Windows 10 End of Life: What Are Your Upgrade Options?

By Dan Briones
May 6, 2025

As technology evolves, so do operating systems. Microsoft has announced the end of support for Windows 10, meaning that after October 14, 2025, your device will no longer receive critical security updates. This blog post will discuss what this means for you and your upgrade options to Windows 11.
You can search for all Microsoft software lifecycles on the Microsoft Lifecycle Policy page.
Support will end on October 14, 2025, for these editions of Windows 10:
- Windows 10 Enterprise & Education
- Windows 10 Home & Pro
- Windows 10 IoT Enterprise
- Windows 10 Enterprise LTSB 2015
- Windows 10 Team (Surface Hub)
You can see a list of all Microsoft products whose support will end in 2025 on Microsoft’s website.
What Does End of Life Mean?
End of life (EOL) for an operating system means that the software vendor will no longer provide updates, security patches, or technical support. While your computer will still function, it will be more vulnerable to security threats. Continuing to use an unsupported operating system puts your data at risk.
Why Upgrade to Windows 11?
Windows 11 is the latest version of Microsoft’s operating system. It offers several benefits, including: …
windows sysadmin
Converting MIDI to KML using AI: Bach’s Notes in the Hills of Greenland

By Darius Clynes
May 2, 2025
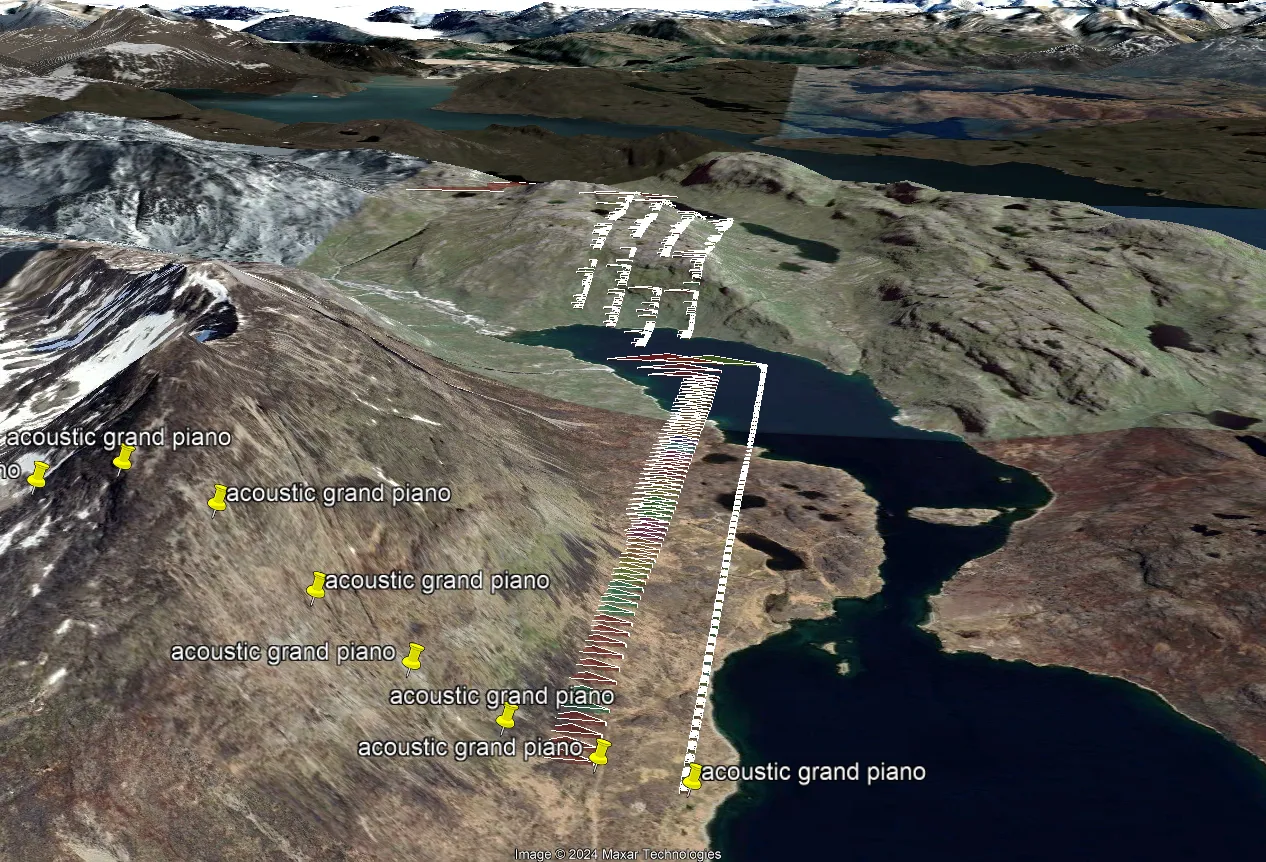
I have always been interested in ways of representing music visually. Aside from conventional music notation, I imagined other cross-modal generation methods that could take a sound and generate an image. In the same vein, I have frequently envisioned a 3D landscape in which you could discover musical “objects”.
Well, now I’ve realized a version of this dream — with caveats which will be mentioned later. In this blog I would like to demonstrate how I used AI (in my case ChatGPT using GPT-4 Turbo) to create an interesting JavaScript application from just a few phrases. In this case, we will be making an application that can take as input an existing piece of music represented by a MIDI file and as output, create a KML file that you can view as 3D objects somewhere on the globe.
Here is how I enlisted ChatGPT to help me:
please make a javascript application that can take a MIDI file and covert it to extruded polygons in a kml file
Here is a part of its response:

I was amazed. It included code to select the MIDI file, convert it to KML, and generate an output file. Plus, ChatGPT correctly interpreted my request despite my “covert” typo. :-)
Before testing it I was interested …
kml gis artificial-intelligence visionport
Understanding the Relationship Between Apex and Salesforce

By Couragyn Chretien
May 2, 2025

Salesforce has become a cornerstone for businesses looking to streamline their customer relationship management. At the heart of its customization capabilities lies Apex, a powerful programming language designed specifically for the Salesforce platform and based on Java syntax. In this post, we’ll explore the relationship between Apex and Salesforce and touch on how Apex differs from the general-purpose language Java.
Apex and Salesforce
Apex is Salesforce’s proprietary programming language, introduced to extend the platform’s functionality beyond its out-of-the-box features. Think of Salesforce as a robust cloud-based ecosystem with pre-built tools for managing leads, contacts, opportunities, etc. While these tools are configurable through point-and-click interfaces, there are times when businesses need custom solutions. That’s where Apex comes in.
Apex runs natively on Salesforce’s platform. This tight integration allows Apex to interact seamlessly with Salesforce data (like objects and fields), execute triggers based on record changes, and build custom APIs. For example, a developer might use Apex to automate a discount approval process or sync …
java salesforce
Interchange Compression for SessionDB

By Mark Johnson
April 30, 2025

New support for compression of sessions and more lists stored in a RDBMS has been added to core Interchange.1,2
A new module, Vend::Util::Compress, operates as a general interface for compressing and uncompressing scalar data in Interchange. The module currently offers hooks for the following compression algorithms:
- Zstd (preferred)
- Gzip
- Brotli
Additional algorithms can be easily added as needed.
Each algorithm depends on the developer having installed the necessary CPAN modules for the given compression type:
IO::Compress::Zstd/IO::Uncompress::UnZstd3IO::Compress::Gzip/IO::Uncompress::Gunzip4IO::Compress::Brotli/IO::Uncompress::Brotli5
Vend::Util::Compress exports compress() and uncompress() on demand. In scalar context, they return the reference to the scalar holding the transformed data. In list context, they return additional measurements from the process.
List compress() returns an array of:
$ref$before_size$after_size$elapsed_time$alert
List uncompress() returns an array of:
$ref$elapsed_time$alert
Any errors encountered when called in scalar context are written to the catalog error log. Errors encountered when called in list context are returned in $alert. …
ecommerce interchange
Handling text encoding in Perl

By Marco Pessotto
April 29, 2025

When we are dealing with legacy applications, it’s very possible that the code we are looking at does not deal with Unicode characters, instead assuming all text is ASCII. This will cause a myriad of glitches and visual errors.
In 2025, after more than 30 years since Unicode was born, how is that possible that old applications still survive while ignoring or working around the whole issue?
Well, if your audience is mainly English speaking, it’s possible that you just experience glitches sometimes, with some characters like typographical quotes, non breaking spaces, etc. which are not really mission-critical. If, on the contrary, you need to deal every day with diacritics or even different languages (say, Italian and Slovenian), your application simply won’t survive without a good understanding of encoding.
In this article we are going to focus on Perl, but other languages face the same problems.
Back to the bytes
As we know, machines work with numbers and bytes. A string of text is made of bytes, and each of them is 8 bits (each bit is a 0 or a 1). So one byte allows 256 possible combinations of bits.
Plain ASCII is made by 128 characters (7 bits), so it fits …
perl unicode
How to Migrate from Struts 2 to Struts 6

By Kürşat Kutlu Aydemir
April 17, 2025

With the introduction of Struts 6, developers are provided enhanced features, security improvements, and modern practices that align with contemporary Java development. If you’re currently using Struts 2, migrating to Struts 6 is a worthwhile endeavor that can future-proof your application.
Also, since Struts 2.5.x reached its end of life, there won’t be any security updates for this version. This guide will walk you through the key differences between Struts 2 and Struts 6, including some significant changes in Struts 6 with practical configuration and code examples.
Getting Ready for Migration from Struts 2 to Struts 6
Starting from Struts 6.0.0 the framework requires Java 8 at minimum. So, if you are running a Struts 2.x environment on an old version of Java, it needs to be upgraded to Java 8 at least. Check out the Struts 6.0.0 version notes for a list of changes.
Config and Code Changes
Servlet API Dependency
Struts 6.0.0 requires Servlet API 3.1 or newer and won’t work with the older versions. The Maven dependency that you can use for this is below:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api …java apache-struts frameworks migration
Testing Ansible Automation with Molecule

By Kannan Ponnusamy
March 28, 2025

1. Why Test with Molecule?
Molecule is a test framework for Ansible roles. It supports testing with multiple instances, operating systems and distributions, virtualization providers, test frameworks, and testing scenarios.
Molecule is useful because it increases confidence in your automation and ensures roles are reliable. It catches issues early in the development cycle, reducing production problems. It also ensures consistency across different environments and platforms.
2. Install Prerequisites
Make sure you have Python >= 3.6 and pip installed. Then install Ansible and Molecule using pip:
pip install ansible
pip install molecule
Molecule uses the delegated driver by default. Other drivers can be installed separately from PyPI, most of them being included in the molecule-plugins package. We are going to use the Docker driver, so let’s install that by running:
pip install "molecule[docker]"
3. Ansible Monorepo Structure
We use the Ansible monorepo structure. This means our playbooks, variables, scripts, roles, plugins, inventory scripts, and configuration all reside and are version controlled together in the same repository.
Here is …
sysadmin linux integration cloud devops
Getting Output from jps with NRPE

By Muhammad Najmi bin Ahmad Zabidi
March 22, 2025

One of the tools our hosting team uses for server and site monitoring is Icinga (which is based on Nagios). When monitoring host resources, one of the tools we use is Nagios Remote Plugin Executor or NRPE.
We encountered an issue when executing NRPE: though NRPE runs on the server being monitored, it wasn’t giving the same output as a script which was executed on the server itself. The NRPE-related call should have no issues be executed on the target server, as it is declared in the sudoers file (commonly /etc/sudoers). In this post, I will explain how to get the output from jps (Java Virtual Machine Process Status Tool), which can only be executed as root.
Getting process information with jps
Let’s say we have a “hello world” program named Hello.java. How do we get the process’s state from Icinga’s head server?
First, let’s compile and run the program.
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, World!");
try {
Thread.sleep(3000); // Sleep for 3 seconds
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
java …linux monitoring nagios java