Postgres checksum performance impact

By Greg Sabino Mullane
December 31, 2015

Way back in 2013, Postgres introduced a feature known as data checksums. When this is enabled, a small integer checksum is written to each “page” of data that Postgres stores on your hard drive. Upon reading that block, the checksum value is recomputed and compared to the stored one. This detects data corruption, which (without checksums) could be silently lurking in your database for a long time. We highly recommend to our Postgres clients to turn checksums on; hopefully this feature will be enabled by default in future versions of Postgres.
However, because TANSTAAFL (there ain’t no such thing as a free lunch), enabling checksums does have a performance penalty. Basically, a little bit more CPU is needed to compute the checksums. Because the computation is fast, and very minimal compared to I/O considerations, the performance hit for typical databases is very small indeed, often less than 2%. Measuring the exact performance hit of checksums can be a surprisingly tricky problem.
There are many factors that influence how much slower things are when checksums are enabled, including:
- How likely things are to be read from shared_buffers, which depends on how large shared_buffers is set, and how much of your active database fits inside of it
- How fast your server is in general, and how well it (and your compiler) are able to optimize the checksum calculation
- How many data pages you have (which can be influenced by your data types)
- How often you are writing new pages (via COPY, INSERT, or UPDATE)
- How often you are reading values (via SELECT)
Enough of the theory, let’s see checksums in action. The goal is that even a single changed bit anywhere in your data will produce an error, thanks to the checksum. For this example, we will use a fresh 9.4 database, and set it up with checksums:
~$ cd ~/pg/9.4
~/pg/9.4$ bin/initdb --data-checksums lotus
The files belonging to this database system will be owned by user "greg".
...
Data page checksums are enabled.
...
~/pg/9.4$ echo port=5594 >> lotus/postgresql.conf
~/pg/9.4$ bin/pg_ctl start -D lotus -l lotus.log
server starting
~/pg/9.4$ bin/createdb -p 5594 testdbFor testing, we will use a table with a single char(2000) data type. This ensures that we have a relatively high number of pages compared to the number of rows (smaller data types means more rows shoved into each page, while higher types also mean less pages, as the rows are TOASTed out). The data type will be important for our performance tests later on, but for now, we just need a single row:
~/pg/9.4$ psql testdb -p 5594 -c "create table foobar as select 'abcd'::char(2000) as baz"
SELECT 1Finally, we will modify the data page on disk using sed, then ask Postgres to display the data, which should cause the checksum to fail and send up an alarm. (Unlike my coworker Josh’s checksum post, I will change the actual checksum and not the data, but the principle is the same).
~/pg/9.4$ export P=5594
## Find the actual on-disk file holding our table, and store it in $D
~/pg/9.4$ export D=`psql testdb -p$P -Atc "select setting || '/' || pg_relation_filepath('foobar') from pg_settings where name ~ 'data_directory'"`
~/pg/9.4$ echo $D
/home/greg/pg/9.4/lotus/base/16384/16385
## The checksum is stored at the front of the header: in this case it is: 41 47
~/pg/9.4$ hexdump -C $D | head -1
00000000 00 00 00 00 00 00 00 00 41 47 00 00 1c 00 10 18 |........AG......|
## Use sed to change the checksum in place, then double check the result
~/pg/9.4$ LC_ALL=C sed -r -i "s/(.{8})../\1NI/" $D
~/pg/9.4$ hexdump -C $D | head -1
00000000 00 00 00 00 00 00 00 00 4E 49 00 00 1c 00 10 18 |........NI......|
~/pg/9.4$ psql testdb -p$P -tc 'select rtrim(baz) from foobar'
abcdHmmm…why did this not work? Because of the big wrinkle to testing performance, shared buffers. This is a special shared memory segment used by Postgres to cache data pages. So when we asked Postgres for the value in the table, it pulled it from shared buffers, which does not get a checksum validation. Our changes are completely overwritten as the row leaves shared buffers and heads back to disk, generating a new checksum:
~/pg/9.4$ psql testdb -p$P -tc 'checkpoint'
CHECKPOINT
~/pg/9.4$ hexdump -C $D | head -1
00000000 00 00 00 00 80 17 c2 01 7f 19 00 00 1c 00 10 18 |................|How can we trigger a checksum warning? We need to get that row out of shared buffers. The quickest way to do so in this test scenario is to restart the database, then make sure we do not even look at (e.g. SELECT) the table before we make our on-disk modification. Once that is done, the checksum will fail and we will, as expected, receive a checksum error:
~/pg/9.4$ bin/pg_ctl restart -D lotus -l lotus.log
waiting for server to shut down.... done
server stopped
server starting
~/pg/9.4$ LC_ALL=C sed -r -i "s/(.{8})../\1NI/" $D
~/pg/9.4$ psql testdb -p$P -tc 'select rtrim(baz) from foobar'
WARNING: page verification failed, calculated checksum 6527 but expected 18766
ERROR: invalid page in block 0 of relation base/16384/16385The more that shared buffers are used (and using them efficiently is a good general goal), the less checksumming is done, and the less the impact of checksums on database performance will be. Because we want to see the “worst-case” scenario when doing performance testing, let’s create a second Postgres cluster, with a teeny-tiny shared buffers. This will increase the chances that any reads come not from shared buffers, but from the disk (or more likely the OS cache, but we shall gloss over that for now).
To perform some quick performance testing on writes, let’s do a large insert, which will write many pages to disk. I originally used pg_bench for these tests, but found it was doing too much SQL under the hood and creating results that varied too much from run to run. So after creating a second cluster with checksums disabled, and after adjusting both with “shared_buffers = 128kBv”, I created a test script that inserted many rows into the char(2000) table above, which generated a new data page (and thus computed a checksum for the one cluster) once every four rows. I also did some heavy selects of the same table on both clusters.
Rather than boring you with large charts of numbers, I will give you the summary. For inserts, the average difference was 6%. For selects, that jumps to 19%. But before you panic, remember that this tests are with a purposefully crippled Postgres database, doing worst-case scenario runs. When shared_buffers was raised to a sane setting, the statistical difference between checksums and not-checksums disappeared.
In addition to this being an unrealistic worst-case scenario, I promise that you would be hard pressed to find a server to run Postgres on with a slower CPU than the laptop I ran these tests on. :) The actual calculation is pretty simple and uses a fast Fowler/Noll/Vo hash—see the src/include/storage/checksum_impl.h file. The calculation used is:
hash = (hash ^ value) * FNV_PRIME ^ ((hash ^ value) >> 17)Can you handle the performance hit? Here’s a little more incentive for you: if you are doing this as part of a major upgrade (a common time to do so, as part of a pg_dump oldversion | psql newversion process), then you are already getting performance boosts from the new version. Which can nicely balance out (or at least mitigate) your performance hit from enabling checksums! Look how much speedup you get doing basic inserts just leaving the 8.x series:
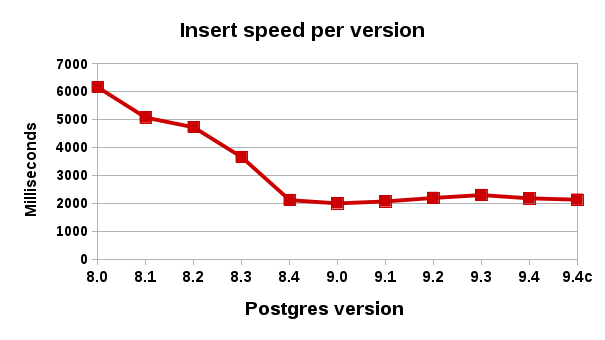
It is very hard to hazard any number for the impact of checksums, as it depends on so many factors, but for a rough ballpark, I would say a typical database might see a one or two percent difference. Higher if you are doing insane amounts of inserts and updates, and higher if your database doesn’t fit at all into shared buffers. All in all, a worthy trade-off. If you want some precise performance impact figures, you will need to do A/B testing with your database and application.
To sum this page up (ha!), enable those checksums! It’s worth the one-time cost of not being able to use pg_upgrade, and the ongoing cost of a little more CPU. Don’t wait for your corruption to get so bad the system catalogs start getting confused—find out the moment a bit gets flipped.
Comments