Check JSON responses with Nagios

By Brian Buchalter
March 18, 2012
As the developer’s love affair with JSON continues to grow, the need to monitor successful JSON output does as well. I wanted a Nagios plugin which would do a few things:
- Confirm the content-type of the response header was “application/json”
- Decode the response to verify it is parsable JSON
- Optionally, verify the JSON response against a data file
Verify content of JSON response
For the most part, Perl’s LWP::UserAgent class makes short work of the first requirement. Using $response->header(“content-type”) the plugin is able to check the content-type easily. Next up, we use the JSON module’s decode function to see if we can successfully decode $response->content.
Optionally, we can give the plugin an absolute path to a file which contains a Perl hash which can be iterated through in attempt to find corresponding key/value pairs in the decoded JSON response. For each key/value in the hash it doesn’t find in the JSON response, it will append the expected and actual results to the output string, exiting with a critical status. Currently there’s no way to check a key/value does not appear in the response, but feel free to make a pull request on check_json on my …
hosting monitoring
A Cache Expiration Strategy in RailsAdmin

By Steph Skardal
March 16, 2012
I’ve been blogging about RailsAdmin a lot lately. You might think that I think it’s the best thing since sliced bread. It’s a great configurable administrative interface compatible with Ruby on Rails 3. It provides a configurable architecture for CRUD (create, update, delete, view) management of resources with many additional user-friendly features like search, pagination, and a flexible navigation. It integrates nicely with CanCan, an authorization library. RailsAdmin also allows you to introduce custom actions such as import, and approving items.
Whenever you are working with a gem that introduces admin functionality (RailsAdmin, ActiveAdmin, etc.), the controllers that provide resource management do not live in your code base. In Rails, typically you will see cache expirations in the controller that provides the CRUD functionality. For example, in the code below, a PagesController will specify caching and sweeping of the page which expires when a page is updated or destroyed:
class PagesController < AdminController
caches_action :index, :show
cache_sweeper :page_sweeper, :only => [ :update, :destroy ]
...
endWhile working with RailsAdmin, I’ve come up with a …
rails
Check HTTP redirects with Nagios
By Brian Buchalter
March 15, 2012
Often times there are critical page redirects on a site that may want to be monitored. Often times, it can be as simple as making sure your checkout page is redirecting from HTTP to HTTPS. Or perhaps you have valuable old URLs which Google has been indexing and you want to make sure these redirects remain in place for your PageRank. Whatever your reason for checking HTTP redirects with Nagios, you’ll find there are a few scripts available, but none (that I found) which are able to follow more than one redirect. For example, let’s suppose we have a redirect chain that looks like this:
http://myshop.com/cart >> http://www.myshop.com/cart >> https://www.mycart.com/cartFollowing multiple redirects
In my travels, I found check_http_redirect on Nagios Exchange. It was a well designed plugin, written by Eugene Kovalenja in 2009 and licensed under GPLv2. After experimenting with the plugin, I found it was unable to traverse multiple redirects. Fortunately, Perl’s LWP::UserAgent class provides a nifty little option called max_redirect. By revising Eugene’s work, I’ve exposed additional command arguments that help control how many redirects to follow. Here’s a summary of usage: …
hosting monitoring
RailsAdmin: A Custom Action Case Study

By Marina Lohova
March 15, 2012
RailsAdmin is an awesome tool that can be efficiently used right out of box. It provides a handy admin interface, automatically scanning through all the models in the project and enhancing them with List, Create, Edit and Delete actions. However, sometimes we need to create a custom action for a more specific feature.
Creating The Custom Action
Here we will create an “Approve Review” action, that the admin will use to moderate user reviews. First, we need to create an action class rails_admin_approve_review.rb in Rails::Config::Actions namespace and place it in the “#{Rails.root}/lib” folder. Here is the template for it:
require 'rails_admin/config/actions'
require 'rails_admin/config/actions/base'
module RailsAdminApproveReview
end
module RailsAdmin
module Config
module Actions
class ApproveReview < RailsAdmin::Config::Actions::Base
end
end
end
endBy default, all actions are present for all models. We will only show the “Approve” action for the models that actually support it and are yet unapproved. It means that they have approved attribute defined and set to false:
register_instance_option :visible? do
authorized? && …rails
A Little Less of the Middle

By Josh Williams
March 14, 2012

I’ve been meaning to exercise a bit more. You know, just to keep the mid section nice and trim. But getting into that habit doesn’t seem to be so easy. Trimming middleware from an app, that’s something that can catch my attention.
Something that caught my eye recently is a couple recent commits to Postgres 9.2 that adds a JSON data type. Or more specifically, the second commit that adds a couple handy output functions: array_to_json() and row_to_json(). If you want to try it out on 9.1, those have been made available as a backported extension.
Lately I’ve been doing a bit of work with jQuery, using it for AJAX-y stuff but passing JSON around instead. (AJAJ?) And traditionally that involves something in between the database and the client rewriting rows from one format to another. Not that it’s all that difficult; for example, in Python it’s a simple module call:
jsonresult = json.dumps(cursor.fetchall())… assuming I don’t have any columns needing processing: TypeError: datetime.datetime(2012, 3, 09, 18, 34, 20, 730250, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=0, name=None)) is not JSON serializable Similarly in PHP I can stitch together a …
jquery json postgres
The Mystery of The Zombie Postgres Row

By Greg Sabino Mullane
March 14, 2012

Being a PostgreSQL DBA is always full of new challenges and mysteries. Tracking them down is one of the best parts of the job. Presented below is an error message we received one day via tail_n_mail from one of our client’s production servers. See if you can figure out what was going on as I walk through it. This is from a “read only” database that acts as a Bucardo target (aka slave), and as such, the only write activity should be from Bucardo.
05:46:11 [85]: ERROR: duplicate key value violates unique constraint "foobar_id"
05:46:11 [85]: CONTEXT: COPY foobar, line 1: "12345#011...Okay, so there was a unique violation during a COPY. Seems harmless enough. However, this should never happen, as Bucardo always deletes the rows it is about to add in with the COPY command. Sure enough, going to the logs showed the delete right above it:
05:45:51 [85]: LOG: statement: DELETE FROM public.foobar WHERE id IN (12345)
05:46:11 [85]: ERROR: duplicate key value violates unique constraint "foobar_id"
05:46:11 [85]: CONTEXT: COPY foobar, line 1: "12345#011...How weird. Although we killed the row, it seems to have resurrected, and shambled like a zombie into our …
bucardo database postgres
PHP Vulnerabilities and Logging
By Steph Skardal
March 13, 2012
I’ve recently been working on a Ruby on Rails site on my personal Linode machine. The Rails application was running in development with virtually no caching or optimization, so page load was very slow. While I was not actively developing on the site, I received a Linode alert that the disk I/O rate exceeded the notification threshold for the last 2 hours.
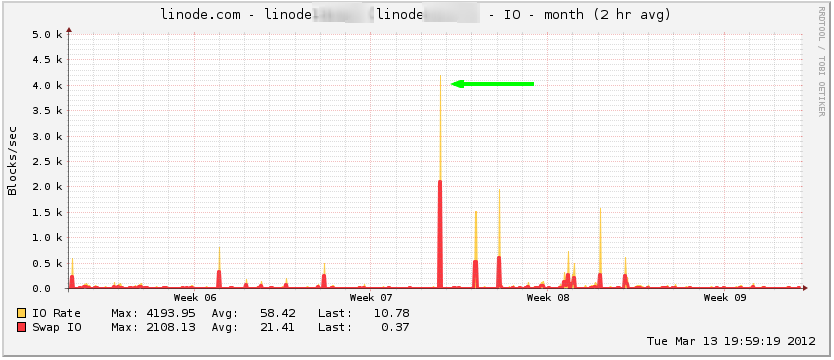
Since I was not working on the site and I did not expect to see search traffic to the site, I was not sure what caused the alert. I logged on to the server and checked the Rails development log to see the following:
Started GET "/muieblackcat" for 200.195.156.242 at 2012-02-15 10:01:18 -0500
Started GET "/admin/index.php" for 200.195.156.242 at 2012-02-15 10:01:21 -0500
Started GET "/admin/pma/index.php" for 200.195.156.242 at 2012-02-15 10:01:22 -0500
Started GET "/admin/phpmyadmin/index.php" for 200.195.156.242 at 2012-02-15 10:01:24 -0500
Started GET "/db/index.php" for 200.195.156.242 at 2012-02-15 10:01:25 -0500
Started GET "/dbadmin/index.php" for 200.195.156.242 at 2012-02-15 10:01:27 -0500
Started GET "/myadmin/index.php" for 200.195.156.242 at 2012-02-15 10:01:28 …hosting security
Handling outside events with jQuery and Backbone.js

By Greg Davidson
March 2, 2012
I recently worked on a user interface involving a persistent shopping cart on an ecommerce site. The client asked to have the persistent cart close whenever a user clicked outside or “off” of the cart while it was visible. The cart was built with Backbone.js, and jQuery so the solution would need to play nicely with those tools.
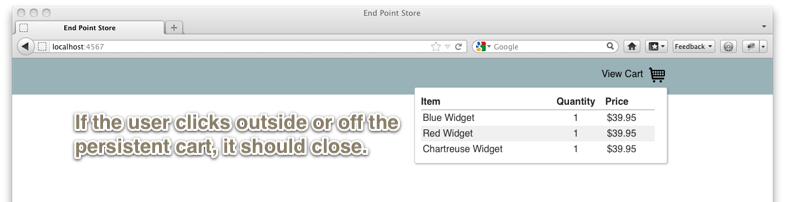
The first order of business was to develop a way to identify the “outside” click events. I discussed the scenario with a colleague and YUI specialist and he suggested the YUI Outside Events module. Since the cart was built with jQuery and I enjoyed using that library, I looked for a comparable jQuery plugin and found Ben Alman’s Outside Events plugin. Both projects seemed suitable and a review of their source code revealed a similar approach. They listened to events on the document or the element and examined the event.target property of the element that was clicked. Checking to see if the element was a descendant of the containing node revealed whether the click was “inside” or “outside”.
With this in mind, I configured the plugin to listen to clicks outside of the persistent cart like so:
$(function(){
$('#modal-cart').bind( …javascript jquery