SSH Key Access Recovery on EC2 Instances

By Josh Williams
October 2, 2016
Can’t access your EC2 instance? Throw it away and spin up a new one! Everyone subscribes to the cattle server pattern, yes?
Not quite, of course. Until you reach a certain scale, that’s not as easy to maintain as a smaller grouping of pet servers. While you can certainly run with that pattern on Amazon, EC2 instances aren’t quite as friendly about overcoming access issues as other providers are. That’s to say, even if you have access to the AWS account there’s no interface for forcing a root password change or the like.
But sometimes you need that, as an End Point client did recently. It was a legacy platform, and the party that set up the environment wasn’t available. However an issue popped up that needed solved, so we needed a way to get in. The process involves some EBS surgery and does involve a little bit of downtime, but is fairly straightforward. The client’s system was effectively down already, so taking it all the way offline had little impact.
Also do make sure this is the actual problem, and not that the connection is blocked by security group configuration or some such.
-
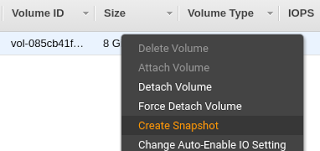
For safe keeping, it’s recommended to create a snapshot of the original root volume. If something goes wrong, you can then roll back to that point.
-

Create temporary working instance in the same availability zone as the instance to fix. A micro instance is fine. Don’t forget to set a key that you do have access to.
-
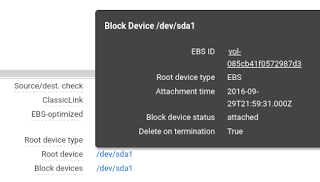
Find the instance you need to fix and note the root volume ID. Double check that it has an elastic IP assignment: when stopped the instance IP address will change if not associated with a static elastic IP. Similarly, ephemeral storage will be cleared (but hopefully you’re not relying on having anything permanently there anyway.)
-
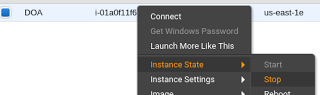
Stop, do not terminate, the instance to be fixed.
-
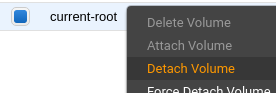
Find the root volume for the instance to be fixed using the ID found earlier (or just click it within the instance details pane) and detach it from the instance. Attach it to your working instance.
-

Connect in to your working instance, and mount that volume as /mnt (or anywhere, really. Just using /mnt as an example here.)
-
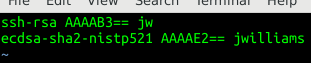
Copy any needed ssh keys into the .ssh/authorized_keys under /mnt/home/ubuntu/ or /mnt/home/ec2-user/ depending on the base distro used for the image, or even just to /mnt/root/. And/or make any other fixes needed.
-
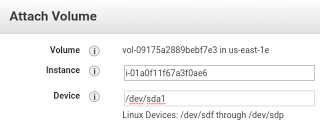
When all is good, umount the volume and detach it from the working instance. Attach it back to the original instance as /dev/sda1 (even though it doesn’t say that’s an option.)
-
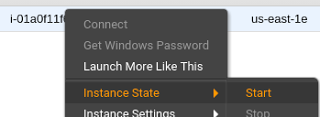
Boot original instance. If all goes well you should now be able to connect in using the ssh key you added. Ensure that everything comes up on boot. Terminate the temporary working instance (and do make sure you don’t terminate the wrong one.)
That’s not the only approach, of course. If you have a partially functional system, for example, you may be better off immediately creating a volume from the snapshot created in step 0, mounting that in another instance for the modifications, and then performing the stop, root volume swap, and start in quick succession. That’ll minimize any actual downtime, at the potential expense of losing any data changes happening in between the snapshot and the reboot.
Either way just remember there are options, and all is not lost!
-
-
-
-
-
-
-
-
Comments