Rails Optimization: Digging Deeper

By Steph Skardal
August 5, 2011
I recently wrote about raw caching performance in Rails and advanced Rails performance techniques. In the latter article, I explained how to use a Rails low-level cache to store lists of things during the index or list request. This technique works well for list pages, but it doesn’t necessarily apply to requests to an individual thing, or what is commonly referred to as the “show” action in Rails applications.
In my application, the “show” action loaded at ~200 ms/request with low concurrency, with the use of Rails fragment caching. And with high concurrency, the requests shot up to around 2000 ms/request. This wasn’t cutting it! So, I pursued implementing full-page caching with a follow-up AJAX request, outlined by this diagram:
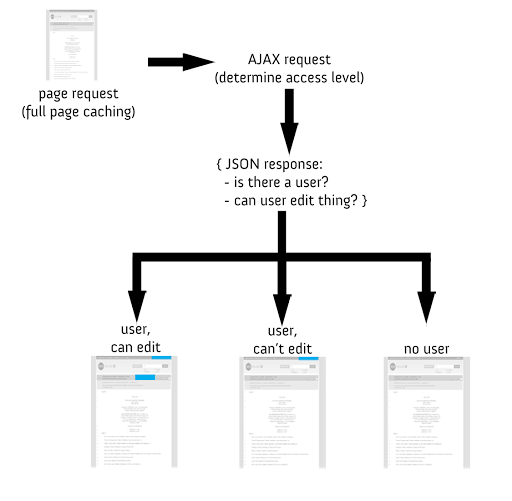
First, the fully-cached is loaded (quickly). Next, an AJAX request is made to retrieve access information. The access information returns a JSON object with information on whether or not there is a user, and if that user has edit access to that thing. If there is no user, the page stays as is. If there is a user, but he does not have edit permissions, the log out button is shown and the username is populated. If there is a user and he has edit …
javascript performance rails
DevCamps news

By Jon Jensen
August 4, 2011
DevCamps is a system for managing development, integration, staging, and production environments. It was developed by End Point for, and with the help of, some of our ecommerce clients. It grew over the space of several years, and really started to become its own standalone project in 2007.
Camps are a behind-the-scenes workhorse of our web application development at End Point, and don’t always get much attention because everyone’s too busy using camps to get work done! But this summer a few things are happening.
In early July we unveiled a redesign of the devcamps.org website that features a more whimsical look, a better explanation of what camps are all about, and endorsements by business and developer users. Marko Bijelic of Hipinspire did the design. Take a look:
In less than two weeks, on August 17, I’m going to be giving a talk on camps at YAPC::EU in Riga, Latvia. YAPC::EU is Europe’s annual Perl conference, and will be a nice place to talk about camps.
Many Perl developers are doing web applications, which is camps’ main focus, so that’s reason enough. But camps also started around the Interchange application server, which is written in Perl. And the camp …
camps conference perl open-source
Debian Postgres readline psql problem and the solutions

By Greg Sabino Mullane
August 2, 2011

There was a bit of a controversy back in February as Debian decided to replace libreadline with libedit, which affected a number of apps, the most important of which for Postgres people is the psql utility. They did this because psql links to both OpenSSL and readline, and although psql is compatible with both, they are not compatible with each other!
By compatible, I mean that the licenses they use (OpenSSL and readline) are not, in one strict interpretation, allowed to be used together. Debian attempts to live by the letter and spirit of the law as close as possible, and thus determined that they could not bundle both together. Interestingly, Red Hat does still ship psql using OpenSSL and readline; apparently their lawyers reached a different conclusion. Or perhaps they, as a business, are being more pragmatic than strictly legal, as it’s very unlikely there would be any consequence for violating the licenses in this way.
While libreadline (the library for GNU readline) is a feature rich, standard, mature, and widely used library, libedit (sadly) is not as developed and has some important bugs and shortcomings (including no home page, apparently, and no Wikipedia page!). This …
open-source postgres
Cuenca, Ecuador

By Benjamin Goldstein
July 28, 2011
Given that End Point uses a distributed office structure and that I do almost all of my work online, in theory I should be able to work just about anywhere there’s a good Internet connection. That sounds neat, but is it in fact true? Well, earlier this year I put the theory to a serious test. By nature I’m not all that adventurous a traveller, but my wife is, and she’s fluent in Spanish. Our teenage sons are going to be grown men all too soon, so if we were ever to take the plunge into living abroad as a family, I realized it was now or never.
In looking for a place to go we had some criteria:
- a safe place in Latin America without an excess of walls
- good or at least reasonable Internet connectivity
- soccer training for our 15-year-old
- high school in Spanish for our 16-year-old.
We are very lucky that my friend Tovias suggested his home town (more or less) and volunteered his family to look after us there!
So, in February I picked up and relocated with my family to Cuenca, Ecuador, for just over three months. I worked. My wife, Gina, homeschooled one of our sons, and generally kept us all going in this beautiful and historical city.
company travel remote-work
Company Presentation: jQuery and Rails
By Steph Skardal
July 27, 2011
Yesterday, I gave a company presentation on jQuery and Rails. The talk covered details on how jQuery and Rails work together to build rich web applications, with a considerable amount of focus on AJAX methods. Check out the slides here:
One piece of knowledge I took away from the talk is how different the Rails 3 approach is for unobtrusive AJAX behavior using helpers like link_to_remote and remote_form_for. Mike Farmer made a recommendation to read the rails.js source here to see how onclick behavior is handled in Rails 3.
javascript jquery ruby rails
Rails Optimization: Advanced Techniques with Solr
By Steph Skardal
July 22, 2011
Recently, I’ve been involved in optimization on a Rails 2.3 application. The application had pre-existing fragment caches throughout the views with the use of Rails sweepers. Fragment caches are used throughout the site (rather than action or page caches) because the application has a fairly complex role management system that manages edit access at the instance, class, and site level. In addition to server-side optimization with more fragment caching and query clean-up, I did significant asset-related optimization including extensive use of CSS sprites, combining JavaScript and CSS requests where ever applicable, and optimizing images with tools like pngcrush and jpegtran. Unfortunately, even with the server-side and client-side optimization, my response times were still sluggish, and the server response was the most time consuming part of the request for a certain type of page that’s expected to be hit frequently:
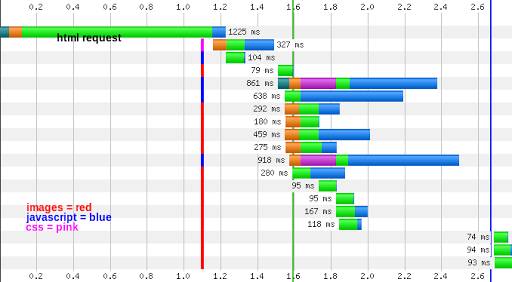
A first stop in optimization was to investigate if memcached would speed up the site, described in this article Unfortunately, that did not improve the speed much.
Next, I re-examined the debug log to see what was taking so much time. The debug log looked like this …
performance ruby rails solr sunspot
Announcing pg_blockinfo!

By David Christensen
July 14, 2011
I’m pleased to announce the initial release of pg_blockinfo. It is a tool to examine your PostgreSQL heap data files, written in Perl.
Similar in purpose to pg_filedump, it is used to display (and soon validate) buffer-page-level information for PostgreSQL page/heap files.
pg_blockinfo aims to work in a portable and non-destructive way, using read-only “mmap”, sys-level IO functions, and “unpack” in order to minimize any Perl overhead.
What we buy for the compromise of writing this in Perl instead of C is two-fold:
-
portability/low impact — pg_blockinfo has no other dependencies than Perl and several core Perl modules and will work in environments where you can’t or won’t easily install other packages or compile based on specific headers.
-
expressibility — while not currently supported in full, one of pg_blockinfo’s future goals is to allow you to specify criteria for display of both page-level and tuple-level info. It will allow you to define arbitrary Perl expressions to filter the objects you’re looking at (i.e., pages, tuples, etc; think “grep” but on a tuple level). It will support a DSL for querying based off of the named fields as well as allow you to supply arbitrary Perl …
database postgres tools
Raw Caching Performance in Ruby/Rails
By Steph Skardal
July 12, 2011
Last week, I set up memcached with a Rails application in hopes of further improving performance after getting a recommendation to pursue it. We’re already using many Rails low-level caches and fragment caches throughout the application because of its complex role management system. Those are stored in NFS on a NetApp filer, and I was hoping switching to memcached would speed things up. Unfortunately, my http request performance tests (using ab) did not back this up: using file caching on NFS with the NetApp was about 20% faster than memcached from my tests.
I brought this up to Jon, who suggested we run performance tests on the caching mechanism only rather than testing caching via full http requests, given how many layers of the stack are involved and influence the overall performance number. From the console, I ran the following:
$ script/console # This app is on Rails 2.3
> require 'benchmark'
> Rails.cache.delete("test")
> Rails.cache.fetch("test") { [SomeKlass.first, SomeKlass.last] }
> # to emulate what would potentially be stored with low-level cache
> Benchmark.bm(15) { |x| x.report("times:") { 10000.times do; Rails …performance ruby rails