Introducing Piggybak: A Mountable Ruby on Rails Ecommerce Engine

By Steph Skardal
January 6, 2012
Here at End Point, we work with a variety of open source solutions, both full-fledged ecommerce applications and smaller modular tools. In our work with open source ecommerce applications, we spend a significant amount of time building out custom features, whether that means developing custom shipping calculations, product personalization, accounting integration or custom inventory management.
There are advantages to working with a full-featured ecommerce platform. If you are starting from scratch, a full-featured platform can be a tool to quickly get product out the door and money in your pocket. But to do this, you must accept the assumptions that the application makes. And most generic, monolithic ecommerce platforms are created to satisfy many users.
Working with a large monolithic ecommerce platform has disadvantages, too:
- Sometimes over-generic-izing a platform to satisfy the needs of many comes at the cost of code complexity, performance, or difficulty in customization.
- Occasionally, the marketing of an ecommerce solution overpromises and underdelivers, leaving users with unrealistic expectations on what they get out of the box.
- Customization on any of these platforms is …
ecommerce piggybak rails
Ruby on Rails: Attributes Management through Rights
By Steph Skardal
January 5, 2012
I’ve written a couple times about a large Rails project that a few End Pointers have been working on. The system has a fairly robust system for managing rights and access. The basic data model for rights, users, groups, and roles is this:
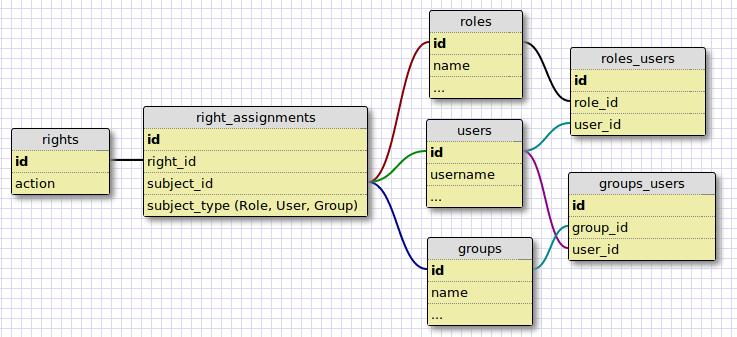
In this data model, right_assignments belong to a single right, and belong to a subject, through a polymorphic relationship. The subject can be a Role, Group, or User. A User can have a role or belong to a group. This allows for the ability to assign a right to a user directly or through a group or role.
In our code, there is a simple method for grabbing a user’s set of rights:
class User < ActiveRecord::Base
...
def all_rights
rights = [self.rights +
self.groups.collect { |g| g.allowed_rights } +
self.roles.collect { |r| r.rights }]
rights = rights.flatten.uniq.collect { |r| r.action }
rights
end
...
endIn the case of this data model, groups also have a boolean which specifies whether or not rights can be assigned to them. The allowed_rights method looks like this:
class Group < ActiveRecord::Base
...
def allowed_rights
self.assignable_rights ? self …rails
Some great press for College District

By Ron Phipps
January 5, 2012
College District has been getting some positive press lately, the most recent being a Forbes article which talks about the success they have been seeing in the last few years.
College District is a company that sells collegiate merchandise to fans. They got their start focusing on the LSU Tigers at TigerDistrict.com and have branched out to teams such as the Oregon Ducks and Alabama Roll Tide.
We’ve been working with Jared Loftus at College District for over four years. College District is running on a heavily modified Interchange system with some cool Postgres tricks. The system can support a nearly unlimited number of sites, running on 2 catalogs (1 for the admin, 1 for the front end) and 1 database. The key to the system is different schemas, fronted by views, that hide and expose records based on the database user that is connected. The great thing about this system is that Jared can choose to launch a new store within a day and be ready for sales, something he has taken advantage of in the past when a team is on fire and he sees an opportunity he can’t pass up.
We are currently preparing for a re-launch of the College District site that will focus on crowd-sourced designs. …
database ecommerce hosting interchange postgres clients
Automating removal of SSH key patterns

By Brian Buchalter
January 3, 2012
Every now and again, it becomes necessary to remove a user’s SSH key from a system. At End Point, we’ll often allow multiple developers into multiple user accounts, so cleaning up these keys can be cumbersome. I decided to write a shell script to brush up on those skills, make sure I completed my task comprehensively, and automate future work.
Initial Design and Dependencies
My plan for this script is to accept a single argument which would be used to search the system’s authorized_keys files. If the pattern was found, it would offer you the opportunity to delete the line of the file on which the pattern was found.
I’ve always found mlocate to be very helpful; it makes finding files extremely fast and its usage is trivial. For this script, we’ll use the output from locate to find all authorized_keys files in the system. Of course, we’ll want to make sure that the mlocate.db has recently been updated. So let’s show the user when the database was last updated and offer them a chance to update it.
mlocate_path="/var/lib/mlocate/mlocate.db"
if [ -r $mlocate_path ]
then
echo -n "mlocate database last updated: "
stat -c %y $mlocate_path
echo -n "Do you …hosting tools
Interchange Search Caching with “Permanent More”

By Mark Johnson
January 2, 2012
Most sites that use Interchange take advantage of Interchange’s “more lists”. These are built-in tools that support an Interchange “search” (either the search/scan action, or result of direct SQL via [query]) to make it very easy to paginate results. Under the hood, the more list is a drill-in to a cached “search object”, so each page brings back a slice from the cache of the original search. There are extensive ways to modify the look and behavior of more lists and, with a bit of effort, they can be configured to meet design requirements.
Where more lists tend to fall short, however, is with respect to SEO. There are two primary SEO deficiencies that get business stakeholders’ attention:
- There is little control over the construction of the URLs for more lists. They leverage the scan actionmap and contain a hash key for the search object and numeric data to identify the slice and page location. They possess no intrinsic value in identifying the content they reference.
- The search cache by default is ephemeral and session-specific. This means all those results beyond page 1 the search engine has cataloged will result in dead links for search users who try to land directly on the …
database interchange optimization performance scalability search seo
Importing Comments into Disqus using Rails
By Brian Buchalter
December 27, 2011
It seems everything is going to the cloud, even comment systems for blogs. Disqus is a platform for offloading the ever growing feature set users expect from commenting systems. Their website boasts over a million sites using their platform and offers a robust feature set and good performance. But before you can drink the Kool-Aid, you’ve got to get your data into their system.
If you’re using one of the common blog platforms such as WordPress or Blogger, there are fairly direct routes Disqus makes available for automatically importing your existing comment content. For those with an unsupported platform or a hand-rolled blog, you are left with exporting your comments into XML using WordPress’s WXR standard.
Disqus leaves a lot up to the exporter, providing only one page in there knowledge base for using what they describe as a Custom XML Import Format. In my experience the import error messages were cryptic and my email support request is still unanswered 5 days later. (Ok, so it was Christmas weekend!)
So let’s get into the nitty gritty details. First, the sample code provided in this article is based on Rails 3.0.x, but should work with Rails 3.1.x as well. Rails 2.x …
ruby rails
Labeling input boxes including passwords
By Ron Phipps
December 23, 2011
I’m currently working on a new site and one of the design aspects of the site is many of the form fields do not have labels near the input boxes, they utilize labels that are inside the input box and fade away when text is entered. The label is also supposed to reappear if the box is cleared out. Originally I thought this was a pretty easy problem and wrote out some jQuery to do this quickly. The path I went down first was to set the textbox to the value we wanted displayed and then clear it on focus. This worked fine, however I reached a stumbling block when it came to password input boxes. My solution did not work properly because text in a password box is hidden and the label would be hidden as well. Most people would probably understand what went in each box, but I didn’t want to risk confusing anyone, so I needed to find a better solution
I did some searching for jQuery and labels for password inputs and turned up several solutions. The first one actually put another text box on top of the password input, but that seemed prone to issue. The solution I decided to ultimately use is called In-Fields Labels, a jQuery plugin by Doug Neiner. In this solution Doug has floating labels …
javascript jquery tips tools
Converting CentOS 6 to RHEL 6

By Jon Jensen
December 22, 2011
A few years ago I needed to convert a Red Hat Enterprise Linux (RHEL) 5 development system to CentOS 5, as our customer did not actively use the system any more and no longer wanted to renew the Red Hat Network entitlement for it. Making the conversion was surprisingly straightforward.
This week I needed to make a conversion in the opposite direction: from CentOS 6 to RHEL 6. I didn’t find any instructions on doing so, but found a RHEL 6 to CentOS 6 conversion guide with roughly these steps:
yum clean all
mkdir centos
cd centos
wget http://mirror.centos.org/centos/6.0/os/x86_64/RPM-GPG-KEY-CentOS-6
wget http://mirror.centos.org/centos/6.0/os/x86_64/Packages/centos-release-6-0.el6.centos.5.x86_64.rpm
wget http://mirror.centos.org/centos/6.0/os/x86_64/Packages/yum-3.2.27-14.el6.centos.noarch.rpm
wget http://mirror.centos.org/centos/6.0/os/x86_64/Packages/yum-utils-1.1.26-11.el6.noarch.rpm
wget http://mirror.centos.org/centos/6.0/os/x86_64/Packages/yum-plugin-fastestmirror-1.1.26-11.el6.noarch.rpm
rpm --import RPM-GPG-KEY-CentOS-6
rpm -e --nodeps redhat-release-server
rpm -e yum-rhn-plugin rhn-check rhnsd rhn-setup rhn-setup-gnome
rpm -Uhv --force *.rpm
yum upgradeI then put …
hosting open-source redhat sysadmin tips