Postgres custom casts and pg_dump

By Greg Sabino Mullane
February 10, 2015
We recently upgraded a client from Postgres version 8.3 to version 9.4. Yes, that is quite the jump! In the process, I was reminded about the old implicit cast issue. A major change of Postgres 8.3 was the removal of some of the built-in casts, meaning that many applications that worked fine on Postgres 8.2 and earlier started throwing errors. The correct response to fixing such things is to adjust the underlying application and its SQL. Sometimes this meant a big code difference. This is not always possible because of the size and/or complexity of the code, or simply the sheer inability to change it for various other reasons. Thus, another solution was to add some of the casts back in. However, this has its own drawback, as seen below.

While this may seem a little academic, given how old 8.3 is, we still see that version in the field. Indeed, we have more than a few clients running versions even older than that! While pg_upgrade is the preferred method for upgrading between major versions (even upgrading from 8.3), its use is not always possible. For the client in this story, in addition to some system catalog corruption, we wanted to move to using data …
database postgres
Updated End Point Blog Stats and Our Services

By Steph Skardal
February 10, 2015
Today, I sat down to read through a few recent End Point blog articles and was impressed at the depth of topics in recent posts (PostgreSQL, Interchange, SysAdmin, Text Editors (Vim), Dancer, AngularJS) from my coworkers. The list continues if I look further back covering technologies in both front and back end web development. And, this list doesn’t even cover the topics I typically write about such as Ruby on Rails & JavaScript.
While 5 years ago, we may have said we predominately worked with ecommerce clients, our portfolio has evolved to include Liquid Galaxy clients and many non-ecommerce sites as well. With the inspiration from reading through these recent posts, I decided to share some updated stats.
Do you remember my post on Wordle from early 2011? Wordle is a free online word cloud generator. I grabbed updated text from 2013 and on from our blog, using the code included in my original post, and generated a new word cloud from End Point blog content:

End Point blog Word cloud from 2013 to present
I removed common words from the word cloud not removed from the original post, including “one”, “like”, etc. Compared to the original post, it looks like database related …
company
Interchange Loop Optimization

By Mark Johnson
February 9, 2015
It’s important to understand both how loops work in Interchange and the (very) fundamental differences between interpolating Interchange tag language (ITL) and the special loop tags (typically referred to as [PREFIX-*] in the literature). Absent this sometimes arcane knowledge, it is very easy to get stuck with inefficient loops even with relatively small loop sets. I’ll discuss both the function of loops and interpolation differences between the tag types while working through a [query] example. While all loop tags–[item-list], [loop], [search-list], and [query]–process similarly, it is to [query] where most complex loops will gravitate over time (to optimize the initiation phase of entering the loop) and where we have the most flexibility for coming up with alternative strategies to mitigate sluggish loop-processing.
Loop Processing
All loop tags are container tags in Interchange, meaning they have an open and close tag, and in between is the body. Only inside this body is it valid to define [PREFIX-] tags (notable exception of [PREFIX-quote] for the sql arg of [query]). This is because the [PREFIX-] tags are not true ITL. They are tightly coupled with the structure …
ecommerce interchange optimization performance perl
Cron Wrapper: Keep your cron jobs environment sane

By Richard Templet
February 6, 2015
It is becoming more common for developers to not use the operating system packages for programming languages. Perl, Python, Ruby, and PHP are all making releases of new versions faster than the operating systems can keep up (at least without causing compatibility problems). There are now plenty of tools to help with this problem. For Perl we have Perlbrew and plenv. For Ruby there is rbenv and RVM. For Python there is Virtualenv. For PHP there is PHP version. These tools are all great for many different reasons but they all have issues when being used with cron jobs. The cron environment is very minimal on purpose. It has a very restrictive path, very few environment variables and other issues. As far as I know, all of these tools would prefer using the env command to get the right version of the language you are using. This works great while you are logged in but tends to fail bad as a cron job. The cron wrapper script is a super simple script that you put before whatever you want to run in your crontab which will ensure you have the right environment variables set.
#!/bin/bash -l
exec "$@"The crontab entry would look something like this:
34 12 * * * bin/cron-wrapper …devops hosting
Vim Plugin Spotlight: CtrlP

By Patrick Lewis
February 6, 2015
When I started using Vim I relied on tree-based file browsers like netrw and NerdTree for navigating a project’s files within the editor. After discovering and trying the CtrlP plugin for Vim I found that jumping directly to a file based on its path and/or filename could be faster than drilling down through a project’s directories one at a time before locating the one containing the file I was looking for.
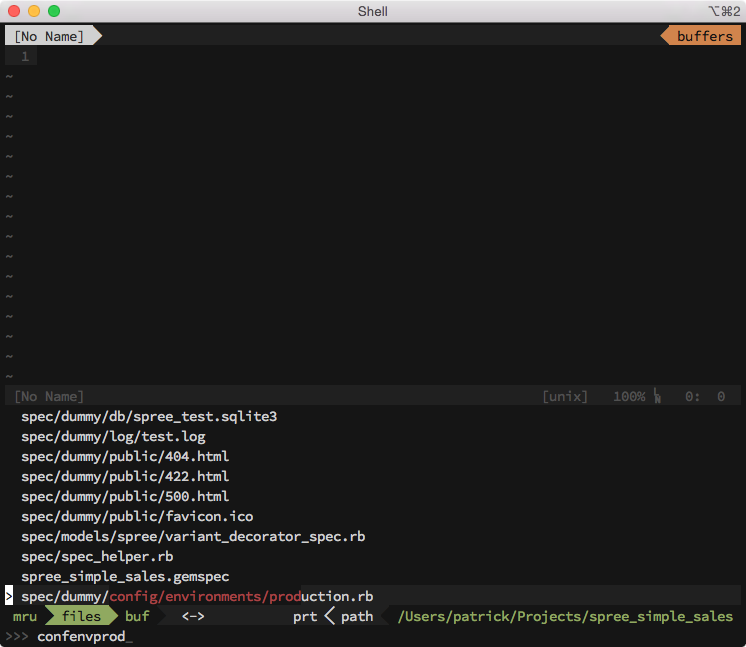
After it’s invoked (usually by a keyboard shortcut) CtrlP will display a list of files in your current project and will filter that list on the fly based on your text input, matching it against both directory names and file names. Pressing
map <leader>b :CtrlPBuffer<cr></cr>CtrlP has many configuration options that can affect its performance and behavior, and installing additional …
extensions vim
Filling in header elements with Dancer and Template::Flute

By Jeff Boes
February 5, 2015
Inserting content into Dancer output files involves using a templating system. One such is Template::Flute. In its simplest possible explanation, it takes a Perl hash, an XML file, and an HTML template, and produces a finished HTML page.
For a project involving Dancer and Template::Flute, I needed a way to prepare each web page with its own set of JavaScript and CSS files. One way is to construct separate layout files for each different combination of .js and .css, but I figured there had to be a better way.
Here’s what I came up with: I use one layout for all my typical pages, and within the header, I have:
<link class="additional_style" href="/css/additional.css" rel="stylesheet" type="text/css"/>
<script class="additional_script" src="/javascripts/additional.js" type="text/javascript">
</script>The trick here is, there’s no such files “additional.css” and “additional.js”. Instead, those are placeholders for the actual CSS and JS files I want to link into each HTML file.
My Perl object has these fields (in addition to the other content):
$context->{additional_styles} = [
{ url => …dancer perl
Polemics on opinions about AngularJS

By Kamil Ciemniewski
February 5, 2015
Some time ago, our CTO, Jon Jensen, sent me a link to a very interesting blog article about AngularJS.
I have used the AngularJS framework in one of our internal projects and have been (vocally) very pleased with it ever since. It solves many problems of other frameworks and it makes you quite productive as a developer, if you know what you’re doing. It’s equally true that even the best marketed technology is no silver bullet in real life. Once you’ve been through a couple of luckless technology-crushes, you tend to stay calm—understanding that in the end there’s always some tradeoff.
We’re trying to do our best at finding a balance between chasing after the newest and coolest, and honoring what’s already stable and above all safe. Because the author of the blog article decided to point at some elephants in the room—it immediately caught our attention.
I must admit that the article resonates with me somewhat. I believe, though, that it also doesn’t in some places.
While I don’t have as much experience with Angular as this article’s author, I clearly see him sometimes oversimplifying, overgeneralizing, and being vague.
I’d like to address many of the author’s points in detail, so …
angular javascript
FOSDEM conference day 2

By Emanuele “Lele” Calò
February 2, 2015
It’s Sunday evening, the 2015 FOSDEM conference is over, so it’s time to give my impressions and opinions.
As I already said in my day 1 blog post, I really enjoyed the conference as I usually do in this kind of open source, enthusiast, knowledge sharing conference.
Now that’s also where the FOSDEM somehow slightly disappointed me: I lived it as yet another conference with a series of talks and some nice ideas here and there.
When I heard about the FOSDEM I always heard about a developer-centric conference so my first natural conclusion was that there probably would have been a lot of cooperative hand-on coding, some pair programming, huge hackathon rooms and so on. Unfortunately this wasn’t the case, from what I could see.
Don’t get me wrong: I really loved all the talks I attended and really appreciated all the input I had, which is awesome.
But as you may know when expectations fall short you always remain with a little bit of bitter taste wandering inside you.
That said I really loved the talks about KVM Observability from Stefan Hajnoczi which provided me a lot of interesting hints and tools I could use straight away when coming back at work and the NUMA architecture in oVirt …
conference open-source