Git branches and rebasing

By Jeff Boes
October 19, 2010
Around here I have a reputation for finding the tiniest pothole on the path to Git happiness, and falling headlong into it while strapped to a bomb …
But at least I’m dedicated to learning something each time. This time it involved branches, and how Git knows whether you have merged that branch into your current HEAD.
My initial workflow looked like this:
$ git checkout -b MY_BRANCH
(some editing)
$ git commit
$ git push origin MY_BRANCH
(later)
$ git checkout origin/master
$ git merge --no-commit origin/MY_BRANCH
(some testing and inspection)
$ git commit
$ git rebase -i origin/masterThis last step was the trip-and-fall, although it didn’t hurt me so much as launch me off my path into the weeds for a while. Once I did the “git rebase”, Git no longer knows that MY_BRANCH has been successfully merged into HEAD. So later, when I did this:
$ git branch -d MY_BRANCH
error: the branch 'MY_BRANCH' is not fully merged.As I now understand it, the history is no longer a subset of the history associated with MY_BRANCH, so Git can’t tell the two are related and refuses to delete the branch unless you supply it with -D. A relatively harmless situation, but it set off …
git
Implementing Per Item Discounts in Spree

By Sonny Cook
October 19, 2010
Discounts in Spree
For a good overview of discounts in Spree, the documentation is a good place to start. The section on Adjustments is particularly apropos.
In general, the way to implement a discount in Spree is to subclass the Credit class and attach or allow for attaching of one or more Calculators to your new discount class. The Adjustment class file has some good information on how this is supposed to work, and the CouponCredit class can be used as a template of how to do such an implementation.
What we Needed
For my purposes, I needed to apply discounts on a per Item basis and not to the entire order.
The issue with using adjustments as-is is that they are applied to the entire order and not to particular line items, so creating per line item discounts using this mechanism is not obviously straight forward. The good news it that there is nothing actually keeping us from using adjustments in this manner. We just need to modify a few assumptions.
Implementation Details
This is going to be a high-level description of what I did with (hopefully) enough hints about what are probably the important parts to point someone who wants to do something similar in the same direction. …
ecommerce ruby rails spree
SEO friendly redirects in Interchange

By Richard Templet
October 15, 2010
In the past, I’ve had a few Interchange clients that would like the ability to be able to have their site do a SEO friendly 301 redirect to a new page for different reasons. It could be because either a product had gone out of stock and wasn’t going to return or they completely reworked their url structures to be more SEO friendly and wanted the link juice to transfer to the new URLs. The normal way to handle this kind of request is to set up a bunch of Apache rewrite rules.
There were a few issues with going that route. The main issue is that to add or remove rules would mean that we would have to restart or reload Apache every time a change was made. The clients don’t normally have the access to do this so it meant they would have to contact me to do it. Another issue was that they also don’t have the access to modify the Apache virtual host file to add and remove rules so again, they would have to contact me to do it. To avoid the editing issue, we could have put the rules in a .htaccess file and allow them to modify it that way, but this can present its own challenges because some text editors and FTP clients don’t handle hidden files very well. The other issue is that even …
interchange seo
Conventions

By Jon Jensen
October 14, 2010
Written and spoken communication involve language, and language builds on a lot of conventions. Sometimes choosing one convention over another is an easy way to reduce confusion and help you communicate more effectively. Here are a few areas I’ve noticed unnecessary confusion in communication, and some suggestions on how we can do better.
2-dimensional measurements
Width always comes first, followed by height. This is a longstanding printing and paper measurement custom. 8.5” x 11” = 8.5 inches wide by 11 inches high. Always. Of course it never hurts to say specifically if you’re the one writing: 8.5” wide x 11” high, or 360px wide x 140px high.
If a third dimension comes into play, it goes last: 10” (horiz.) x 10” (vertical) x 4” (deep).
Dates
In file names, source code, databases, or spreadsheets, use something unambiguous and easily sortable. A good standard is ISO 8601, which orders dates from most significant to least significant, that is, year-month-day, or YYYY-MM-DD. For example, 2010-01-02 is January 2, 2010. If you need to store a date as an integer or shave off 2 characters, the terser YYYYMMDD is an option with the same benefits but a little less readability.
For easier …
tips
Providing Database Handle for Interchange Testing

By Chris Kershaw
October 14, 2010
I’ve recently begun using the test driven development approach to my projects using Perl’s Test::More module. Most of my projects lately have been with Interchange which has some hurdles to get around as far as test driven development is concerned. Primarily this is because Interchange runs as a daemon and provides some readily available utilites like the database handle. This method is not available to our tests, so they need to be made available as discussed below.
I develop Usertags, GlobalSubs and ActionMaps where applicable as it helps keep the separation of business logic and views clear. I generally organize these to call a function within a Perl module so they can be tested properly. Most of these tags involve some sort of connection with the database to present information to the user in which I uses the Interchange ::database_exists_ref method.
When it comes to testing I want to ensure that the test script invokes the same method. Otherwise, your script will not be testing the code as its used in production.
Let’s say you are building a Perl module that looks something like this:
package YourMagic;
use strict;
sub do_something {
my ($opt) = @_;
# some code …interchange perl testing
Red Hat SELinux policy for mod_wsgi

By Adam Vollrath
October 13, 2010
Using SELinux, you can safely grant a process only the permissions it needs to perform its function, and no more. Linux distributions provide policies to enforce these limits on most software they package, but many aren’t covered. We’ve made allowances for mod_wsgi on RHEL and CentOS 5 by extending Apache httpd’s SELinux policy.
It seems the SELinux policy for Apache httpd is twice as large as any other package’s. The folks at Red Hat have put a lot of work into making sure that attackers who manage to exploit httpd can’t break out to the rest of your system, while still allowing the flexibility to serve most applications. Consult the httpd_selinux man page if messages in audit.log coincide with your error.
File Contexts
If you’ve created files and/or directories in /etc/httpd, make sure they have the proper file contexts so the daemon can read them:
# restorecon -vR /etc/httpdhttpd can only serve files with an explicitly allowed file context. Configure the context of files and directories within your production code base using the semanage command:
# semanage fcontext --add --ftype -- --type httpd_sys_content_t "/home/projectname/live(/.*)?"
# semanage fcontext …django hosting python redhat security selinux
Keep Your Tools Sharp To Avoid Personal Technical Debt

By Brian Gadoury
October 12, 2010
One of the things that really struck me when I started working here at End Point was how all of my co-workers possessed surprisingly deep knowledge of just about every tool they used in their work. Now, I’ve been developing web applications on Linux for years and I’ve certainly read my fair share of man pages. But, I’ve always tended to learn just enough about a specific tool or tool set to get my job done. That is, until I started working here.
I’ve always thought that a thirst for knowledge and an inquisitive nature are both prerequisites for becoming a good developer. Did you take apart your toys when you were a child because you wanted to see how they worked? Were you even able to put some of them back together such that they still worked?
I did, too. I wanted to know how everything worked. But, somewhere along the line I seem to have decided that there “wasn’t time to learn about that” (where “that” was git rebase or mock objects in unit testing, or NoSQL databases like Cassandra) because I live and work in the real world. I have projects with milestones and deadlines. I have meetings and code to review. I have a life outside the office. These are common constraints, and I had …
tips
Spree Sample Data: Orders and Checkout

By Steph Skardal
October 11, 2010
A couple of months ago, I wrote about setting up Spree sample data in your Spree project with fixtures to encourage consistent feature development and efficient testing. I discussed how to create sample product data and provided examples of creating products, option types, variants, taxonomies, and adding product images. In this article, I’ll review the sample order structure more and give an example of data required for a sample order.
The first step for understanding how to set up Spree order sample data might require you to revisit a simplified data model to examine the elements that relate to a single order. See below for the interaction between the tables orders, checkouts, addresses, users, line items, variants, and products. Note that the data model shown here applies to Spree version 0.11 and there are significant changes with Spree 0.30.
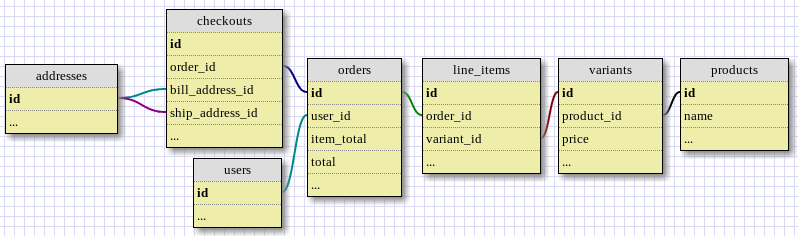
Basic diagram for Spree order data model.
The data model shown above represents the data required to build a single sample order. An order must have a corresponding checkout and user. The checkout must have a billing and shipping address. To be valid, an order must also have line items that have variants and products. Here’s an example of …
ecommerce rails spree