Association Extensions in Rails for Piggybak

By Steph Skardal
October 31, 2012
I recently had a problem with Rails named scopes while working on minor refactoring in Piggybak, an open source Ruby on Rails ecommerce platform that End Point created and maintains. The problem was that I found that named scopes were not returning uncommitted or new records. Named scopes allow you to specify ActiveRecord query conditions and can be combined with joins and includes to query associated data. For example, based on recent line item rearchitecture, I wanted order.line_items.sellables, order.line_items.taxes, order.line_items.shipments to return all line items where line_item_type was sellable, tax, or shipment, respectively. With named scopes, this might look like:
class Piggybak::LineItem < ActiveRecord::Base
scope :sellables, where(:line_item_type => "sellable")
scope :taxes, where(:line_item_type => "tax")
scope :shipments, where(:line_item_type => "payment")
scope :payments, where(:line_item_type => "payment")
endHowever, while processing an order, any uncommited or new records would not be returned when using these named scopes. To work around this, I added the Enumerable select method to iterate …
ecommerce piggybak ruby rails
PostgreSQL auto_explain Module

By Szymon Lipiński
October 30, 2012
PostgreSQL has many nice additional modules, usually hidden and not enabled by default. One of them is auto_explain, which can be very helpful for bad query plan reviews. Autoexplain allows for automatic logging of query plans, according to the module’s configuration.
This module is very useful for testing. Due to some ORM features, it is hard to repeat exactly the same queries with exactly the same parameters as ORMs do. Even without ORM, many applications make a lot of different queries depending on input data and it can be painful the repeat all the queries from logs. It’s much easier to run the app and let it perform all the queries normally. The only change would be adding a couple of queries right after the application connects to the database.
At the beginning let’s see how my logs look when I run “SELECT 1” query:
2012-10-24 14:55:09.937 CEST 5087e52d.22da 1 [unknown]@[unknown] LOG: connection received: host=127.0.0.1 port=33004
2012-10-24 14:55:09.947 CEST 5087e52d.22da 2 szymon@szymon LOG: connection authorized: user=szymon database=szymon
2012-10-24 14:55:10.860 CEST 5087e52d.22da 3 szymon@szymon LOG: statement: SELECT 1;
2012-10-24 14:55 …postgres
An Encouraging LinuxFest

By Josh Williams
October 29, 2012
A few weekends ago I gave a talk at Ohio LinuxFest: Yes, You Can Run Your Business On PostgreSQL. Next Question? (slides freshly posted.) The talk isn’t as technically oriented as the ones I’ll usually give, but rather more inspirational and encouraging. It seemed like a good and reasonable topic, centered around Postgres but applicable to open source in general, and it’s something I’d been wanting to get out there for a while.
In a previous life I worked with Microsoft shops a bit more often. You know, companies that use Windows and related software pretty much exclusively. This talk was, more or less, a result of a number of conversations with those companies about open source software and why it’s a valid option. I heard a number of arguments against, some reasonable, some pretty far out there, so it felt like it’d be a good thing to gather up all of those that I’d heard over time.
These days I don’t interact with those companies so much, so I was a little worried at first that the landscape had changed enough that the talk wouldn’t really be useful any more. But after talking with a few people around the conference a …
conference database open-source postgres
Postgres system triggers error: permission denied

By Greg Sabino Mullane
October 25, 2012
This mystifying Postgres error popped up for one of my coworkers lately while using Ruby on Rails:
ERROR: permission denied: "RI_ConstraintTrigger_16410" is a system triggerOn PostgreSQL version 9.2 and newer, the error may look like this:
ERROR: permission denied: "RI_ConstraintTrigger_a_32778" is a system trigger
ERROR: permission denied: "RI_ConstraintTrigger_c_32780" is a system triggerI labelled this as mystifying because, while Postgres’ error system is generally well designed and gives clear messages, this one stinks. A better one would be something similar to:
ERROR: Cannot disable triggers on a table containing foreign keys unless superuser
As you can now guess, this error is caused by a non-superuser trying to disable triggers on a table that is used in a foreign key relationship, via the SQL command:
ALTER TABLE foobar DISABLE TRIGGERS ALL;Because Postgres enforces foreign keys through the use of triggers, and because data integrity is very important to Postgres, one must be a superuser to perform such an action and bypass the foreign keys. (A superuser is a Postgres role that has “do anything” privileges). We’ll look at an example …
database postgres rails
The truth about Google Wallet integration

By Marina Lohova
October 19, 2012
Google Wallet integration is quite a bumpy ride for every developer. I would like to describe one integration pattern that actually works. It is written in PHP for Google Wallet 2.5 API.
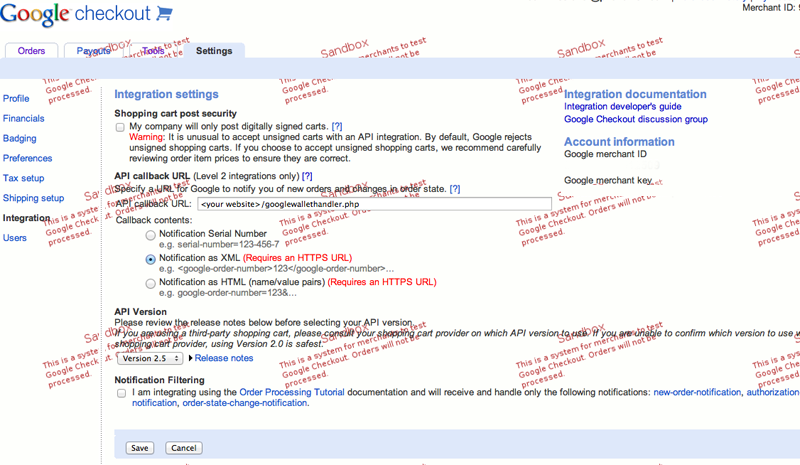
Google Merchant account settings
First, one must sign up for Google Merchant account. Once this is done, it is very important to configure the service properly on the Settings > Integration tab
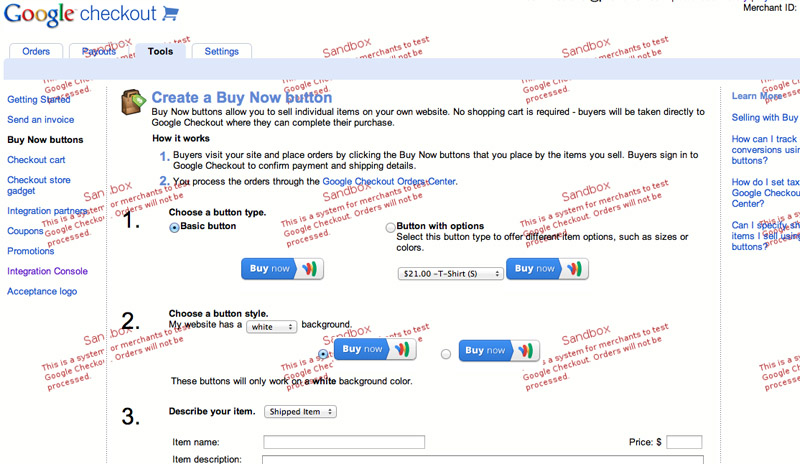
Buy now button
Buy Now buttons are the simplest form of integration. The code for the button can be obtained on the Tools > Buy Now Buttons tab.
I modified the code provided by Google to transfer information to Google Wallet server via the hidden fields on the form.
<form method="POST" action="https://sandbox.google.com/checkout/api/checkout/v2/checkoutForm/Merchant/<merchant_id>" accept-charset="utf-8">
<input type="hidden" name="item_name_1" value=""/>
<input type="hidden" name="item_description_1" value="Subscription Fees"/>
Enter Amount to Deposit:<input type="text" class="normal" size="5" name="item_price_1" value=""/>
<input type="hidden" name= …ecommerce payments php api
Case Sensitive MySQL Searches

By Brian Buchalter
October 18, 2012
MySQL’s support for case sensitive search is explained somewhat opaquely in the aptly titled Case Sensitivity in String Searches documentation. In short, it explains that by default, MySQL won’t treat strings as case sensitive when executing a statement such as:
SELECT first_name FROM contacts WHERE first_name REGEXP '^[a-z]';This simple search to look for contacts whose first name starts with a lower case letter, will return all contacts because in the default character set used by MySQL (latin1), upper and lower case letters share the same “sort value”.
UPDATE: After many helpful comments from readers, it would seem the term I should have used was collation, not sort value. The documentation for both MySQL and PostgreSQL have lengthy discussions on the topic.
Enough with the backstory, how do I perform case sensitive searches!
The docs say to convert the string representation to a binary one. This allows “comparisons [to] use the numeric values of the bytes in the operands”. Let’s see it in action:
SELECT first_name FROM contacts WHERE BINARY(first_name) REGEXP '^[a-z]';There are other strategies available, such as changing the character set being used for …
database mysql
Debugging Sinatra with racksh and pry

By Kamil Ciemniewski
October 17, 2012
One of the most beloved features of the Ruby on Rails framework is certainly its “console” facility. Ruby on Rails programmers often don’t need any debugger simply because they can view their application state in their app’s console. But what do we have at our disposal when using Sinatra?
The sheer beauty of Sinatra
Many of us who had an opportunity to play with Sinatra stand in awe of its pure simplicity. It gives you raw power as a programmer to structure a whole project however you like. It isn’t as opinionated as Ruby on Rails - in fact, there is even a framework called Padrino built upon Sinatra leveraging its unopinionated nature.
Sinatra’s way (®) was also employed in many other languages like JavaScript (through Node.js), Clojure and even in Haskell.
The elephant in the room
The above paragraph seems cool, doesn’t it? It provides a catchy and exciting marketing copy, just enough to make you a little bit curious about this whole Sinatra thing. And while Sinatra stands the test of practicality, otherwise it wouldn’t be hailed as widely as it is today, there are “gotchas” waiting just around the corner.
Almost every web application could be simplified just to this …
ruby sinatra
Piggybak Update: Line Item Rearchitecture
By Steph Skardal
October 17, 2012
Over the last couple of weeks, I’ve been involved in doing significant rearchitecture of Piggybak’s line items data model. Piggybak is an open-source mountable Ruby on Rails ecommerce solution created and maintained by End Point. A few months ago after observing a few complications with Piggybak’s order model and it’s interaction with various nested elements (product line items, shipments, payments, adjustments) and calculations, and after reviewing and discussing these complications with a couple of my expert coworkers, we decided to go in the direction of a uniform line item data model based on our success with this model for other ecommerce clients over the years (whoa, that was a long sentence!). Here, I’ll discuss some of the motiivations and an overview of the technical aspects of this rearchitecture.
Motivation
The biggest drivers of this change were a) to enable more simplified order total calculations based on uniform line items representing products, shipments, payments, etc. and b) to enable easier extensibility or hookability into the order architecture without requiring invasive overrides. For example, the code before for order totals may looked something like this: …
ecommerce piggybak ruby rails