Raw Packet Manipulation with Scapy

By Kirk Harr
April 29, 2015
Installation
Scapy is a Python-based packet manipulation tool which has a number of useful features for those looking to perform raw TCP/IP requests and analysis. To get Scapy installed in your environment the best options are to either build from the distributed zip of the current version, or there are also some pre-built packages for Red Hat and Debian derived linux OS.
Using Scapy
When getting started with Scapy, it’s useful to start to understand how all the aspects of the connection get encapsulated into the Python syntax. Here is an example of creating a simple IP request:
Welcome to Scapy (2.2.0)
>>> a=IP(ttl=10)
>>> a
<IP ttl=10 |>
>>> a.dst="10.1.0.1"
>>> a
<IP ttl=10 dst=10.1.0.1 |>
>>> a.src
'10.1.0.2'
>>> a.ttl
10In this case I created a single request which was point from one host on my network to the default gateway on the same network. Scapy will allow the capability to create any TCP/IP request in raw form. There are a huge number of possible options for Scapy that can be applied, as well as huge number of possible packet types defined. The documentation with these options and …
python
Protect Interchange Passwords with Bcrypt

By Mark Johnson
April 28, 2015
Interchange default configurations have not done a good job of keeping up with the best available password security for its user accounts. Typically, there are two account profiles associated with a standard Interchange installation: one for admin users (access table) where the password is stored using Perl’s crypt() command (bad); and one for customers (userdb) where the password isn’t encrypted at all (even worse). Other hashing algorithms have long been available (MD5, salted MD5, SHA1) but are not used by default and have for some time not been useful protection. Part of this is convenience (tools for retrieving passwords and ability to distribute links into user assets) and part is inertia. And no small part was the absence of a strong cryptographic option for password storage until the addition of Bcrypt to the account management module.
The challenge we face in protecting passwords is that hardware continues to advance at a rapid rate, and with more computational power and storage capacity, brute-force attacks become increasingly effective and widely available. Jeff Jarmoc’s Enough with the Salts provides some excellent discussion and background on the subject. To counter …
bcrypt ecommerce interchange security sysadmin
RailsConf 2015 for the non-Attendee

By Steph Skardal
April 28, 2015
This blog post is really for myself. Because I had the unique experience of bringing a baby to a conference, I made an extra effort to talk to other attendees about what sessions shouldn’t be missed. Here are the top takeaways from the conference that I recommend (in no particular order):
- Watch DHH’s Keynote
- … and Aaron Patterson Keynote
- Watch Kent Beck’s Keynote
- Amelia Bedelia Learns to Code, by Kylie Stradley, was a popular talk from day 1. Video link forthcoming.
- Watch Shipping Ruby Apps with Docker by Bryan Helmkamp. This video was strongly recommended before jumping into Docker, which was a trendy topic in dev-ops talks.
- Watch Justin Searls’ talk Sometimes a Controller is Just a Controller.
- Watch Sandi Metz’s talk Nothing is Something.
- Read this book by Don Norman if you care about UX. Joe Mastey recommended it in his talk, Bringing UX to Your Code.
- Yehuda Katz & Tom Dale’s talk, How Rust Helped us Write Better Ruby was standing room only. Video link forthcoming. Also check out their fireside chat on Ember.js.
- Riding Rails for 10 Years by John Duff gives a great history of the evolution of Rails in the Shopify codebase.
Right now, the videos are all unedited from …
conference rails
How to Bring a Baby to a Tech Conference
By Steph Skardal
April 27, 2015
Last week, I brought my 4 month old to RailsConf. In a game-day decision, rather than drag a two year old and husband along on the ~5 hour drive and send the dogs to boarding, we decided it would ultimately be easier on everyone (except maybe me) if I attended the conference with the baby, especially since a good amount of the conference would be live-streamed.

Daily morning photos at the conference.
While I was there, I was asked often how it was bringing a baby to a conference, so I decided to write a blog post. As with all parenting advice, the circumstances are a strong factor in how the experience turned out. RailsConf is a casual three-day multi-track tech conference with many breaks and social events—it’s as much about socialization as it is about technical know-how. This is not my first baby and not my first time at RailsConf, so I had some idea of what I might be getting into. Minus a few minor squeaks, baby Skardal was sleeping or sitting happily throughout the conference.
Here’s what I [qualitatively] perceived to be the reaction of others attending the conference to baby Skardal:
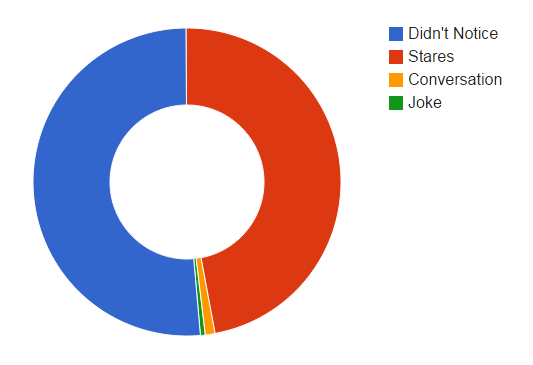
In list form:
- Didn’t Notice: Probably about 50% didn’t notice I had a baby, especially …
conference rails
RailsConf 2015—Atlanta: Day Three
By Steph Skardal
April 23, 2015
Today, RailsConf concluded here in Atlanta. The day started with the reveal of this year’s Ruby Heroes, followed by a Rails Core panel. Watch the video here.
On Trailblazer
One interesting talk I attended was See You on The Trail by Nick Sutterer, sponsored by Engine Yard, a talk where he introduced Trailblazer. Trailblazer is an abstraction layer on top of Rails that introduces a few additional layers that build on the MVC convention. I appreciated several of the arguments he made during the talk:
- MVC is a simple level of abstraction that allows developers to get up and running efficiently. The problem is that everything goes into those three buckets, and as the application gets more complex, the simplified structure of MVC doesn’t answer on how to organize logic like authorization and validation.
- Nick made the argument that DHH is wrong when says that microservices are the answer to troublesome monolithic apps. Nick’s answer is a more structured, organized OO application.
- Rails devs often say “Rails is simple”, but Nick made the argument that Rails is easy (subjective) but not simple (objective). While Rails follows convention with the idea that transitioning between developers …
conference rails
RailsConf 2015—Atlanta: Day Two
By Steph Skardal
April 22, 2015
It’s day 2 of RailsConf 2015 in Atlanta! I made it through day 1!
The day started with Aaron Patterson’s keynote (watch it here). He covered features he’s been working on including auto parallel testing, cache compiled views, integration test performance, and “soup to nuts“ performance. Aaron is always good at starting his talk with self-deprecation and humor followed by sharing his extensive performance work supported by lots of numbers.
On Hiring
One talk I attended today was “Why We’re Bad At Hiring (And How To Fix It)” by @kerrizor of Living Social (slides here, video here). I was originally planning on attending a different talk, but a fellow conference attendee suggested this one. A few gems (not Ruby gems) from this talk were:
- Imagine your company as a small terrarium. If you are a very small team, hiring one person can drastically affect the environment, while hiring one person will be less influential for larger companies. I liked this analogy.
- Stay away from monocultures (e.g. the banana monoculture) and avoid hiring employees just like you.
- Understand how your hiring process may bias you to reject specific candidates. For example, requiring a GitHub account may bias …
conference rails
Handling databases in dev environments for web development

By Spencer Christensen
April 21, 2015
One of the biggest problems for web development environments is copying large amounts of data. Every time a new environment is needed, all that data needs to be copied. Source code should be tracked in version control software, and so copying it should be a simple matter of checking it out from the code repository. So that is usually not the problem. The main problem area is database data. This can be very large, take a long time to copy, and can impact the computers involved in the copy (usually the destination computer gets hammered with IO which makes load go high).
Often databases for development environments are created by copying a database dump from production and then importing that database dump. And since database dumps are text, they can be highly compressed, which can result in a relatively small file to copy over. But the import of the dump can still take lots of time and cause high load on the dev computer as it rebuilds tables and indexes. As long as your data is relatively small, this process may be perfectly acceptable.
Your database WILL get bigger
At some point though your database will get so big that this process will take too long and cause too much …
camps database environment storage sysadmin
RailsConf 2015—Atlanta: Day One
By Steph Skardal
April 21, 2015
I’m here in Atlanta for my sixth RailsConf! RailsConf has always been a conference I enjoy attending because it includes a wide spectrum of talks and people. The days are long, but rich with nitty gritty tech details, socializing, and broader topics such as the social aspects of coding. Today’s keynote started with DHH discussing the shift towards microservices to support different types of integrated systems, and then transitioned to cover code snippets of what’s to come in Rails 5, to be released this year. Watch the keynote here.
Open Source & Being a Hero
One of the talks I was really looking forward to attending was “Don’t Be a Hero—Sustainable Open source Dev” by Lillie Chilen (slides here, video here), because of my involvement in open source (with Piggybak, RailsAdminImport, Annotator and Spree, another Ruby on Rails ecommerce framework). In the case of RailsAdminImport, I found a need for a plugin to RailsAdmin, developed it for a client, and then released it into the open source with no plans on maintaining a community. I’ve watched as it’s been forked by a handful of users who were in need of the same functionality, but I most recently gave another developer commit …
conference rails