Ubuntu Dual Monitor Setup on Dell XPS

By Steph Skardal
October 1, 2012
Over the weekend, I received a new desktop (Dell XPS 8500 with NVIDIA graphics card) and troubleshot dual monitor setup on Ubuntu. Because I spent quite a while googling for results, I thought I’d write up a quick summary of what did and didn’t work.
One monitor was connected via HDMI and the other through DVI (with a VGA to DVI adaptor provided with the computer). When I started up the computer in Windows, both monitors were recognized immediately. Besides configuring the positioning of the monitors, Windows was good to go. But when I installed Ubuntu, the DVI/VGA monitor was recognized with incorrect resolution and the monitor connected via HDMI was not recognized at all. I tried switching the unrecognized monitor to a VGA/DVI connection, and it worked great by itself, so I concluded that it wasn’t an issue with a driver for the HDMI-connected monitor.
Many of the Google results I came across pointed to troubleshooting with xrandr, but any xrandr commands produced a “Failed to get size of gamma for output default.” error and any progress beyond that was shut down. Another set of Google results pointed to using “nvidia-detector”, but there …
ubuntu
Defense in Depth

By Zed Jensen
September 28, 2012
“Defense in depth” is a way to build security systems so that when one layer of defense fails, there is another to take its place. If breaking in is hard enough for an attacker, it’s likely that they’ll abandon their assault, deciding it’s not worth the effort. Making the various layers different types of defense also makes it harder to get in, so that an attacker is less likely to get through all the layers. It can also keep one mistake from causing total security failure.
For example, if you have an office with one door and leave it unlocked by accident, then anyone can just walk in. However, if you have an office building with a main door, then a lobby and hallways, and then additional inner locked doors, then the chance of accidentally leaving both unlocked is small. If you accidentally leave the inner door open or unlocked, someone can only get into the office if they first get through the outer door.
Another example of defense in depth is making and maintaining offsite computer backups. The chance of an office being destroyed and all your data with it is low, but not zero. If you maintain offsite backups, then your losses in a catastrophe are reduced.
Another way to decrease …
security backups
Test Web Sites with Internet Explorer for Free

By Greg Davidson
September 26, 2012
Browser Testing
While many Web Developers prefer to build sites and web applications with browsers like Chrome or Firefox it’s important for us to keep an eye on the browser market share for all web users. Internet Explorer (IE) still owns a large piece of this pie and because of this, it is important to test sites and applications to ensure they work properly when viewed in IE. This poses a potential problem for developers who do not use Windows.
Although I use OS X on my desktop, I have Windows virtual machines with IE 6,7,8,9 and 10 installed. I also have a Linux virtual machine running Ubuntu so I can check out Chrome/Chromium and Firefox on that platform. In the past I had tried solutions like MultipleIEs but wasn’t satisfied with them. In my experience I’ve found that the best way to see what users are seeing is to have a virtual machine running the same software they are.
I did some IE8 testing for a colleague a short time ago and suggested she should give VirtualBox a shot. Her response was “You should write a blog post about that!”. So here we are.
Free Tools
VirtualBox is a free virtualization application similar to Parallels or VMWare. These …
browsers environment testing tips tools virtualization
Piggybak: An Update on End Point's Ruby on Rails Ecommerce Engine
By Steph Skardal
September 24, 2012
With the recent release of one of our client sites running on Piggybak, Piggybak saw quite a few iterations, both for bug fixes and new feature development. Here are a few updates to Piggybak since its announcement earlier this year.
Admin: Continues to Leverage RailsAdmin
Piggybak continues to leverage RailsAdmin. RailsAdmin is a customizable admin interface that automagically hooks into your application models. In the case of the recent project completion, the admin was customized to add new features and customize the appearance, which can be done in RailsAdmin with ease.
As much as I enjoy working with RailsAdmin, I think it would be great in the future to expand the admin support to include other popular Rails admin tools such as ActiveAdmin, which has also gained popularity in the Rails space.
Refund Adjustments
When Piggybak first came out, there was little in the way to allow orders to be monetarily adjusted in the admin after an order was placed. One requirement that came out of client-driven development was the need for recording refund adjustments. A new model for “Adjustments” is now included in Piggybak. An arbitrary adjustment can be entered in the admin, …
ecommerce piggybak rails
Insidious List Context

By Jeff Boes
September 20, 2012
Recently, I fell into a deep pit. Not literally, but a deep pit of Perl debugging. As a result, I’m here to warn you and yours about “Insidious List Context(TM)”.
(Note: this is a fairly elementary discussion, for people early in their Perl wizardry training.)
Perl has two contexts for evaluating expressions: list and scalar. (All who know this stuff cold can skip down a ways.) “Scalar” context is what non-Perl languages just call “normal reality”, but Perl likes to do things … differently … so we have more than one context.
In scalar context, a scalar is a scalar is a scalar, but a list becomes a scalar that represents the number of items in the list. Thus,
@x = (1, 1, 1); # @x is a list of three 1s
# vs.
$x = (1, 1, 1); # $x is "3", the list sizeIn list context, a list of things is still a list of things. That’s pretty simple, but when you are expecting a scalar and you get a list, your world can get pretty confused.
Okay, now the know-it-alls have rejoined us. I had a Perl hashref being initialized with code something like this:
my $hr = {
KEY1 => $value1,
KEY2 => $value2,
KEY_TROUBLE => …interchange perl
Rails 4 Highlights
By Steph Skardal
September 20, 2012
I watched this recent video What to Expect in Rails 4.0 presented by Prem Sichanugrist to the Boston Ruby Group. Here are a few high-level topics he covered in the talk:
- StrongParameters: replaces attr_accessor, attr_protected, moves param filtering concern to the controller rather than the model. Moving param filtering concern to the controller allows you to more easily modify user attribute change-ability in controllers (e.g. customer-facing vs admin).
- ActiveSupport::Queue: Discussed at RailsConf, add queueing support to Rails, e.g.:
# Add to queue
Rails.queue.push UserRegistrationMailerJob(@user.id)
# Control queue configuration (asynchronous, synchronous or resque, e.g.
config.queue = [:asynchronous, :synchronous, :resque]-
Cache Digests: Rails 4.0 introduces cache key generation based on an item and its dependencies, so nested cache elements properly expire when an item is updated.
-
PATCH verb support: Support of HTTP PATCH method (_method equals “patch”), which will map to your update action is introduced in Rails 4.0.
-
Routing Concern: Rails 4.0 introduces some methods to help clean up your duplicate routes.
-
Improvements to ActiveRecord::Relation …
ruby rails
AJAX Queuing in Piggybak
By Steph Skardal
September 18, 2012
AJAX is inherently asynchronous; for the most part, this works fine in web development, but sometimes it can cause problem if you have multiple related AJAX calls that are asynchronous to eachother, such as the use case described in this article.
In Piggybak, a Ruby on Rails open source shopping cart module developed and maintained by End Point, the one page checkout uses AJAX to generate shipping options. Whenever state and zip options change, the shipping address information is sent via AJAX and valid shipping methods are returned and rendered in a select dropdown.
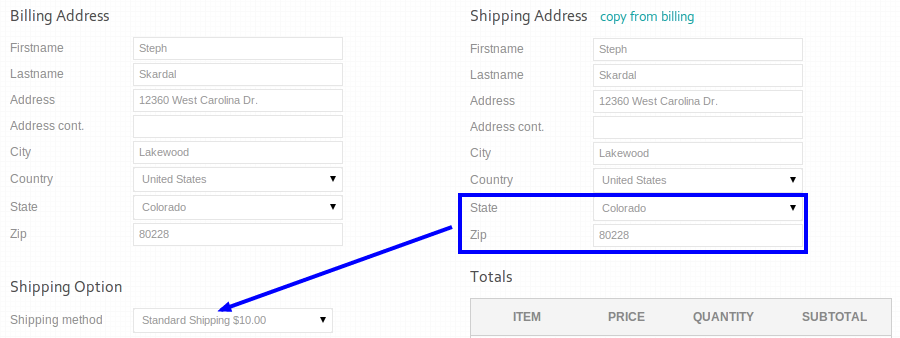
Event listeners on the state and zip code inputs trigger to generate shipping options via AJAX.
While working on development for a client using Piggybak, I came across a scenario where AJAX asynchronous-ity was problematic. Here’s how the problematic behavior looked on a timeline, picking up as the user enters their shipping address:
- 0 seconds: User changes state, triggers AJAX shipping lookup with state value, but no zip code entered (Let’s refer to this as AJAX REQUEST 1).
- 1 second: User changes zip code, triggers AJAX shipping lookup with state and zip value present (Let’s refer to this as AJAX …
javascript ecommerce jquery piggybak rails
Company Presentation: Ecommerce as an Engine
By Steph Skardal
September 14, 2012
Today, I gave the presentation to my coworkers entitled “Puppies & Ecommerce as an Engine”. The presentation is strongly coupled with my work on Piggybak, and includes a discussion of traditional ecommerce platforms versus a lightweight ecommerce approach through modularity (Rails Engine). It also provides some code examples as how this does work in Piggybak.
Below are a few more related articles to my work on Piggybak. Check them out!
ecommerce piggybak rails spree company