List Google Pages Indexed for SEO: Two Step How To

By Steph Skardal
December 11, 2009
Whenever I work on SEO reports, I often start by looking at pages indexed in Google. I just want a simple list of the URLs indexed by the GOOG. I usually use this list to get a general idea of navigation, look for duplicate content, and examine initial counts of different types of pages indexed.
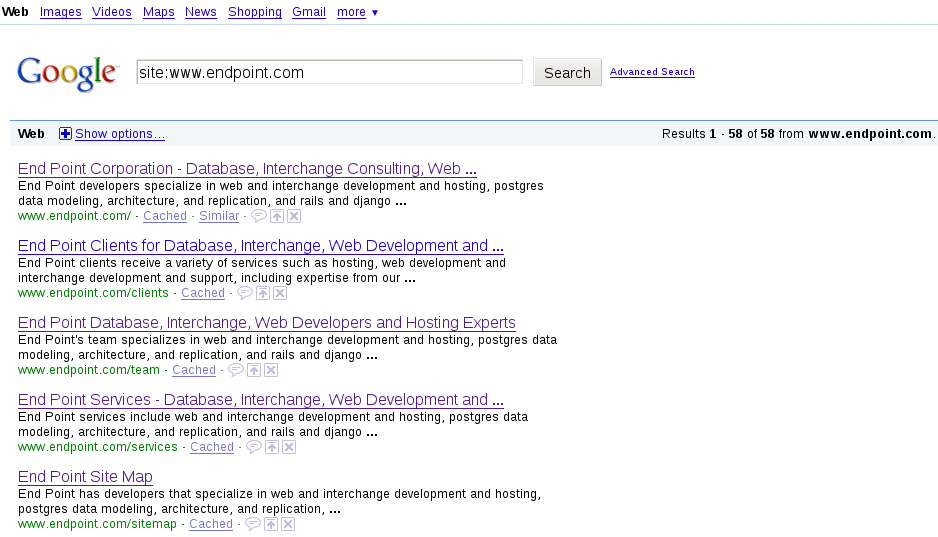
Yesterday, I finally got around to figuring out a command line solution to generate this desired indexation list. Here’s how to use the command line using http://www.endpoint.com/ as an example:
Step 1
Grab the search results using the “site:” operator and make sure you run an advanced search that shows 100 results. The URL will look something like: https://www.google.com/search?num=100&as_sitesearch=www.endpoint.com
But it will likely have lots of other query parameters of lesser importance [to us]. Save the search results page as search.html.
Step 2
Run the following command:
sed 's/<h3 class="r">/\n/g; s/class="l"/LINK\n/g' search.html | grep LINK | sed 's/<a href="\|" LINK//g'There you have it. Interestingly enough, the order of pages can be an indicator of which pages rank well. Typically, pages with higher PageRank will be near …
seo
Multiple links to files in /etc

By Jon Jensen
December 11, 2009
I came across an unfamiliar error in /var/log/messages on a RHEL 5 server the other day:
Dec 2 17:17:23 <em>X</em> restorecond: Will not restore a file with more than one hard link (/etc/resolv.conf) No such file or directorySure enough, ls showed the inode pointed to by /etc/resolv.conf having 2 links. What was the other link?
# find /etc -samefile resolv.conf
/etc/resolv.conf
/etc/sysconfig/networking/profiles/default/resolv.conf
# ls -lai /etc/resolv.conf /etc/sysconfig/networking/profiles/default/resolv.conf
1526575 -rw-r--r-- 2 root root 69 Nov 30 2008 /etc/resolv.conf
1526575 -rw-r--r-- 2 root root 69 Nov 30 2008 /etc/sysconfig/networking/profiles/default/resolv.confI’ve worked with a lot of RHEL/CentOS 5 servers and hadn’t ever dealt with these network profiles. Kiel guessed it was probably a system configuration tool that we never use, and he was right: Running system-config-network (part of the system-config-network-tui RPM package) creates the hardlinks for the default profile.
/etc/hosts gets the same treatment as /etc/resolv.conf.
I suppose SELinux’s restorecond doesn’t want to apply any context changes because its rules are based on filesystem paths, …
hosting redhat security
CakePHP Infinite Redirects from Auto Login and Force Secure
By Steph Skardal
December 10, 2009
Lately, Ron, Ethan, and I have been blogging about several of our CakePHP learning experiences, such as incrementally migrating to CakePHP, using the CakePHP Security component, and creating CakePHP fixtures for HABTM relationships. This week, I came across another blog-worthy topic while troubleshooting for JackThreads that involved auto login, requests that were forced to be secure, and infinite redirects.

Ack! Users were experiencing infinite redirects!
The Problem
Some users were seeing infinite redirects. The following use cases identified the problem:
- Auto login true, click on link to secure or non-secure homepage => Whammy: Infinite redirect!
- Auto login false, click on link to secure or non-secure homepage => No Whammy!
- Auto login true, type in secure or non-secure homepage in new tab => No Whammy!
- Auto login false, type in secure or non-secure homepage in new tab => No Whammy!
So, the problem boiled down to an infinite redirect when auto login customers clicked to the site through a referer, such as a promotional email or a link to the site.
Identifying the Cause of the Problem
After I applied initial surface-level debugging without success, I decided to add …
php
Cisco PIX mangled packets and iptables state tracking
By Jon Jensen
December 4, 2009
Kiel and I had a fun time tracking down a client’s networking problem the other day. Their scp transfers from their application servers behind a Cisco PIX firewall failed after a few seconds, consistently, with a connection reset.
The problem was easily reproducible with packet sizes of 993 bytes or more, not just with TCP but also ICMP (bloated ping packets, generated with ping -s 993 $host). That raised the question of how this problem could go undetected for their heavy web traffic. We determined that their HTTP load balancer avoided the problem as it rewrote the packets for HTTP traffic on each side.
Kiel narrowed the connect resets down to iptables’ state-tracking considering packets INVALID, not ESTABLISHED or RELATED as they should be.
Then he found via tcpdump that the problem was easily visible in scp connections when TCP window scaling adjustments were made by either side of the connection. We tried disabling window scaling but that didn’t help.
We tried having iptables allow packets in state INVALID when they were also ESTABLISHED or RELATED, and that reduced the frequency of terminated connections, but still didn’t eliminate them entirely. (And it was a kludge we …
hosting redhat security
Iterative Migration of Legacy Applications to CakePHP

By Ethan Rowe
December 3, 2009
As Steph noted, we recently embarked on an adventure with a client who had a legacy PHP app. The app was initially developed in rapid fashion, with changing business goals along the way. Some effort was made at the outset with this vanilla PHP app to put key business logic in classes, but as often happens over time the cleanliness of those classes degraded. While much of the business rules and state management (i.e. database manipulation, session wrangling, authentication/access-control, etc.) were kept separate from the “views” (the PHP entry pages), the classes themselves became tightly coupled, overburdened with myriad responsibilities, etc.
This was a far cry from the stereotypical spaghetti PHP app, but nevertheless it needed some reorganization; all but the smallest changes inevitably required touching a wide range of classes and pages, and the code would only grow more brittle unless some serious refactoring took place.
We determined at the outset that getting the application moved into an established MVC framework would be of great benefit, and further determined that CakePHP would be a good choice. (This is the point where anybody reading will inevitably ask in comments …
php
Rails Ecommerce Product Optioning in Spree
By Steph Skardal
December 2, 2009
A couple of months ago, I worked on an project for Survival International that required two-dimensional product optioning for products. The shopping component of the site used Spree, an open source rails ecommerce project that End Point previously sponsored and continues to support. Because the Spree project is quickly evolving, we wanted to implement a custom solution that would “stand the test of time” and work with new releases. I worked with the existing data structures and functionality as much as possible. The product optioning implementation discussed in this article should translate to other ecommerce platforms as well.

Here’s what I mean when I say “two dimensional product optioning”.
The first step to extending the core ecommerce functionality was to understand the data model. A single product “has many” option types (size, color). An option type “has many” option values (size: small, medium, large). Each product also “has many” variants. Each variant was tied to an option value for each product option type. For example, each variant would requires a corresponding size and color option value in the example above. Ideally, each variant represents a unique size and color …
ecommerce rails spree
RCS vs. Git for quick versioning

By Greg Sabino Mullane
December 2, 2009
As a consultant, I’m often called to make changes on production systems—sometimes in a hurry. One of my rules is to document all changes I make, no matter how small or unimportant they may seem. In addition to local notes, I always check in any files I change, or might change in the future, into version control. In the past, I would always use RCS. However, Jon Jensen challenged me to rethink my automatic use of RCS and give Git a try for this.
This makes sense on some levels. We use Git for most everything here at End Point, and it is our preferred version control system. I still use other systems: there are some clients and projects that require the use of Subversion, Mercurial, and even CVS. The advantage of Git for quick one off checkins is that, similar to RCS, there is no central repository, and setup is extremely easy.
As an example, one of the files I often check into version control is postgresql.conf, the main configuration file for the Postgres database. Before I even edit the file, I’ll check it in, so the sequence of events looks like this:
mkdir RCS
ci -l postgresql.conf
edit postgresql.confThe creation of the RCS directory is optional but recommended. RCS (which …
git
Using The Security Component and validatePost in CakePHP Gotcha
By Steph Skardal
December 2, 2009
Recently, Ron, Ethan, and I worked on a JackThreads project. We are in the process of moving JackThreads’ legacy PHP application to the CakePHP framework in addition to introducing new functionality for this project.
Several of the pages require secure requests:
- the home page (where users log in or create accounts)
- the login page
- the “invite” page (where users create an account)
- the checkout page
We referred to this article that discusses using the security component in CakePHP. Although this article covered the basics, we extended the concepts of the article by creating a CakePHP component with the custom security functionality to force a secure request and includes query string parameters. Below are the contents of the component that was created:
class StephsSecurityComponent extends Object {
var $components = array('Security');
function forceSecure($args) {
$this->Security->blackHoleCallback = 'forceSSL';
$this->Security->requireSecure($args);
}
function forceSSL($controller) {
$redirect_location = 'https://'.HTTPS_HOST.$controller->here;
$params = $controller->params[ …php