forest are conceptually close.
You can try vector search on this blog! There’s a search bar in the header at the top of the page, and you can see our announcement post here.
How Does It Work?
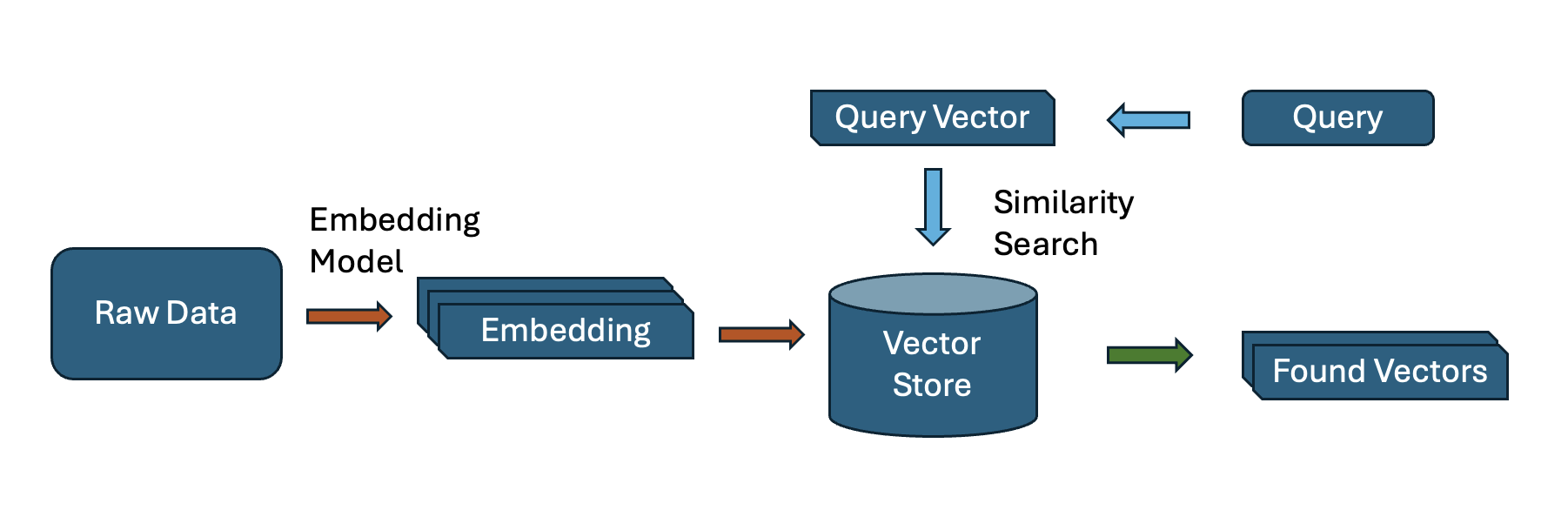
The magic of vector search happens in three key steps:
Embedding Generation
Once you have access to the data sources that you want to apply vector search, you will need to prepare and ingest the data into your system. This phase will handle data clean-up and extraction from different data sources and formats. For multi-modality support you may need to include multiple data formats like text, image, audio, and video.
In the embedding generation phase, as depicted above, raw data (like text, images, or audio) is transformed into vectors using suitable embedding machine learning (ML) models. These models (e.g. all-MiniLM-L6-v2, all-mpnet-base-v2 for text, or ResNet for images) analyze the data and spit out a numerical representation, a vector, that captures its essence. For example, the sentence I love sunny hikes might become something like [-0.07571851, -0.02147608, 0.07130147, 0.1087752, 0.02052169, ...], where each number reflects a feature of its meaning.
Storing Vectors
The generated vectors are then stored in a vector database or an index optimized for fast retrieval. Think of it as a massive, multi-dimensional map where every point represents an item or a chunk of an item. There are several options for your choice like FAISS, Chroma, Milvus, and pg-vector.
Similarity Search
When you use this system with a query like find me green hoodies, it converts your input into a vector too. Then, it searches the vector store for the closest points using mathematical distance metrics like Cosine Similarity or Euclidean Distance. The closer the vectors, the more similar the items.
The result? You get matches that feel right, even if they don’t share exact keywords or pixel patterns.
A Simple Vector Search Implementation
Here, to demonstrate how vector search works, I implemented a simple vector search based on this architecture without using third-party libraries. The best practice is surely using well-known implementations and tools to achieve production ready applications; this is just for demonstration.
Below is a very simple vector store implementation:
import numpy as np
from typing import List, Tuple
class SimpleVectorStore:
def __init__(self):
"""Initialize"""
self.vectors = []
self.ids = []
def add_vectors(self, vectors: List[List[float]], ids: List[str]):
"""Add vectors to vector store"""
if len(vectors) != len(ids):
raise ValueError("Number of vectors must match number of IDs")
vectors = np.array(vectors)
self.vectors.extend(vectors)
self.ids.extend(ids)
self.vectors = np.array(self.vectors)
def cosine_similarity(self, v1: np.ndarray, v2: np.ndarray) -> float:
"""Calculate cosine similarity between two vectors"""
# zero vectors
if np.all(v1 == 0) or np.all(v2 == 0):
return 0.0
dot_product = np.dot(v1, v2)
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
return dot_product / (norm_v1 * norm_v2)
def search(self, query_vector: List[float], k: int = 5) -> List[Tuple[str, float]]:
"""Search for the k most similar vectors"""
if len(self.vectors) == 0:
return []
query_vector = np.array(query_vector)
similarities = [
(self.vectors[i], self.ids[i], self.cosine_similarity(query_vector, vec))
for i, vec in enumerate(self.vectors)
]
# sort and return
similarities.sort(key=lambda x: x[2], reverse=True)
return similarities[:k]Now, let’s store some sample vectors (so-called embeddings) to this simple vector store and perform an example search. In real-world applications this represents the raw data in vector form, but I used dummy embedding values in this example. I also excluded the embedding model phase when creating these embedding values to simplify the code.
if __name__ == "__main__":
# vector store instance
vector_store = SimpleVectorStore()
# example embeddings
sample_embeddings = [
[1.0, 0.0, 0.0], # Vector 1
[0.0, 1.0, 0.0], # Vector 2
[1.0, 1.0, 0.0], # Vector 3
[0.0, 0.0, 1.0], # Vector 4
]
sample_ids = ["doc1", "doc2", "doc3", "doc4"]
# add sample vectors to vector store
vector_store.add_vectors(sample_embeddings, sample_ids)
# query vector
query = [1.0, 0.5, 0.0]
# search for top k = 2 results
top_k = 2
results = vector_store.search(query, k=top_k)
print("Query vector:", query)
print(f"Top {top_k} similar vectors:")
for vector, doc_id, similarity in results:
print(f"DocId: {doc_id}, Vector: {vector}, Similarity: {similarity:.4f}")The output of this search is like below:
Query vector: [1.0, 0.5, 0.0]
Top 2 similar vectors:
DocId: doc3, Vector: [1. 1. 0.], Similarity: 0.9487
DocId: doc1, Vector: [1. 0. 0.], Similarity: 0.8944Now compare the vectors in the results with the query vector. As you can see the bigger similarity scores are the closer ones and are more similar to the query vector.
Why Vector Search is Powerful
Vector search offers several advantages over traditional search methods. First of all, it has a degree of semantic understanding by focusing on contextual meaning rather than keywords: vector search handles synonyms, misspellings, and contextual nuances. For instance, searching car could return results about automobiles or vehicles (assuming you have a well-trained model).
Multimodal capability is another feature which is commonly used today. Vector search isn’t limited to text. It can process images, audio, video, or even combinations of these. For example, you could search for sunset photos using a text query and retrieve visually similar images.
Vector search can incorporate user preferences or behavior like past searches into the vector space and deliver personalized results.
Real-World Examples
Vector search is already everywhere:
-
Retrieval-Augmented Generation (RAG)
Regardless of the industry that a RAG application is designed for, vector search is essential in the retrieval (“R”) phase: it is used to find relevant data for a query to build a context for the LLM.
-
Ecommerce:
Vector search is used for recommending products based on user queries or visual similarity (e.g. “find shoes like these” using an image). Example: Searching for “red sneakers” might return visually similar items even if the product description doesn’t mention “red sneakers”.
-
Content Discovery:
Used for powering recommendation engines for streaming platforms (e.g. Netflix, Spotify) by finding movies, songs, or articles similar to a user’s interests. Example: Suggesting a sci-fi movie based on a user’s love for “Star Wars”.
-
Customer Support:
Used for enabling chatbots to retrieve relevant knowledge base articles or FAQs by understanding the intent behind a user’s question. Example: A query like “how to reset my device” could pull up guides even if phrased differently.
-
Image and Video Search:
Allows users to search for visually similar images or videos, such as finding artwork or stock footage that matches a specific style. Example: Uploading a photo of a beach to find similar vacation destinations.
-
Enterprise Search:
Helps employees find documents, emails, or internal resources by understanding the context of their queries. Example: Searching “project timeline” could retrieve relevant spreadsheets or emails.
-
Healthcare:
Used for matching patient records, medical images, or research papers based on semantic similarity to aid diagnosis or treatment planning. Example: Finding studies related to a specific disease even if terminology varies.
Challenges Ahead
Although computational cost is one of the challenges of performing similarity search on large datasets I won’t mention it as a major challenge.
The main challenges in vector search seem to revolve around interpretability and data quality, as is common in ML. Unlike keyword search, where matches are explicit, vector search operates in a black box, making it harder to explain why certain results were returned.
As for data quality, the adage applies: garbage in, garbage out. If the input data is noisy or incomplete, the embeddings may not accurately represent the content. Data extraction and creating the embeddings of certain data formats (e.g. tables) is another challenge. Searching for accurate table data values is an especially challenging task. At End Point we are using advanced methods and LLM services to overcome these challenges when preparing quality embeddings.
Wrapping Up
Vector search isn’t just a tech buzzword — it’s a fundamental shift in how we interact with data. By moving beyond rigid keywords to a world of meaning and similarity, it’s unlocking possibilities we’re only beginning to explore. Whether you’re a developer building the next big app or just a curious soul, vector search is worth keeping an eye on. It’s not about finding exactly what you typed — it’s about finding exactly what you meant.
artificial-intelligence machine-learning search
Comments