Vim Golf: Learning New Skills for Code Editors

By Josh Lavin
November 28, 2016

Vim is a text-based editor that has been around for 25 years. It comes pre-installed on Linux distributions, so it is a great tool for developing on servers. One of the advantages of Vim is that oft-used keystrokes can be performed without moving your hands from the keyboard (there is no mouse in Vim).
Many of the engineers here at End Point use Vim for our daily development work, and recently, a few of us got together online to try to learn some new tricks and tips from each other. Being efficient with Vim not only improves productivity, it’s a lot of fun.
Similar to playing a round of golf, we tested each other with various editing tasks, to see who could perform the task in the fewest number of keystrokes. This is known as “Vim Golf.” There is even an entire website devoted to this.
In this post, we share some of the interesting tricks that were shown, and also some links to further learning about Vim.
Tips & Tricks
- Indenting text: there are multiple ways to do this, but a few are:
- Visually-select the lines of text to indent (Ctrl v or Shift v), then > to indent, or < to outdent. Press . to perform this action again and …
vim
Connect Multiple JPA repositories using Static and Dynamic Methods

By Selvakumar Arumugam
November 16, 2016
The JPA Repository is a useful Spring Framework library that provides object-relational mapping for Java web applications to be able to connect to a wide variety of databases. Most applications need to establish a connection with one database to store and retrieve the data though sometimes there could be more than one database to read and write. There could also be some cases where the application needs to choose which database should be used dynamically, based on each request’s parameters. Let’s see how to configure and establish connections for these three cases.
1. Single Static Connection
In order to use JPA the following configurations are required to get the database connection handle and define the interface to map a database table by extending JpaRepository class.
UserRepository.java — this part of the code configures how to map the user table
package com.domain.data;
import com.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository <User, Integer> {
}persistent-context.xml — the dataSourceReadWrite bean class defines the database connection while the entityManagerFactoryReadWrite bean helps …
database java
DNS and BIND Training with MyNIC

By Muhammad Najmi bin Ahmad Zabidi
November 16, 2016
This is yet another yesteryear’s story!
I had a chance to attend a DNS/BIND training which was organized by Malaysia’s domain registry (MyNIC). The training took two days and was organized in Bangi, Selangor, Malaysia. Dated November 23 to 24, 2015, the two days’ training was packed with technical training for the Domain Name System (DNS) using BIND software. Our trainer was Mr Amir Haris, who is running his own DNS specialist company named Localhost Sendirian Berhad (Sendirian Berhad is equivalent to “Private Limited”).
Day One
For Day One, the trainer, Mr Amir Haris taught us on the theoretical details of the DNS. For a start, Mr Amir explained to us on the DNS operation, in which he explained the basic of what DNS is and the function of root servers. Later he explained further on the root servers’ functions and locations. It was the followed by the explanation of query process.

Mr Amir also explained to us the difference of DNS implementations across different operating system platforms. As for the training since we were using BIND as the name server’s software, we we exposed to the historical background of BIND.
The concept of master and slave DNS server was also being taught. …
sysadmin
Reflections on Being a Co-working Couple

By Elizabeth Garrett Christensen
November 15, 2016
Over Labor Day weekend I married another End Point employee, David Christensen. I thought I’d take a minute to reflect on life as a co-working couple. In the days before everyone worked in a mad scramble to pay off their student loans, save for their kids’ college, and save for retirement, lots of couples shared in the responsibilities of owning a business or farm. Today for most families those days are long gone and each spouse goes off to a long day at the office to meet back at home in the evening.
David and I are really fortunate to work at End Point and work remotely from our home in Lawrence, Kansas. David is a veteran at End Point starting as an application developer a decade ago and now is a project manager and heads up many of End Point’s larger sales, database, and VR projects. I am brand-new to End Point and serve as the Client Liaison doing billing, client support, sales, and project management.
 |
| Our home office in Lawrence |
What I love
Being together all the time
Like any newlywed, I cannot get enough of this guy. He’s easy to talk to, fun to be around, and pretty much makes everything better. But enough of that sappiness…
Getting some real insight on …
company remote-work
8 Simple Steps to Saner Software Development

By Dylan Wooters
November 10, 2016

While these might seem obvious for seasoned developers, many projects, especially legacy software, still fail to follow most of the steps below.
In future posts, I’ll expand on these steps and give more details. For now, here’s an overview of some basic guidelines for making the process of software development smoother (& saner) for both the client and the dev team.
Separate environments:
Ideally there should be Dev, QA, UAT/Staging, and Production environments. And, UAT/Staging should be as close to Production as possible. It’s amazing how many software projects are still done on someone’s local machine and pushed directly to Production.
Use a bug tracking tool:
This is pretty obvious. Bugs need to be logged and labeled so that they can be tracked through stages of development (i.e., To-Do, In Progress, Completed). Using a bug tracking tool like Jira or GitHub also helps the non-technical stakeholders comment on and clarify requirements/issues.
Have a source control strategy:
It doesn’t have to be fancy. For example, if you’re using Git, it should be more than having multiple developers working out of the master branch. Ideally link branches to features or bugs defined in a …
development environment devops
The Happy Path: An Interview with Design Strategist & Gallerist Kelani Nichole

By Liz Flyntz
November 9, 2016

Kelani Nichole is a digital strategist who is also a contemporary art gallerist. Or maybe vice versa.
She works with the Theresa Neil Strategy + Design agency, doing user-centered design research for (mostly) big products at big companies. Her gallery, Transfer, presents internet and computer-based artworks in its Brooklyn, NY location and as pop-up installations around the country and the world.
We spoke about design methodology, client engagement, and salad at El Rey in Manhattan. We got right into it, so don’t expect much prelude.
Kelani Nichole: Existing designs are often based on legacy, opinions, and politics. The methodology I use is all about collaborative design. It’s part of the engagement from the beginning - you get people in a room drawing pictures together. Then when it comes across their desk as we’re building it, they see their own work in what you’re building, and there’s buy in.
It’s really kind of magic the way that it works. They don’t even realize it’s happening. It’s like the film Inception.
Liz Flyntz: When you come on to a new project do you do a presentation? Or are they just buying you on reputation?
KN: No, when I do new business I’ll go pitch the …
development art architecture
Making cross-blogs queries in multi-site WordPress performant

By Kamil Ciemniewski
November 2, 2016
Some time ago I was working on customizing a WordPress system for a client. The system was running in a multi-site mode, being a host of a large number of blogs.
Because some blogs had not been updated in a long while, we wanted to pull information about recent posts from all of the blogs. This in turn was going to be used for pruning any blogs that weren’t considered “active”.
While the above description may sound simple, the scale of the system made the task a bit more involving that it would be usually.
How WordPress handles the “multi-site” scenario
The goal of computing the summary of posts for many blogs residing in the hypotethical blogging platform, in the same database doesn’t seem so complicated. Tasks like that are being performed all the time using relational databases.
The problem in WordPress arises though because of the very unusual way that it organises blogs data. Let’s see how the database tables look like in the “normal” mode first:
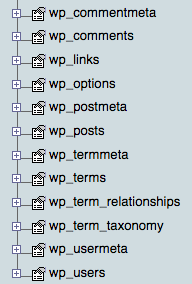
It has a number of tables that start with user configurable prefix. In the case of the screenshot above, the prefix was wp_.
We can see there’s a wp_posts table which contains rows related to blog posts. Thinking about …
database mysql php extensions wordpress
Postgres connection service file

By Greg Sabino Mullane
October 26, 2016

Postgres has a wonderfully helpful (but often overlooked) feature called the connection service file (its documentation is quite sparse). In a nutshell, it defines connection aliases you can use from any client. These connections are given simple names, which then map behind the scenes to specific connection parameters, such as host name, Postgres port, username, database name, and many others. This can be an extraordinarily useful feature to have.
The connection service file is named pg_service.conf and is setup in a known location. The entries inside are in the common “INI file” format: a named section, followed by its related entries below it, one per line. To access a named section, just use the service=name string in your application.
## Find the file to access by doing:
$ echo `pg_config --sysconfdir`/pg_service.conf
## Edit the file and add a sections that look like this:
[foobar]
host=ec2-76-113-77-116.compute-2.amazonaws.com
port=8450
user=hammond
dbname=northridge
## Now you can access this database via psql:
$ psql service=foobar
## Or in your Perl code:
my $dbh = DBI->connect('dbi:Pg:service=foobar');
## Other libpq …postgres