jQuery Performance Tips: Slice, Filter, parentsUntil

By Steph Skardal
February 4, 2013
I recently wrote about working with an intensive jQuery UI interface to emulate highlighting text. During this work, I experimented with and worked with jQuery optimization quite a bit. In the previous blog article, I mentioned that in some cases, the number of DOM elements that I was traversing at times exceeded 44,000, which caused significant performance issues in all browsers. Here are a few things I was reminded of, or learned throughout the project.
- console.profile, console.time, and the Chrome timeline are all tools that I used during the project to some extent. I typically used console.time the most to identify which methods were taking the most time.
- Caching elements is a valuable performance tool, as it’s typically faster to run jQuery calls on a cached jQuery selector rather than reselecting the elements. Here’s an example:
| Slower | Faster |
|---|---|
//Later in the code
$('.items').do_something();
| //On page load
var cached_items = $('.items');
//Later in the code
cached_items.do_something();
|
- The jQuery .filter operator came in handy, and gave a bit of a performance bump in some cases.
| Slower | Faster |
|---|---|
$('.highlighted');
| cached_items.filter('.highlighted');
|
javascript jquery rails
How to Apply a Rails Security Patch

By Brian Buchalter
January 29, 2013
With the announcement of CVE-2013-0333, it’s time again to secure your Rails installation. (Didn’t we just do this?) If you are unable to upgrade to the latest, secure release of Rails, this post will help you apply a Rail security patch, using CVE-2013-0333 as an example.
Fork Rails, Patch
The CVE-2013-0333 patches so kindly released by Michael Koziarski are intended for use with folks who have forked the Rails repository. If you are unable to keep up with the latest releases, a forked repo can help you manage divergences and make it easy to apply security patches. Unfortunately, you cannot use wget to download the attached patches directly from Google Groups, so you’ll have to do this in the browser and put the patch into the root of your forked Rails repo. To apply the patch:
cd $RAILS_FORK_PATH
git checkout $RAILS_VERSION
# Download attachment from announcement in browser, sorry no wget!
git am < $CVE.patchYou should see the newly committed patch(es) at the HEAD of your branch. Push out to GitHub and then bundle update rails on your servers.
Patching without Forks
If you are in the unfortunate case where there have been modifications or patches applied informally outside …
rails security
Evading Anti-Virus Detection with Metasploit
By Brian Buchalter
January 28, 2013
This week I attended a free, technical webinar hosted by David Maloney, a Senior Software Engineer on Rapid7’s Metasploit team, where he is responsible for development of core features for the commercial Metasploit editions. The webinar was about evading anti-virus detection and covered topics including:
- Signatures, heuristics, and sandboxes
- Single and staged payloads
- Executable templates
- Common misconceptions about encoding payloads
- Dynamically creating executable templates
After Kaspersky Lab broke news of the “Red October” espionage malware package last week, I thought this would be an interesting topic to learn more about. In the post, Kaspersky is quoted saying, “the attackers managed to stay in the game for over 5 years and evade detection of most antivirus products while continuing to exfiltrate what must be hundreds of terabytes by now.”
Separating Exploits and Payloads
Vocabulary in the world of penetration testing may not be familiar to everyone, so let’s go over a few terms you may see.
- Vulnerability: A bug or design flaw in software that can be exploited to allow unintended behavior
- Exploit: Software which takes advantage of a vulnerability allowing arbitrary …
security
JavaScript-driven Interactive Highlighting
By Steph Skardal
January 25, 2013

An example of highlighted text, by sergis on Flickr
One project I’ve been involved in for almost two years here at End Point is the H2O project. The Ruby on Rails web application behind H2O serves as a platform for creating, editing, organizing, consuming and sharing course materials that is used by professors and their students.
One of the most interesting UI elements of this project is the requirement to allow highlighting and annotating text interactively. For example, when one reads a physical textbook for a college course, they may highlight and mark it up in various ways with different colors and add annotated text. They may also highlight a section that is particularly important for an upcoming exam, or they may highlight another section with a different color and notes that may be needed for a paper.
The H2O project has required support for digitizing interactive highlighting and annotating. Since individual text is not selectable as a DOM element, each word is wrapped into an individual DOM element that is selectable, hoverable, and has DOM properties that we can assign it. For example, we have the following text:
The cow jumped over the moon.
Which is manipulated to …
jquery javascript performance
Create a key pair using SSH on Windows

By Bianca Rodrigues
January 24, 2013
I recently joined End Point as a full-time employee after interning with the company since August 2012. I am part of the marketing and sales team, working out of the New York City office.
One of the frequent queries we receive from our non-technical clients is how to create an SSH key pair. This post is an introduction to using SSH on Windows for anyone who needs some clarification on this network protocol.
SSH stands for Secure Shell, which is used to provide secure access to remote systems. PuTTY is an SSH client that is available for Windows. Using the concept of “key-based” SSH logins, you can avoid the usual username/password login procedure, meaning only those with a valid private/public key pair can log in. This allows for a more secure system.
To begin, install PuTTYgen, PuTTY and Pageant on your Windows system:
Let’s focus on PuTTYgen – used to create a private/public key pair.
- After downloading PuTTYgen, run puttygen.exe
- In the “Parameters” — “Type of key” section, make sure “SSH-2 RSA” is selected:
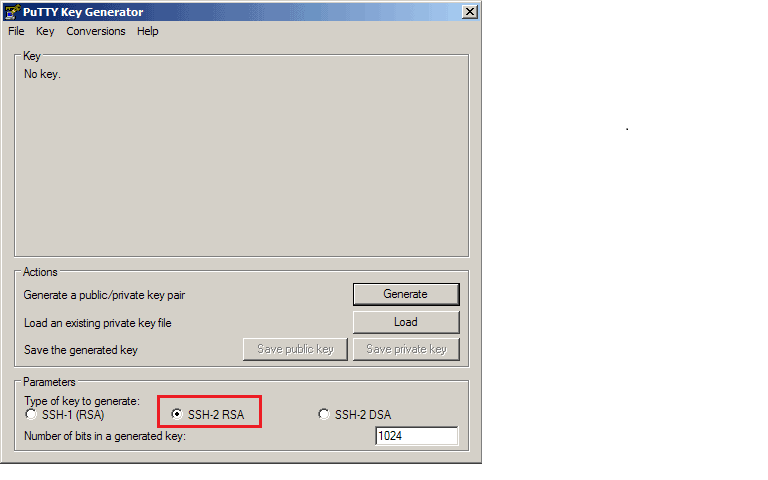
*Note: SSH-2 RSA is what End Point recommends. The others work as well, and your business may have some reason to use them instead. …
security
CSS sprites: The easy way?

By Richard Templet
January 21, 2013
I’ve always been interested in the use of CSS sprites to speed up page load times. I haven’t had a real chance to use them yet but my initial reaction was that sprites would be quite painful to maintain. In my mind, you would have to load up the sprite into Gimp or Photoshop, add the new image and then create the css with the right coordinates to display the image. Being a guy with very little image editing skills, I felt that managing multiple images frequently would be quite time consuming. Recently, I was dealing with some page load times for a client and the use of sprites for the product listing pages came up as an option to speed them up. I knew the client wouldn’t have time to create sprites for this so I went searching for a command line tool that would allow me to create sprites. I was quite happy when I stumbled upon Glue.
Glue is free program that will take a directory of images and create a png sprite and a css file with the associated CSS classes. It has a ton of useful options. A few of the ones I thought were handy was being able to prefix the path to the image with a url instead of a relative path, being able to downgrade the png format to png8 to make the file …
css performance tools
Camp tools

By Jeff Boes
January 14, 2013
Devcamps are such a big part of my everyday work that I can’t imagine life without them. Over the years, I developed some short-cuts in navigating camps that I also can’t live without: I share them below.
function camp_top() {
if [ -n "$1" ]
then
cd ~/camp${1}
elif [[ $(pwd) =~ 'camp' ]]
then
until [[ $(basename $(pwd)) =~ '^camp[[:digit:]]+' ]]
do
if [[ $(pwd) =~ 'camp' ]]
then
cd ..
else
break
fi
done
fi
}
alias ct='camp_top; pwd'
function cat_root() {
camp_top $*
cd catalogs/* >/dev/null
}
alias cr='cat_root; pwd'
function pages_root() {
cat_root $*
cd pages >/dev/null
}
alias pr='pages_root; pwd'
function what_camp() {
c=$( camp_top $* 2> /dev/null; basename $( pwd ))
echo $c
}(“cat_root” and “pages_root” are very Interchange-specific; you may find other short-cuts more useful in your particular camp.)
There’s nothing terribly ground-breaking here, but if bash is not your native shell-tongue, then you might find these useful.
What I do is to stash these somewhere like “$HOME/.bash_camps”, then …
shell camps
Use Metasploit to Verify Rails is Secured from CVE-2013-0156
By Brian Buchalter
January 10, 2013
On January 8th, 2013 Aaron Patterson announced a major security vulnerability on the Rails security mailing list, affecting all releases of the Ruby on Rails framework. This vulnerability allows an unskilled attacker to execute commands remotely on any unpatched Rails web server. Unsurprisingly, it’s getting a lot of attention; Ars Technica estimates more than 200,000 sites may be vulnerable. With all the hype, it’s important to separate the facts from the fiction and use the attacker’s own tools to verify your site is secure.
Within 36 hours of the announcement of CVE-2013-0156, the developers at Rapid7 released a metasploit exploit module. Metasploit lowers the barriers to entry for attackers, making the whole process a point and click affair with a slick web GUI. Fortunately, the Rails security team has provided many easy to implement mitigation options. But, how do know you’ve really closed the vulnerability, particularly to the most automated and unskilled attacks? No better way than to try and exploit yourself.
It’s best to scan your unpatched site first so you can be certain the scan is working as expected and you don’t end up with a false positive that you’ve eliminated the …
ruby rails security