Custom validation with authlogic: Password can't be repeated.

By Marina Lohova
December 7, 2012
I recently worked on a small security system enhancement for one of my projects: the user must not be able to repeat his or her password for at least ten cycles of change. Here is a little recipe for all the authlogic users out there.
We will store ten latest passwords in the users table.
def self.up
change_table :users do |t|
t.text :old_passwords
end
endThe database value will be serialized and deserialized into Ruby array.
class User
serialize :old_passwords, Array
endIf the crypted password field has changed, the current crypted password and its salt are added to the head of the array. The array is then sliced to hold only ten passwords.
def update_old_passwords
if self.errors.empty? and send("#{crypted_password_field}_changed?")
self.old_passwords ||= []
self.old_passwords.unshift({:password => send("#{crypted_password_field}"), :salt => send("#{password_salt_field}") })
self.old_passwords = self.old_passwords[0, 10]
end
endThe method will be triggered after validation before save.
class User
after_validation :update_old_passwords
endNext, we need to determine if the password has changed, excluding …
rails
Interactive Piggybak Demo Tour

By Steph Skardal
December 6, 2012
A new interactive tour of Piggybak and the Piggybak demo has been released at piggybak.org. Piggybak is an open source Ruby on Rails ecommerce framework built as a Rails 3 engine and intended to be mounted on existing Rails applications.
The tour leverages jTour (a jQuery plugin) and guides you through the homepage, navigation page, product page, cart and checkout pages, gift certificate page, advanced product option page, and WYSIWYG driven page. The tour also highlights several of the Piggybak plugins available and installed into the demo such as plugins that introduce advanced product navigation, advanced product optioning, and gift certificate functionality. Below are a few screenshots from the demo.
An interesting side note of developing this tour is that while I found many nice jQuery-driven tour plugins available for free or at a small cost, this jQuery plugin was the only plugin offering decent multi-page tour functionality.
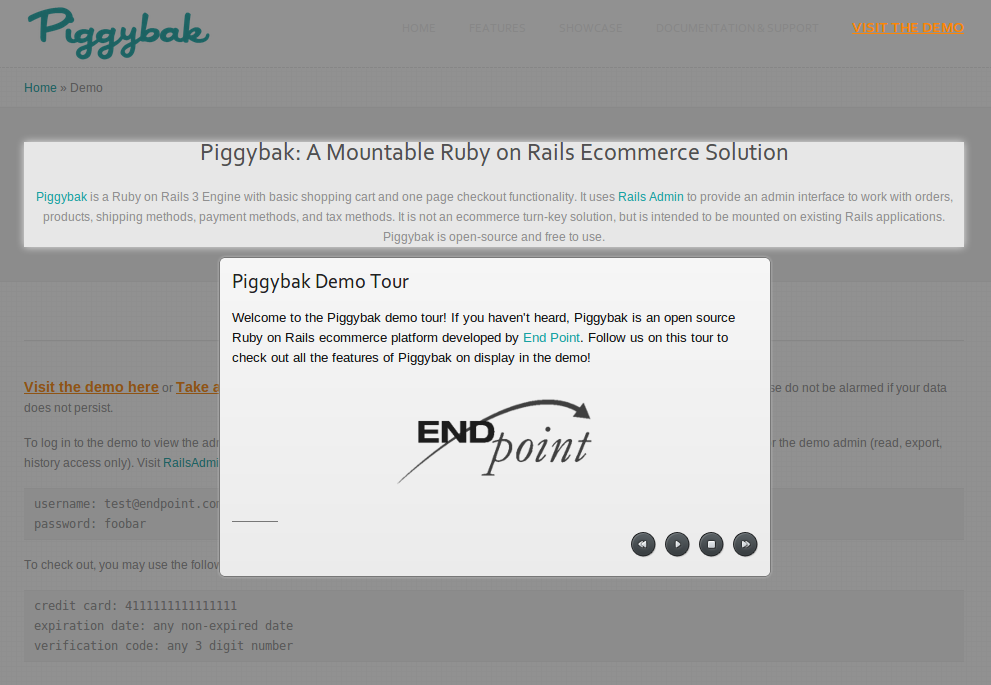 Here is the starting point of Piggybak tour. |
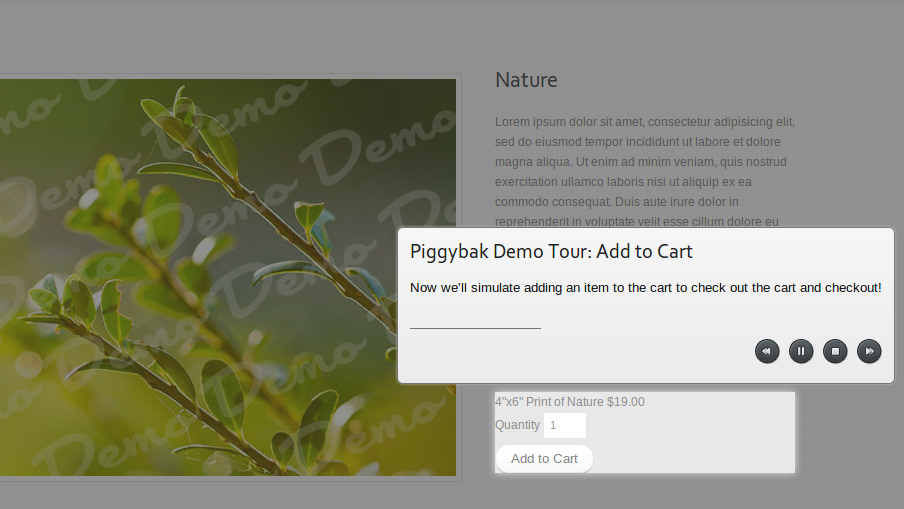 The Piggybak tour adds an item to the cart during the tour. |
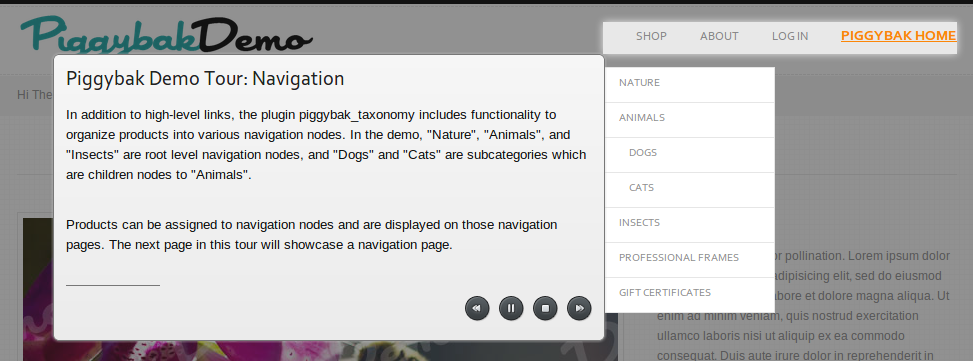 The Piggybak tour highlights advanced product navigation in the demo. |
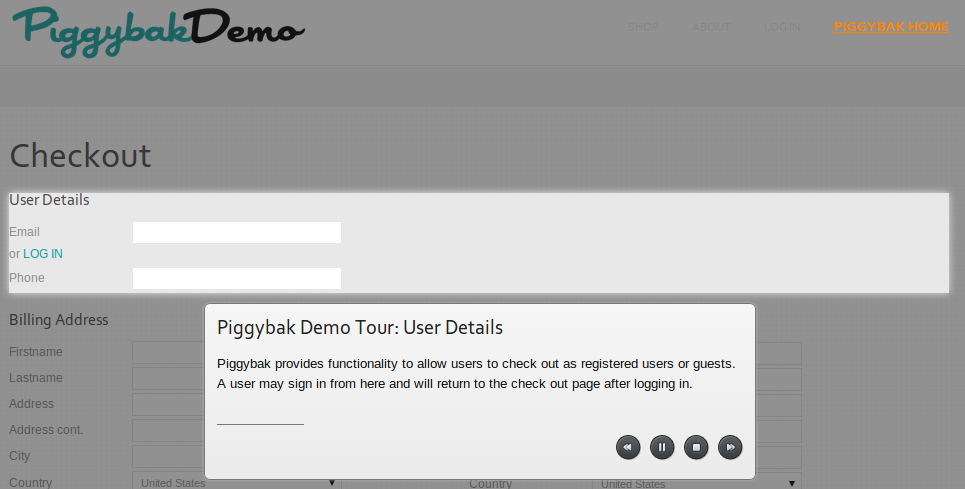 The Piggybak tour highlights features and functionality on the one-page … |
javascript jquery piggybak rails
Mobixa: A Client Case Study
By Steph Skardal
December 5, 2012

A few weeks ago we saw the official (and successful!) website launch for one of our clients, Mobixa. Mobixa will buy back your used iPhones and/or provide you with information about when you should upgrade your existing phone and sell it back. Right now, Mobixa is currently buying back iPhones and advising on iPhones and Androids. End Point has been working with Mobixa for several months now. This article outlines some of the interesting project notes and summarizes End Point’s diverse skillset used for this particular website.
Initial Framework
Mobixa initially wanted a an initial proof of concept website without significant investment in development architecture because the long-term plan and success was somewhat unknown at the project unset. The initial framework comprised of basic HTML combined with a bit of logic driven by PHP. After a user submitted their phone information, data was sent to Wufoo via a Wufoo provided PHP-based API, and data was further handled from Wufoo. Wufoo is an online form builder that has nice export capabilities, and painlessly integrates with MailChimp.
This initial architecture was suitable for collecting user information, having minimal local …
clients php rails case-study
Slash URL

By Jeff Boes
December 4, 2012
There’s always more to learn in this job. Today I learned that Apache web server is smarter than me.
A typical SEO-friendly solution to Interchange pre-defined searches (item categories, manufacturer lists, etc.) is to put together a URL that includes the search parameter, but looks like a hierarchical URL:
/accessories/Mens-Briefs.html
/manufacturer/Hanes.html
Through the magic of actionmaps, we can serve up a search results page that looks for products which match on the “accessories” or “manufacturer” field. The problem comes when a less-savvy person adds a field value that includes a slash:
accessories: “Socks/Hosiery”
or
manufacturer: “Disney/Pixar”
Within my actionmap Perl code, I wanted to redirect some URLs to the canonical actionmap page (because we were trying to short-circuit a crazy Web spider, but that’s beside the point). So I ended up (after several wild goose chases) with:
my $new_path = '/accessories/' .
Vend::Tags->filter({body => (join '%2f' => (grep { /\D/ } @path)),
op => 'urlencode', }) .
'.html';By this I mean: I put together my path out of …
apache interchange perl seo
Rails: Devise and Email Capitalization
By Steph Skardal
November 30, 2012
This week, I found a bug for one of our Rails clients that was worth a quick blog post. The client website runs on Rails 3.2.8 with ActiveRecord and PostgreSQL, uses RailsAdmin for an admin interface, Devise for user authentication, and CanCan for user authorization. Before we found the bug, our code looked something like this:
class SomeController < ApplicationController
def some_method
user = User.find_or_create_by_email(params[:email])
# do some stuff with the user provided parameters
if user.save
render :json => {}
else
render :json => {}, :status => 500
end
end
endIt’s important to note that the 500 error wasn’t reported to the website visitor — there were no visible UI notes to indicate the process had failed. But besides that, this code looks sane, right? We are looking up or creating a user from the provided email, updating the user parameters, and then attempting to save. For the most part, this worked fine, until we came across a situation where the user data was not getting updated properly.
Looking through the logs, I found that the user experiencing the bug was entering mixed caps emails, for example, …
rails
Detecting table rewrites with the ctid column

By Greg Sabino Mullane
November 26, 2012

In a recent article, I mentioned that changing the column definition of a Postgres table will sometimes cause a full table rewrite, but sometimes it will not. The rewrite depends on both the nature of the change and the version of Postgres you are using. So how can you tell for sure if changing a large table will do a rewrite or not? I’ll show one method using the internal system column ctid.
Naturally, you do not want to perform this test using your actual table. In this example, we will create a simple dummy table. As long as the column types are the same as your real table, you can determine if the change will do a table rewrite on your version of PostgreSQL.
The aforementioned ctid column represents the physical location of the table’s row on disk. This is one of the rare cases in which this column can be useful. The ctid value consists of two numbers: the first is the “page” that the row resides in, and the second number is the slot in that page where it resides. To make things confusing, the page numbering starts at 0, while the slot starts at 1, which is why the very first row is always at ctid (0,1). However, the only important …
database postgres
Job Opening: DevOps Engineer

By Jon Jensen
November 22, 2012
This position has been filled. See our active job listings here.
We’re looking for a full-time, salaried DevOps engineer to work with our existing hosting and system administration team and consult with our clients on their needs. If you like to figure out problems, solve them, can take responsibility for getting a job done well without intensive oversight, please read on!
What is in it for you?
- Work from your home office
- Flexible full-time work hours
- Health insurance benefit
- 401(k) retirement savings plan
- Annual bonus opportunity
- Ability to move without being tied to your job location
What you will be doing:
- Remotely set up and maintain Linux servers (mostly RHEL/CentOS, Debian, and Ubuntu), daemons, and custom software written mostly in Ruby, Python, Perl, and PHP
- Audit and improve security, reliability, backups, monitoring (with Nagios etc.)
- Support developer use of major language ecosystems: Perl’s CPAN, Python PyPI (pip/easy_install), Ruby gems, PHP PEAR/PECL, etc.
- Automate provisioning with Chef, Puppet, etc.
- Work with internal and customer systems and staff
- Use open source tools and contribute back as opportunity arises
- Use your desktop platform of choice: Linux, Mac OS X, Windows
What you will need:
- Professional …
hosting jobs-closed
PostgreSQL search_path Behaviour

By Szymon Lipiński
November 15, 2012
PostgreSQL has a great feature: schemas. So you have one database with multiple schemas. This is a really great solution for the data separation between different applications. Each of them can use different schema, and they also can share some schemas between them.
I have noticed that some programmers tend to name the working schema as their user name. This is not a bad idea, however once I had a strange behaviour with such a solution.
I’m using user name szymon in the database szymon.
First let’s create a simple table and add some values. I will add one row with information about the table name.
# CREATE TABLE a (t TEXT);
# INSERT INTO a(t) VALUES ('This is table a');Let’s check if the row is where it should be:
# SELECT t FROM a;
t
-----------------
This is table a
(1 row)Now let’s create another schema and name it like my user’s name.
# CREATE SCHEMA szymon;Let’s now create table a in the new schema.
# CREATE TABLE szymon.a (t TEXT);So now there are two tables a in different schemas:
# SELECT t FROM pg_tables WHERE tablename = 'a';
schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | …postgres