Spree and Authorize.Net: Authorization and Capture Quick Tip

By Steph Skardal
April 26, 2010
Last week I did a bit of reverse engineering on payment configuration in Spree. After I successfully setup Spree to use Authorize.net for a client, the client was unsure how to change the Authorize.Net settings to perform an authorize and capture of the credit card instead of an authorize only.
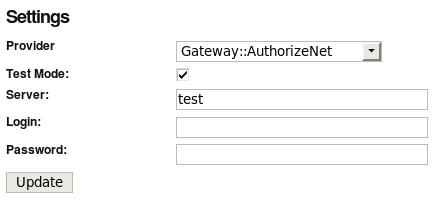
The requested settings for an Authorize.Net payment gateway on the Spree backend.
I researched in the Spree documentation for a bit and then sent out an email to the End Point team. Mark Johnson responded to my question on authorize versus authorize and capture that the Authorize.Net request type be changed from “AUTH-ONLY” to “AUTH_CAPTURE”. So, my first stop was a grep of the activemerchant gem, which is responsible for handling the payment transactions in Spree. I found the following code in the gem source:
# Performs an authorization, which reserves the funds on the customer's credit card, but does not
# charge the card.
def authorize(money, creditcard, options = {})
post = {}
add_invoice(post, options)
add_creditcard(post, creditcard)
add_address(post, options)
add_customer_data(post, options)
add_duplicate_window(post)
commit('AUTH_ONLY', money, post)
end
# …ecommerce rails spree
jQuery UI Sortable Tips

By Chris Kershaw
April 23, 2010
I was recently tasked with developing a sorting tool to allow Paper Source to manage the sort order in which their categories are displayed. They had been updating a sort column in a database column but wanted a more visual aspect to do so. Due to the well-received feature developed by Steph, it was decided that they wanted to adapt their upsell interface to manage the categories. See here for the post using jQuery UI Drag Drop.
The only backend requirements were that the same sort column was used to drive the order. The front end required the ability to drag and drop positions within the same container. The upsell feature provided a great starting point to begin the development. After a quick review I determined that the jQuery UI Sortable function would be more favorable to use for the application.
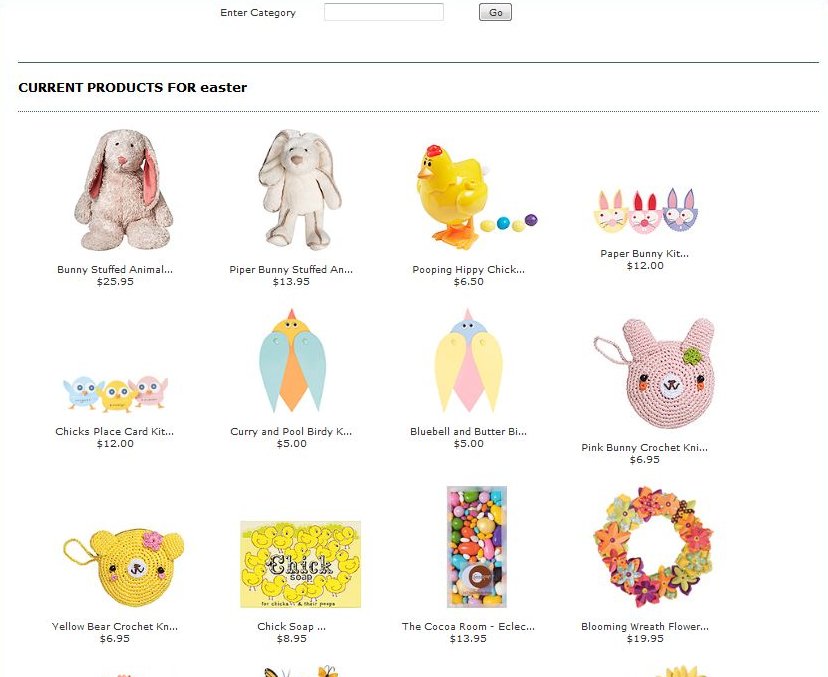
Visual feedback was used to display the sorting in action with:
// on page load
$('tr.the_items td').sortable({
opacity: 0.7,
helper: 'clone',
});
// end on page load
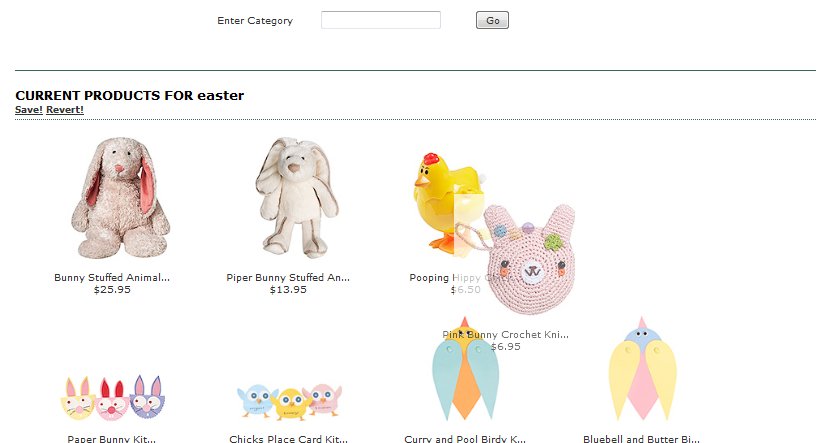
Secondly I reiterate “jQuery UI Event Funtionality = Cool”
I only needed to use one function for this application to do the arrange the sorting values once the thumbnail had been dropped. This code …
browsers javascript jquery
PostgreSQL at LinuxFest Northwest

By Selena Deckelmann
April 23, 2010
This is my third year driving up to Bellingham for LinuxFest Northwest, and I’m excited to be presenting two talks about PostgreSQL there. Adrian Klaver is one of the organizers of the conference, and has always been a huge supporter of PostgreSQL. He has gone out of his way to have a track of content about our favorite database.
I’ll be presenting an introduction to Bucardo and co-hosting a talk about new features in version 9.0 of PostgreSQL with Gabrielle Roth.
Talking about Bucardo and replication is always a blast. The last time I gave this talk to a packed house in Seattle, so I’m hoping for another lively discussion about the state of replication in PostgreSQL.
conference postgres bucardo
Using charge tag in Interchange’s profiles, and trickiness with logic and tag interpolation order

By Ron Phipps
April 22, 2010
One of the standard ways to charging in older versions of the Interchange demo was to do the charging from a profile using the &charge command. New versions of the demo store do the charging from log_transaction once the order profiles have finished, so it is not an issue there. I’ve come across quite a few catalogs where the &charge command is replaced with the [charge] tag wrapped in if-then-else blocks in an order profile. It had been so long since I had used &charge so I needed to lookup how options are passed to it, which may be why people tend to use the tag version instead of the &charge command. The problem here is that Interchange tags interpolate before any of the profile specifications execute, so if you have a [charge] tag in an order profile, it executes before any of the other checks, such as validation of fields.
Here’s a stripped down example of where a profile will have tags executed before the other profile checks:
lname=required Last name required
fname=required First name required
&fatal=yes
&credit_card=standard keep
[charge route="[var MV_PAYMENT_MODE]" amount="[scratch some_total_calculation]"]
&final=yesIn this …
ecommerce interchange open-source
Restoring individual table data from a Postgres dump

By Greg Sabino Mullane
April 20, 2010
Recently, one of our clients needed to restore the data in a specific table from the previous night’s PostgreSQL dump file. Basically, there was a UPDATE query that did not do what it was supposed to, and some of the columns in the table were irreversibly changed. So, the challenge was to quickly restore the contents of that table.
The SQL dump file was generated by the pg_dumpall command, and thus there was no easy way to extract individual tables. If you are using the pg_dump command, you can specify a “custom” dump format by adding the -Fc option. Then, pulling out the data from a single table becomes as simple as adding a few flags to the pg_restore command like so:
$ pg_restore --data-only --table=alpha large.custom.dumpfile.pg > alpha.data.pgOne of the drawbacks of using the custom format is that it is only available on a per-database basis; you cannot use it with pg_dumpall. That was the case here, so we needed to extract the data of that one table from within the large dump file. If you know me well, you might suspect at this point that I’ve written yet another handy perl script to tackle the problem. As tempting as that may have been, time was of the essence, and the …
open-source postgres backups
Authlogic and RESTful Authentication Encryption
By Steph Skardal
April 19, 2010
I recently did a bit of digging around for the migration of user data from RESTful authentication to Authlogic in Rails. My task was to implement changes required to move the application and data from RESTful Authentication to Authlogic user authentication.
I was given a subset of the database dump for new and old users in addition to sample user login data for testing. I didn’t necessarily want to use the application to test login functionality, so I examined the repositories here and here and came up with the two blocks of code shown below to replicate and verify encryption methods and data for both plugins.
RESTful Authentication
user = User.find_by_email('test@endpoint.com')
key = REST_AUTH_SITE_KEY
actual_password = "password"
digest = key
REST_AUTH_DIGEST_STRETCHES.times { digest = Digest::SHA1.hexdigest([digest, user.salt, actual_password, key].join('--')) }
# compare digest and user.crypted_password here to verify password, REST_AUTH_SITE_KEY, and REST_AUTH_DIGEST_STRETCHESNote that the stretches value for RESTful authentication defaults to 10, but it can be adjusted. If no REST_AUTH_SITE_KEY is provided, the value defaults to an empty string. …
ecommerce rails rest api
A decade of change in our work

By Jon Jensen
April 16, 2010
Lately I’ve been looking back a bit at how things have changed in our work during the past decade. Maybe I’m a little behind the times since this is a little like a new year’s reflection.
Since 2000, in our world of open source/free software ecommerce and other Internet application development, many things have stayed the same or become more standard.
The Internet is a completely normal part of people’s lives now, in the way TV and phones long have been.
Open source and free software is a widely-used and accepted part of the software ecosystem, used on both servers and desktops, at home and in companies of all sizes. Software licensing differences are still somewhat arcane, but the more popular options are now fairly widely-known.
Many of today’s major open source software systems key to Internet infrastructure and application development were already familiar in 2000:
-
the GNU toolset, Linux (including Red Hat and Debian), FreeBSD, OpenBSD
-
Apache, mod_ssl (the RSA patent expired in September 2000, making it freely usable)
-
PostgreSQL, MySQL, *DBM
-
Perl and CPAN, Python, PHP, Ruby (though little known then)
-
Interchange (just changed from MiniVend)
-
JavaScript
-
Sendmail, …
community ecommerce
Tip: Find all non-UTF-8 files

By David Christensen
April 9, 2010
Here’s an easy way to find all non-UTF-8 files for later perusal:
find . -type f | xargs -I {} bash -c "iconv -f utf-8 -t utf-16 {} &>/dev/null || echo {}" > utf8_failI’ve needed this before for converting projects over into UTF-8; obviously certain files are going to be binary and will show up in this list, so manual vetting will need to be done before converting all your images over into UTF-8.
hosting interchange tips