IPv6 Tunnels with Debian/Ubuntu behind NAT

By Brian Buchalter
March 1, 2012
As part of End Point’s preparation for World IPv6 Launch Day, I was asked to get my IPv6 certification from Hurricane Electric. It’s a fun little game-based learning program which had me setup a IPv6 tunnel. IPv6 tunnels are used to provide IPv6 for those whose folks whose ISP or hosting provider don’t currently support IPv6, by “tunneling” it over IPv4. The process for creating a tunnel is straight forward enough, but there were a few configuration steps I felt could be better explained.
After creating a tunnel, Hurricane Electric kindly provides a summary of your configuration and offers example configurations for several different operating systems and routers. Below is my configuration summary and the example generated by Hurricane Electric.

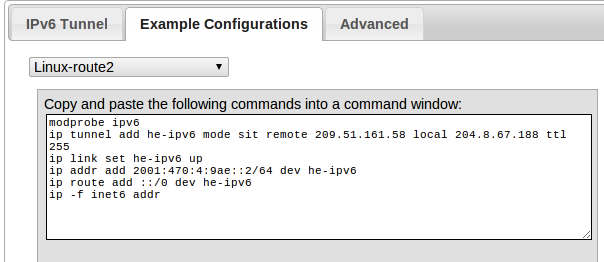
However, entering these commands change won’t survive a restart. For Debian/Ubuntu users an update in /etc/network/interfaces does the trick.
#/etc/network/interfaces
auto he-ipv6
iface he-ipv6 inet6 v4tunnel
address 2001:470:4:9ae::2
netmask 64
endpoint 209.51.161.58
local 204.8.67.188
ttl 225
gateway 2001:470:4:9ae::1Firewall Configuration
If you’re running UFW the updates to /etc/default/ufw are very …
debian hosting linux networking sysadmin
jQuery Async AJAX: Interrupts IE, not Firefox, Chrome, Safari

By Carl Bailey
March 1, 2012
I recently worked on a job for a client who uses (Thickbox). Now, ThickBox is no longer maintained, but the client has used it for a while, and, “if it ain’t broke don’t fix it,” seems to apply. Anyway, the client needed to perform address verification checks through Ajax calls to a web-service when a form is submitted. Since the service sometimes takes a little while to respond, the client wanted to display a ThickBox, warning the user of the ongoing checks, then, depending on the result, either continue to the next page, or allow the user to change their address.
Since the user has submitted the form and is now waiting for the next page, I chose to have jQuery call the web service with the async=false option of the ajax() function. (Not the best choice, looking back). Everything worked well: Firefox, Safari and Chrome all worked as expected, and then we tested in IE. Internet Explorer would not pop up the initial ThickBox (‘pleaseWait’ below), until the Ajax queries had completed, unless I put an alert in place between them, then the ThickBox would appear as intended.
function myFunc(theForm) {
...
tb_show("Please …javascript jquery
Multi-store Architecture for Ecommerce

By Steph Skardal
February 29, 2012
Something that never seems to go out of style in ecommerce development is the request for multi-site or multi-store architecture running on a given platform. Usually there is interest in this type of setup to encourage build-out and branding of unique stores that have shared functionality.

![]()

A few of Backcountry.com’s stores driven by a multi-store architecture, developed with End Point support.
End Point has developed several multi-store architectures on open source ecommerce platforms, including Backcountry.com (Interchange/Perl), College District (Interchange/Perl), and Fantegrate (Spree/Rails). Here’s an outline of several approaches and the advantages and disadvantages for each method.
Option #1: Copy of Code Base and Database for Every Site
This option requires multiple copies of the ecommerce platform code base, and multiple database instances connected to each code base. The stores could even be installed on different servers. This solution isn’t a true multi-store architecture, but it’s certainly the first stop for a quick and dirty approach to deploy multiple stores.
The advantages to this method are:
- Special template logic doesn’t have to be written per site — the …
ecommerce interchange rails spree
Rails 3 remote delete link handlers with Unobtrusive Javascript

By Brian Gadoury
February 28, 2012
I recently encountered a bug in a Rails 3 application that used a remote link_to tag to create a Facebook-style “delete comment” link using unobtrusive javascript. I had never worked with remote delete links like this before, so I figured I’d run through how I debugged the issue.
Here are the relevant parts of the models we’re dealing with:
class StoredFile < ActiveRecord::Base
has_many :comments, :dependent => :destroy
end
class Comment < ActiveRecord::Base
belongs_to :user
belongs_to :stored_file
endHere’s the partial that renders a single Comment (from the show.html.erb view for a StoredFile) along with a delete link if the current_user owns that single Comment:
<%= comment.content %> -<%= comment.user.first_name %>
<% if comment.user == current_user >
<%= link_to 'X', stored_file_comment_path(@stored_file, comment), :remote => true, :method => :delete, :class => 'delete-comment' >
<% end ->Here’s a mockup of the view with 3 comments:

At first, the bug seemed to be that the “X” wasn’t actually a link, and therefore, didn’t do anything. Clicking the “X” with Firebug enabled told a different story. There …
javascript jquery rails tips
Liquid Galaxy at the World Oceans Summit

By Gerard Drazba
February 24, 2012
Jenifer Austin Foulkes, Product Manager for Google Ocean contacted End Point for the purpose of using Liquid Galaxy as a presentation platform at ocean-centric conferences around the world. The World Oceans Summit was held at the Capella Singapore Resort, February 22nd through February 24th, 2012 and Liquid Galaxy was there: World Oceans Summit
Josh Tolley of End Point specially developed a Google Earth tour for the Liquid Galaxy featuring Hope Spots:
“Hope Spots are special places that are critical to the health of the ocean, Earth’s blue heart.”
—from the Sylvia Earle Alliance website
The Underwater Earth Seaview Project was unveiled for the first time in Singapore. Liquid Galaxy showcased some of the amazing panoramas created by the project. The panoramas are beautiful in the immersive format that a Liquid Galaxy provides.
“We’re on a mission to reveal our oceans. Why? Because the biggest threat to life in our oceans is the fact that it is out of sight and out of mind.”
—from the Underwater Earth website
Gap Kim from Google Singapore worked hard to get approvals to bring a portable Liquid Galaxy to the World Ocean Summit and also to have it subsequently installed at …
visionport event
Spring authentication plugin

By Josh Tolley
February 24, 2012
One of our clients regularly deploys Pentaho with their application, and wanted their users to be able to log in to both applications with the same credentials. We could, of course, have copied the user information from one application to another, but Pentaho, and the Spring system it uses for authentication, allows us to be much more elegant.
Spring is often described as an “application development framework”, or sometimes an “Inversion of Control container”, which essentially means that you can redefine, at run time, exactly which objects perform various services within your application. That you have to navigate a bewildering and tangled web of configuration files in order to achieve this lofty goal, and that those files suffer from all the verbosity you’d expect from the combined forces of XML and Java, normally isn’t as loudly proclaimed. Those inconveniences notwithstanding, Spring can let you do some pretty powerful stuff, like in our case, redefining exactly how a user gets authenticated by implementing a few classes and reciting the proper incantation in the configuration files.
Spring handles most of the plumbing in the Pentaho authentication process, and it all starts …
java pentaho casepointer
Downloading CSV file from Django admin

By Szymon Lipiński
February 22, 2012
Django has a very nice admin panel. The admin panel is highly extensible and there can be performed really cool enhancements. One of such things is a custom action.
For the purpose of this this article I’ve created a simple Django project with a simple application containing only one model. The file models.py looks like this:
from django.db import models
from django.contrib import admin
class Stat(models.Model):
code = models.CharField(max_length=100)
country = models.CharField(max_length=100)
ip = models.CharField(max_length=100)
url = models.CharField(max_length=100)
count = models.IntegerField()
class StatAdmin(admin.ModelAdmin):
list_display = ('code', 'country', 'ip', 'url', 'count')
admin.site.register(Stat, StatAdmin)I’ve also added a couple of rows in the database table for this model. The admin site for this model looks like this:
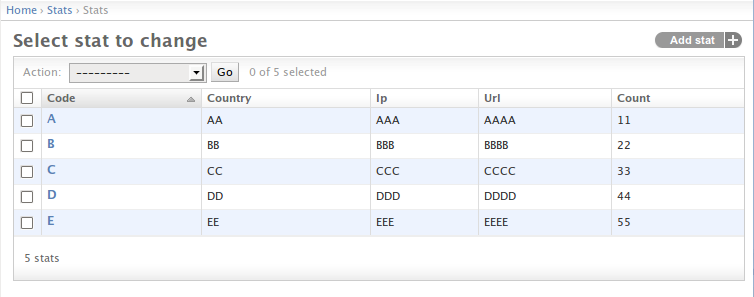
Now I want to be able to select some rows and download a CSV file right from the Django admin panel. The file should contain only the information about selected rows.
This can be done really easy with the admin actions mechanism. Over the table with rows there is the actions …
django python
Perl, UTF-8, and binmode on filehandles

By Greg Sabino Mullane
February 21, 2012

I recently ran into a Perl quirk involving UTF-8, standard filehandles, and the built-in Perl die() and warn() functions. Someone reported a bug in the check_postgres program in which the French output was displaying incorrectly. That is, when the locale was set to FR_fr, the French accented characters generated by the program were coming out as “byte soup” instead of proper UTF-8. Some other languages, English and Japanese among them, seemed to be fine. For example:
## English: "sorry, too many clients already"
## Japanese: "現在クライアント数が多すぎます"
## French expected: "désolé, trop de clients sont déjà connectés"
## French actual: "d�sol�, trop de clients sont d�j� connect�s"That last line should be very familiar to anyone who has struggled with Unicode on a command line, with those question marks on an inverted background. Our problem was that the output of the script looked like the last line, rather than the one before it. The Japanese output, despite being chock full of Unicode, does have the same problem! More on that later.
I was able to duplicate the problem easy enough by setting my locale to FR_fr and having …
perl unicode