End Point’s 20th anniversary meeting

By Phineas Jensen
October 23, 2015
End Point held a company-wide meeting at our New York City headquarters for two days on October 1 and 2. We had an excellent two days of presentations, discussions, and socializing with each other.
In addition to our main Manhattan office we have an office in Tennessee, and many of us work throughout the world from home offices. Because of this, we usually work together through text chat, phone, video call, and other remote means. Everyone traveling to New York City for this gathering was a great chance to get to know each other more personally.
The meeting itself was prefaced by a meetup at the Metropolitan Museum of Art, which turned out to be an fun game of hide-and-seek, trying to find each other throughout the museum’s exhibits.

We’re 20 years old!
This gathering was a special occasion because this year we are celebrating our 20th anniversary as a company! Day one of our meetings began with introductory comments by End Point’s founders, Rick Peltzman, CEO, and Ben Goldstein, President. Together with Jon Jensen, CTO, they took a look back at where we’ve been, where we are now, and where we’re going.
Rick had this message for our clients and friends in August, the month the …
company conference remote-work clients
MediaWiki extension.json change in 1.25

By Greg Sabino Mullane
October 17, 2015
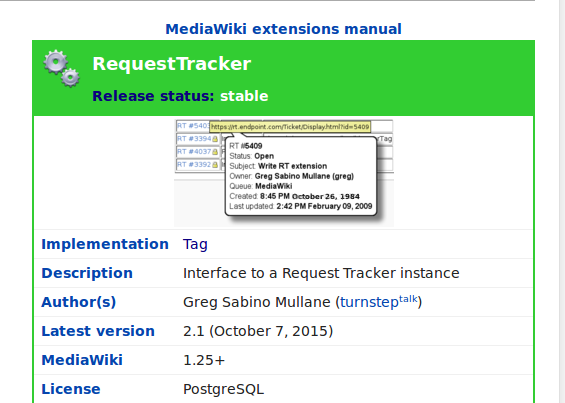
I recently released a new version of the MediaWiki “Request Tracker” extension, which provides a nice interface to your RequestTracker instance, allowing you to view the tickets right inside of your wiki. There are two major changes I want to point out. First, the name has changed from “RT” to “RequestTracker”. Second, it is using the brand-new way of writing MediaWiki extensions, featuring the extension.json file.
The name change rationale is easy to understand: I wanted it to be more intuitive and easier to find. A search for “RT” on mediawiki.org ends up finding references to the WikiMedia RequestTracker system, while a search for “RequestTracker” finds the new extension right away. Also, the name was too short and failed to indicate to people what it was. The “rt” tag used by the extension stays the same. However, to produce a table showing all open tickets for user “alois”, you still write:
<rt u='alois'></rt>The other major change was to modernize it. As of version 1.25 of MediaWiki, extensions are encouraged to use a new system to register themselves with MediaWiki. Previously, an extension would have a PHP file named after the extension that was …
json mediawiki extensions
Int’l — JavaScript numbers and dates formatting, smart strings comparison

By Piotr Hankiewicz
October 16, 2015

Introduction
WARNING — At the time of writing this text all of the things mentioned below are not yet supported by Safari and most of the mobile browsers.
It’s almost three years now since Ecma International published the 1st version of “ECMAScript Internationalization API Specification”. It’s widely supported by most of the browsers now. A new object called Intl has been introduced. Let’s see what it can do.
To make it easier imagine that we have a banking system with a possibility of having accounts in multiple currencies. Our user is Mr. White, a rich guy.
Intl powers
Number formatting
Mr. White has four accounts with four different currencies: British pound, Japanese yen, Swiss franc, Moroccan dirham. If we want to have a list of current balances, with a correct currency symbols, it’s pretty simple:
// locales and balances object
var accounts = [
{
locale: 'en-GB',
balance: 165464345,
currency: 'GBP'
},
{
locale: 'ja-JP',
balance: 664345,
currency: 'JPY'
},
{
locale: 'fr-CH',
balance: 904345,
currency: 'CHE'
},
{
locale: …html javascript
Intro to DimpleJS, Graphing in 6 Easy Steps

By Matt Galvin
October 15, 2015
Data Visualization is a big topic these days given the giant amount of data being collected. So, graphing this data has been important in order to easily understand what has been collected. Of course there are many tools available for this purpose but one of the more popular choices is D3.
D3 is very versatile but can be a little more complicated than necessary for simple graphing. So, what if you just want to quickly spin up some graphs quickly? I was recently working on a project where we were trying to do just that. That is when I was introduced to DimpleJS.
The advantage of using DimpleJS rather than plain D3 is speed. It allows you to quickly create customizable graphs with your data, gives you easy access to D3 objects, is intuitive to code, and I’ve found the creator John Kiernander to be very responsive on Stack Overflow when I ran in to issues.
I was really impressed with how flexible DimpleJS is. You can make a very large variety of graphs quickly and easily. You can update the labels on the graph and on the axes, you can create your own tooltips, add colors and animations, etc..
I thought I’d make a quick example to show just how easy it is to start graphing.
Step 1 …
visualization javascript
DevOpsDays India — 2015

By Selvakumar Arumugam
September 30, 2015
DevOpsIndia 2015 was held at The Royal Orchid in Bengaluru on Sep 12-13, 2015. After saying hello to a few familiar faces who I often see at the conferences, I collected some goodies and entered into the hall. Everything was set up for the talks. Niranjan Paranjape, one of the organizers, was giving the introduction and overview of the conference.

Justin Arbuckle from Chef gave a wonderful keynote talk about the “Hedgehog Concept” and spoke more about the importance of consistency, scale and velocity in software development.
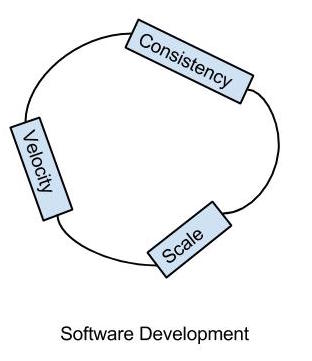
In addition, he quoted “A small team with generalists who have a specialization, deliver far more than a large team of single skilled people.”
A talk on “DevOps of Big Data infrastructure at scale” was given by Rajat Venkatesh from Qubole. He explained the architecture of Qubole Data Service (QDS), which helps to autoscale the Hadoop cluster. In short, scale up happens based on the data from Hadoop Job Tracker about the number of jobs running and time to complete the jobs. Scale down will be done by decommissioning the node, and the server will be chosen by which is reaching the boundary of an hour. This is because most of the cloud service providers charge …
automation conference devops containers docker
Pgbouncer user and database pool_mode with Scaleway
By Greg Sabino Mullane
September 24, 2015

The recent release of PgBouncer 1.6, a connection pooler for Postgres, brought a number of new features. The two I want to demonstrate today are the per-database and per-use pool_modes. To get this effect previously, one had to run separate instances of PgBouncer. As we shall see, a single instance can now run different pool_modes seamlessly.
There are three pool modes available in PgBouncer, representing how aggressive the pooling becomes: session mode, transaction mode, and statement mode.
Session pool mode is the default, and simply allows you to avoid the startup costs for new connections. PgBouncer connects to Postgres, keeps the connection open, and hands it off to clients connecting to PgBouncer. This handoff is faster than connecting to Postgres itself, as no new backends need to be spawned. However, it offers no other benefits, and many clients/applications already do their own connection pooling, making this the least useful pool mode.
Transaction pool mode is probably the most useful one. It works by keeping a client attached to the same Postgres backend for the duration of a transaction only. In this way, many clients can share the same …
cloud database postgres scalability
YAPC::NA 2015 Conference Report

By Josh Lavin
September 18, 2015
In June, I attended the Yet Another Perl Conference (North America), held in Salt Lake City, Utah. I was able to take in a training day on Moose, as well as the full 3-day conference.
The Moose Master Class (slides and exercises here) was taught by Dave Rolsky (a Moose core developer), and was a full day of hands-on training and exercises in the Moose object-oriented system for Perl 5. I’ve been experimenting a bit this year with the related project Moo (essentially the best two-thirds of Moose, with quicker startup), and most of the concepts carry over, with just slight differences.
Moose and Moo allow the modern Perl developer to quickly write OO Perl code, saving quite a bit of work from the older “classic” methods of writing OO Perl. Some of the highlights of the Moose class include:
- Sub-classing is discouraged; this is better done using Roles
- Moose eliminates more typing; more typing can often equal more bugs
- Using namespace::autoclean at the top is a best practice, as it cleans up after Moose
- Roles are what a class does, not what it is. Roles add functionality.
- Use types with MooseX::Types or Type::Tiny (for Moo)
- Attributes can be objects (see slide 231)
Additional helpful …
conference perl
Install Tested Packages on Production Server
By Selvakumar Arumugam
September 7, 2015
One of our customers has us to do scheduled monthly OS updates following a specific rollout process. First week of the month, we will update the test server and wait for a week to confirm that everything looks as expected in the application; then next week we apply the very same updates to the production servers.
Since not long ago we used to use aptitude to perform system updates. While doing the update on the test server, we also executed aptitude on production servers to “freeze” the same packages and version to be updated on following week. That helped to ensure that only tested packages would have been updated on the production servers afterward.
Since using aptitude in that way wasn’t particularly efficient, we decided to use directly apt-get to stick with our standard server update process. We still wanted to keep our test-production synced updated process cause software updates released between the test and the production server update are untested in the customer specific environment. Thus we needed to find a method to filter out the unneeded packages for the production server update.
In order to do so we have developed a shell script that automates the process and …
automation linux sysadmin ubuntu update