Implementing business logic with Domain-Driven Design

By Kevin Campusano
April 21, 2026

Photo by Bimal Gharti Magar, 2026.
This is part 2 of a series of blog posts on Domain-Driven Design:
Domain-Driven Design is an approach to software development that focuses on, as Eric Evans puts it, “tackling the complexity in the heart of software”. And what is in the heart of software? The business domain in which it operates. Or more specifically: a model of it, made of code. That is, the code that implements the business logic that comes into play when solving problems within the realm of a particular business activity.
DDD is not just about writing code though. It’s a whole methodology that touches on business needs, requirements gathering, organizational dynamics, high level architectural design, and lower level patterns for implementing software intensive systems.
As a result, DDD offers a treasure trove of concepts, patterns and tools that can be applied to any software project, regardless of the size and complexity.
In this series of blog posts we’re going to explore many aspects of DDD. We will be following the structure laid out by Vlad Khononov’s excellent book on the topic “Learning Domain-Driven Design: Aligning Software Architecture and Business Strategy”. So you can think of this series as a summary of that book. An abridged version that can serve as a review for anybody who has read it; but also as an entry point for people who are new to DDD.
Table of contents
- Implementing business logic with Domain-Driven Design
Section 5: Implementing simple business logic
Now that we’ve explored DDD’s higher level system design concepts, it’s time to zoom in and start looking at how to implement business logic: the most important part of software. We will start by discussing two patterns that are ideal for implementing simple business logic: transaction script and active record.
Transaction script
According to Martin Fowler, the transaction script pattern “organizes business logic by procedures where each procedure handles a single request from the presentation.”
For most programmers that have experience with procedural languages, the transaction script is easy to grasp. This pattern is about conceptualizing a system as a collection of transactions. And organizing these transactions as independent, transactional procedural scripts. Think one transaction script per use case, exposed for the users to invoke when they need to.
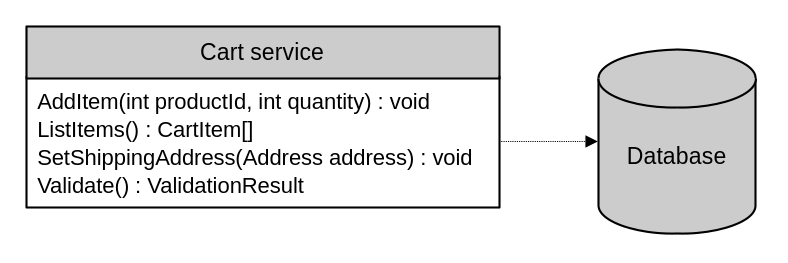
The core idea of transaction script is about putting business transactions front and center. Closely related scripts can be implemented as methods in a service class. Or you could also have a separate “service object” class for each script.
Indeed, on its own, the transaction script pattern is a simple way of organizing relatively simple domain logic. However, as we’ll see throughout the next few sections, it is also a foundational pattern that is present when implementing the more advanced ones. Also, even though the concept is simple, implementation of transaction script in the real world has to be done carefully, in order to avoid falling into common pitfalls, often related to ensuring atomicity.
class AddItemToQuote
{
// ...
// This method adds a new item to a shopping cart and records the operation
// into a log table. Both operations are done separately.
public void Run(int quoteId, int productId, int quantity)
{
_db.ExecuteSql($"""
INSERT INTO quote_items(quote_id, product_id, quantity)
VALUES ({quoteId}, {productId}, {quantity});
""");
// If some error happens after the previous command and before the one
// below, the system will be left in an inconsistent state. The new item
// would have been added to the shopping cart, but the audit log would
// not have a corresponding event.
_db.ExecuteSql($"""
INSERT INTO quote_audit_log(
quote_id, event_description, date_created
)
VALUES ({quoteId}, 'Item added to quote', CURRENT_DATE);
""");
}
}That is, a transaction script needs to actually be transactional. It needs to be atomic. Of course, each domain’s requirements will dictate how true this is, but in general, we want transaction scripts to operate as a unit, and make sure that they don’t leave the system in an inconsistent state in situations when the script fails midway through its execution.
If all the script does is interact with a relational database, it is easy to address this issue. The solution is to perform the operations within a database transaction:
class AddItemToQuoteWithTransaction
{
// ...
public void Run(int quoteId, int productId, int quantity)
{
try
{
// We can use a database transaction to fix the issue.
_db.BeginTransaction();
_db.ExecuteSql($"""
INSERT INTO quote_items(quote_id, product_id, quantity)
VALUES ({quoteId}, {productId}, {quantity});
""");
_db.ExecuteSql($"""
INSERT INTO quote_audit_log(
quote_id, event_description, date_created
)
VALUES ({quoteId}, 'Item added to quote', CURRENT_DATE);
""");
_db.CommitTransaction();
}
catch
{
_db.RollbackTransaction();
throw;
}
}
}The problem gets more complicated when the script performs a distributed transaction. That is, when it interacts with other systems which are outside of the scope of a relational database transaction. For example, interacting with the file system, or with an external web service.
class AddItemToQuoteWithDistributedTransaction
{
// ...
public void Run(int quoteId, int productId, int quantity)
{
_db.ExecuteSql($"""
INSERT INTO quote_items(quote_id, product_id, quantity)
VALUES ({quoteId}, {productId}, {quantity});
""");
// We're back to our initial problem. Any failure at this point in the
// script will have updated the shopping cart without having sent the
// notification to the external system.
_api.NotifyQuoteItemAdded(quoteId, productId, quantity);
}
}These are hard to deal with and often require very particular code to handle properly. Further in this series we’ll discuss this topic again when we talk about CQRS and the outbox pattern.
Sometimes though, the distributed transaction is not as obvious. Consider a web application that exposes an endpoint to increment the quantity of particular shopping cart items by one:
class IncrementQuoteItemQuantity
{
// ...
public void Run(int quoteItemId)
{
_db.ExecuteSql($"""
UPDATE quote_items
SET quantity = quantity + 1
WHERE id = {quoteItemId};
""");
}
}Even though that’s a single database operation, there is inter-system communication between the user’s browser and the application server; and between the application server and the database. A network outage, for example, that happens in the middle of this operation can leave the system in an inconsistent state. If it fails after it’s already submitted the UPDATE command to the database, and responds with a failure message to the client, the client might attempt to try and increase the quantity again. This would result in the increment being done two times, when actually it should have been only one.
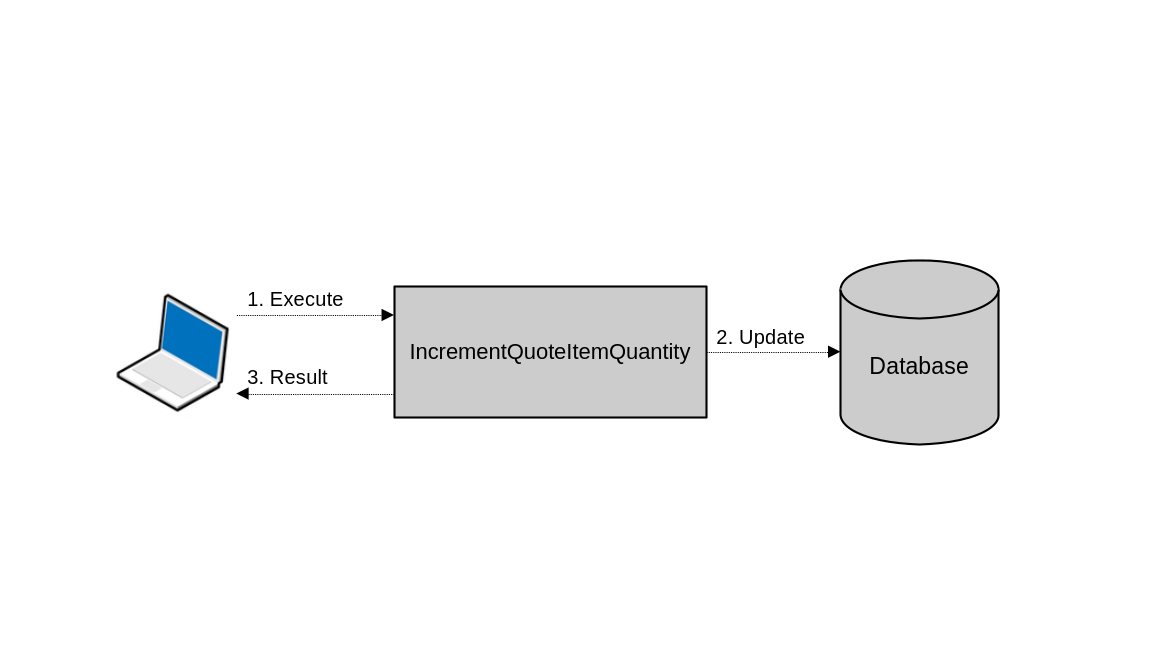
In the context of client-server applications, some transactions are distributed even though at first glance they might not seem that way. In this simple operation, there are three systems interacting over the network: The client, the application server and the database.
There are two possible ways of handling this type of situation: making the operation idempotent, or using optimistic concurrency control.
One way to make the operation idempotent, that is, to make sure that it always produces the same results, no matter how many times it’s done, is to have the caller specify the quantity to update the item to. That is, changing the operation from “add one quantity”, to “set the quantity to this”. Like so:
class IncrementQuoteItemQuantityIdempotent
{
// ...
public void Run(int quoteItemId, int quantity)
{
_db.ExecuteSql($"""
UPDATE quote_items
SET quantity = {quantity}
WHERE id = {quoteItemId};
""");
}
}On the other hand, implementing optimistic concurrency control in this scenario could be done by effectuating the record update while using the current state of the record when checking for a match. This boils down to including the expected values of the different fields in the WHERE clause. This way, the record will be updated only if it is in the state that the caller expected it to be:
class IncrementQuoteItemQuantityOptimisticConcurrency
{
// ...
public void Run(int quoteItemId, int quantity)
{
_db.ExecuteSql($"""
UPDATE quote_items
SET quantity = quantity + 1
WHERE id = {quoteItemId} AND quantity = {quantity};
""");
}
}In both cases, the caller would have to obtain the current state of the record before attempting the update operation.
Active record
Martin Fowler describes the active record pattern as “an object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.”
The main advantage of the active record pattern is that it greatly simplifies database access. Especially when leveraging ORM frameworks. With active record, you usually end up with a set of classes that closely mirror your database structure. You have one class per table, where the fields of those classes represent table columns and the instances of those classes represent individual records in those tables.
So, when the underlying data model is complex, business logic organized in transaction scripts can be augmented with active record to reduce a great deal of the complexity involved in database interactions. This is because the active record pattern takes care of mapping between database records and in-memory objects, as well as all the data retrieval and manipulation commands (I.e. the CRUD). This allows the transaction scripts to focus more on domain logic, and less on manipulating the underlying data.
class AddItemToQuoteActiveRecord
{
// ...
public void Run(int quoteId, int productId, int quantity)
{
// Active record allows us to work with objects instead of directly
// issuing database commands.
var item = new QuoteItem
{
QuoteId = quoteId,
ProductId = productId,
Quantity = quantity
};
item.Save();
}
}Of course, active records can (and should) also include domain logic. Aspects like the relationships between the domain entities, validation, complex database queries, and even the business procedures that involve them are all part of an active record object.
# This class is an Order active record. It establishes relationships with other
# entities, defines basic validation rules, and has custom queries.
class Order < ApplicationRecord
self.table_name = "orders"
enum :status, [ :pending, :paid, :shipped, :cancelled ]
enum :payment_method, [ :cash, :credit_card, :transfer ]
has_many :order_items
has_one :shipping_address
has_one :billing_address
validates :email, presence: true, email: {mode: :strict}
validates :phone, length: {minimum: 10, allow_blank: true}
scope :sorted, -> { order(created_at: :desc) }
scope :new_ones, -> { where("created_at >= ?", 1.day.ago) }
scope :have_phone, -> { where.not(phone: nil) }
scope :where_email_is, ->(email) { where("lower(email) = ?", email.downcase) }
end
# The framework augments it with data access logic, like querying:
order = Order.find(123)
expensive_items = order.order_items.where("price >= ?", 200)
orders_from_us = Order.where(country_code: "US")
new_orders = Order.new_ones.sorted
# ...and making changes:
new_order = Order.new(email: "test@email.com")
new_order.save
order.update(
shipping_number: "1234567890",
status: :shipped
)The Active Record framework from Ruby on Rails is a great implementation of the pattern that puts business logic in a centralized location while magically extending the objects with all the data access logic they need.
This is a big step up from raw transaction scripts, but still it has its own disadvantages. First, the active records can end up having too much responsibility, and grow to unmanageable sizes, especially for core business entities. Second, the active record pattern by itself does not enforce access control on its properties. Meaning that external processes can freely modify their state, potentially ignoring any business rules that could bind them.
Something else to be aware of is that when active records define little to no behavior, that is, when they don’t implement business logic, they become an anemic domain model. Active record objects that focus only on database access tasks, and higher level “service objects” that manipulate them and implement all the domain logic themselves are the hallmark of anemic domain models.
An anemic domain model may look like a full fledged domain model, with all the objects representing domain concepts and their relationships, but they are hollow. Their most important part is missing. In the next section we will see what a real domain model looks like, DDD’s definitive pattern for implementing business logic in complex subdomains.
When to use them
In some circles, the transaction script and active record patterns are considered anti patterns. But really, they are just tools for the job. When misapplied, they become detrimental, but when used to solve the problems they are good at, they shine. In fact, they can give you a lot of bang for your design buck. But when the domain logic you’re implementing is very complex, they can begin to fall short, as their relatively low level of abstraction becomes insufficient and prone to code repetition, and inconsistencies when this repeated code goes out of sync. Which is a big problem when dealing with complex subdomains.
Section 6: Tackling complex business logic
When implementing complex business logic, the patterns that we’ve seen up to this point can only get you so far. They start to leave a lot to be desired due to their relatively low level of abstraction. When the situation calls for a higher level of abstraction, in order to produce a more supple design, DDD calls for the domain model pattern.
Domain model
Taking from Martin Fowler’s definition, we learn that the domain model is a full object-oriented model of the domain, that incorporates both behavior and data. Domain models take the form of a large web of interconnected objects, where each one represents a meaningful concept in the business domain.
In his book, Eric Evans expanded greatly on this definition, introducing a set of patterns and tools for implementing domain models. Indeed, to build a domain model, we incorporate other building block patterns: value objects, entities, aggregates, domain events, domain services.
Also, there are two main rules that a domain model needs to follow:
- There should be no dependency on particular frameworks or infrastructure. Objects in the domain model should be plain old objects, focused only on domain logic.
- The domain model should speak the ubiquitous language of the bounded context in which it operates. That means that all identifiers should call back to business concepts and it should represent the mental model of the domain experts.
Value object
A value object is an object whose identity is given by its properties. That is, its value. It does not have an explicit identifier, like an Id field. Consider for example a Point object:
class Point
{
double _x;
double _y;
}The X and Y values completely define a point. Two instances of this class with the same X and Y coordinates represent the same point. Changing the value of either coordinate produces a new point.
They are useful for representing properties of other objects and are usually implemented as immutable objects. One of the great strengths of value objects is that they allow the model to speak the ubiquitous language by replacing primitives with bespoke small objects that make the code clearer and encapsulate related business logic.
As an example, consider this Order class.
class Order
{
private int _id;
private string _status;
private string _email;
private string _phone;
private double _shippingWeight;
private string _countryCode;
public Order(/*...*/) {/*...*/}
}
// This class can be instantiated like this:
var order = new Order(
id: 12345,
status: "Processing",
email: "test@email.com",
phone: "123-456-7890",
shippingWeight: 10,
countryCode: "US"
);Here, all the values are assigned by convention. An email, a phone number, a status… They are all just strings with no special behavior or meaning. We must know what they look like beforehand in order to assign them correctly.
If we use value objects, this class could be implemented like this instead:
class Order
{
private OrderId _id;
private OrderStatus _status;
private PersonName _name;
private EmailAddress _email;
private PhoneNumber _phone;
private Weight _shippingWeight;
private CountryCode _country;
public Order(/*...*/) {/*...*/}
}
// Now, instances can be created like this:
var order = new Order(
id: new OrderId(12345),
status: OrderStatus.Processing,
name: new PersonName("Kevin", "Campusano"),
email: EmailAddress.Parse("test@email.com"),
phone: PhoneNumber.Parse("1234567890"),
shippingWeight: Weight.FromLbs(10.25),
country: CountryCode.Parse("US")
);This approach has many advantages:
First of all the Order class does not have to validate its fields. Validation can happen in the value objects. This is good because it allows other domain objects to have fields of the same type without having to duplicate the validation logic themselves. Imagine you also have a contact object somewhere in your model that includes a phone number field, for example. Both it and Order can reuse the phone number value object, and the logic it carries.
Secondly, value objects can capture the business logic that’s closely related to them. A phone number field, for example can implement methods to obtain further information about it like its area code or the country it belongs to. A “weight” value object can implement logic for converting from one measuring system to another.
// Here's a weight value object that encapsulates logic like converting from one
// unit to another and comparing the magnitude of different values.
class Weight : IComparable<Weight>, IEquatable<Weight>
{
const double LbsPerKg = 2.20462;
double _lbs;
private Weight(double lbs) { _lbs = lbs; }
public static Weight FromLbs(double lbs) => new Weight(lbs);
public static Weight FromKgs(double kgs) => new Weight(kgs * LbsPerKg);
public double ToLbs() => _lbs;
public double ToKgs() => _lbs / LbsPerKg;
public int CompareTo(Weight? other) => ToLbs().CompareTo(other?.ToLbs());
public bool Equals(Weight? other) => ToLbs().Equals(other?.ToLbs());
}Finally, using value objects lets the model speak the ubiquitous language, and thus makes it clearer. Strongly typing properties in this way, beyond just using language primitives, very clearly captures the intent of the property.
Entities
Entities are objects that represent the concepts in the domain that have a lifecycle and explicit identification. A person, an order, a lead, a transaction. These are all examples of entities. Entities, as opposed to value objects, are not immutable, and are expected to change throughout their life in the system. Value objects, like we saw before, are ideal for representing properties of entities.
Entities are a core building block for a domain model. However, they are not used independently. They are used as part of an aggregate.
Aggregates
An aggregate is a hierarchy of entities and value objects that are bound together by closely related business logic. The aggregate forms a boundary that protects the consistency of the objects that compose it. It achieves this by preventing external objects from directly modifying its state and defining a public interface through which other parts of the system can interact with it.
The rest of the system cannot directly mutate the state of the entities within an aggregate. They can only do so via the methods exposed by the aggregate’s public interface. These methods, so called commands, encapsulate the aggregate’s business logic and protect them from corruption, by enforcing the necessary validations and invariants. Indeed, all the business logic that’s closely related to the aggregate lives in one place: the aggregate itself.
// Here we have an aggregate that represents a shopping cart and its items.
public class Quote
{
// It does not expose its list of items publicly. Instead, it implements
// public methods for manipulating them.
IList<QuoteItem> _items = [];
QuoteItem? GetItemBy(ProductId productId) =>
_items.FirstOrDefault(i => i.ProductId == productId);
public void AddItem(ProductId productId, int quantity)
{
var item = GetItemBy(productId);
if (item != null)
throw new InvalidOperationException("Item already exists.");
_items.Add(new QuoteItem
{
ProductId = productId,
Quantity = quantity
});
}
// Even though this method modifies an item, and not the quote itself, it's
// still implemented here, because this is the aggregate root.
public void SetItemQuantity(ProductId productId, int quantity)
{
var item = GetItemBy(productId) ??
throw new InvalidOperationException("Item does not exist.");
item.Quantity = quantity;
}
// ...
}These commands, which are the public interface of an aggregate, should all be defined in a single entity within the aggregate. We call this entity the aggregate root. If the aggregate is a hierarchy of objects, and we can picture it as a tree, then the root is the object that exists at the root of the tree, where all branches come from.
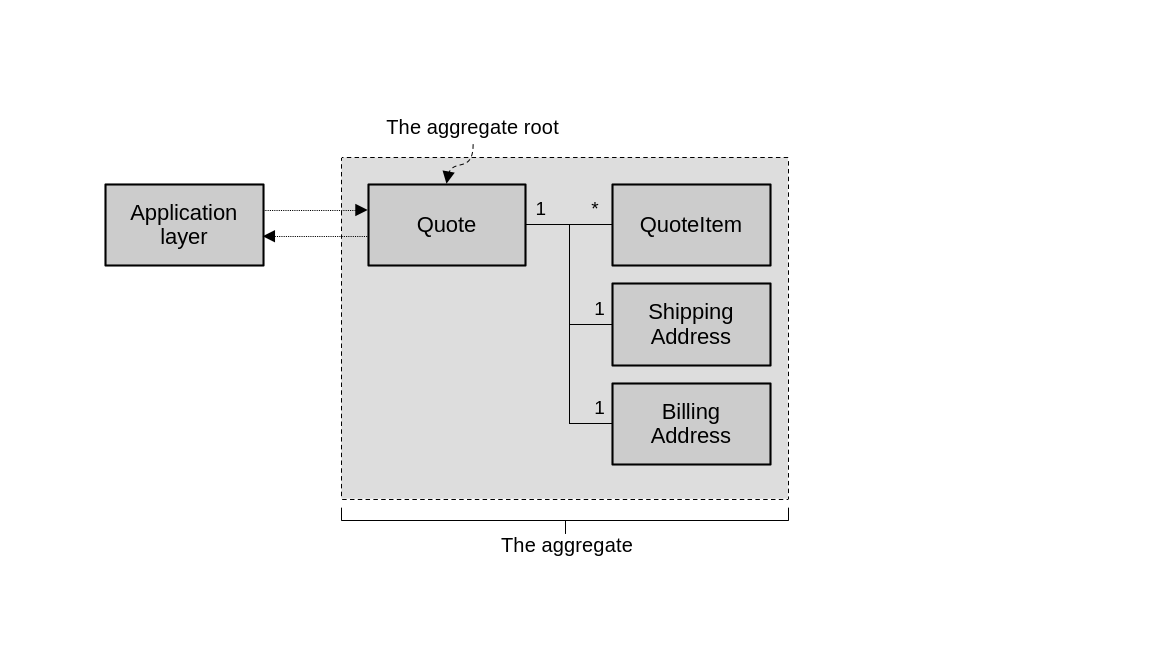
The aggregate is a hierarchy of objects. The aggregate root is the sole object in this hierarchy with which other components interact.
This focus on commands makes the implementation of the application layer components more straightforward. I.e. they become transaction scripts. By “application layer components”, I mean those components that orchestrate calls to the domain model in order to fulfill use cases in response to, say, user requests. They follow a general pattern of:
- Load the aggregate. Typically from persistent storage.
- Invoke the desired command.
- Persist the new state of the aggregate.
For example:
// Here's an application service leveraging the quote aggregate to add an item
// to a shopping cart.
class AddItemToQuote
{
// ...
public Result Run(QuoteId quoteId, ProductId productId, int quantity)
{
try
{
var quote = _quoteRepository.FindById(quoteId);
if (quote == null) return Result.Error("Quote not found.");
quote.AddItem(productId, quantity);
_quoteRepository.Save(quote);
return Result.Success();
}
// Notice how the application layer logic takes care of database related
// errors. Remember that the aggregate is a plain old object which has
// no knowledge about infrastructure or frameworks. The data access
// logic, in this case encapsulated in the _quoteRepository, is the one
// that will produce such errors when trying to commit changes to the
// underlying storage.
catch (ConcurrencyException ex)
{
return Result.Error(ex);
}
}
}There are other rules that aggregates need to follow. One of them is that the aggregate acts as a transaction boundary for aggregate operations. That is, all changes to an aggregate should be transactional, atomic. Also, no system operation should involve a transaction that includes different aggregates. We should have one aggregate per database transaction.
This reveals another aspect of aggregates: An aggregate should expect strong consistency only on its own objects. For objects that are outside of the aggregate, eventual consistency should suffice. Or, looking at it from a different angle, this means that when designing an aggregate, data consistency is a guiding principle. The data that needs to be strongly consistent in order to fulfill the business requirements, should be included in the aggregate. The data that can be eventually consistent and still meet the requirements, probably belongs in a different aggregate.
At first glance, all these rules for aggregates may seem overly limiting. But the main idea is to keep their scope as constrained as possible, to prevent them from growing too much and taking on too many responsibilities. We should strive to keep aggregates small, highly cohesive, and decoupled from other system components. That unlocks the ability for them to be reorganized and reused in many ways. This helps avoid code duplication when fulfilling the requirements of today while also reducing the cost of evolving to meet the requirements of tomorrow.
Domain event
Through their commands, the outside world can send messages to aggregates. Domain events are the mechanism through which aggregates can themselves send messages to the outside world. As their name suggests, domain events are messages that describe important events that have happened in the business domain, related to an aggregate. Think “order placed”, “user registered” or “product out of stock”. The events should provide all necessary data that allows consumers to understand what has happened.
// This JSON data describes the event of an item being added to a shopping cart.
// It includes all the details that subscribers need to know about the event.
{
"quote-id": "f3774200-9e57-4ad2-9d93-ffb9e92b8364",
"event-id": 123,
"event-type": "item-added-to-quote",
"event-time": 1628970815,
"product-id": "7e7aee52-9aa1-4e0e-810e-666cedab5a7a",
"quantity": 1
}public class Quote
{
// ...
IList<DomainEvent> _domainEvents = [];
public void AddItem(ProductId productId, int quantity)
{
// ...
// This command creates the event and adds it to the aggregate's list.
_domainEvents.Add(new ItemAddedToQuote(
quoteId: _id,
productId: productId,
quantity: quantity
));
}
}Domain events are also part of an aggregate’s public interface. Just like its commands. Other parts of the system can subscribe to these events, and when they happen, react accordingly. We will learn more about domain events, and see how to push them to subscribers, later in the series.
Domain service
Sometimes there’s business logic that doesn’t belong to a particular aggregate or value object, or that involves multiple aggregates. Domain services can be implemented in these cases. Domain services are simple stateless objects that implement some business logic. Somewhat like an aggregate’s command, but defined outside of an aggregate.
// Domain services are a good solution for implementing logic that orchestrates
// calls to different system components.
class PlaceOrder
{
// ...
public Result Run(QuoteId quoteId)
{
try
{
var quote = _quoteRepository.FindById(quoteId);
if (quote == null) return Result.Error("Quote not found.");
quote.Close();
_quoteRepository.Save(quote);
var order = new Order(quote);
order.PlaceOrder();
_orderRepository.Save(order);
// We can imagine the above code producing an "order placed" event,
// and a separate payment processing component picking it up and
// getting to work. Then, inventory and shipping components could
// continue processing the order after the payment is successful.
return Result.Success();
}
catch (ConcurrencyException ex)
{
return Result.Error(ex);
}
}
}Of course, the rule of “modify only one aggregate per transaction” still applies. Even for domain services that orchestrate business operations that involve multiple aggregates. Remember, if strong consistency is needed across separate aggregates, and thus they have operations that need to be executed within the same transaction, then maybe these objects should be part of the same aggregate in the first place.
It’s also important to consider domain services as a sort of last resort. A final domain modeling tool to use only when the other tools like aggregates, value objects, commands and domain events, fall short and truly can’t meet the requirements on their own.
Data access concerns
As we’ve stated at the beginning, the domain model should be made of plain old objects. That means no dependency on framework components or particular infrastructure, just pure domain logic. Data access logic is one of those things that it should be oblivious about.
In practical terms, your choice of technology stack and software development framework will usually dictate the mechanisms you use for interacting with persistent data storage. But that doesn’t matter to the domain model, with the correct abstraction, it should be compatible with any data access mechanism. Here are a few patterns worth mentioning:
We’ve already seen active record being used as a data access strategy. Particularly useful when paired with an ORM framework. Due to its nature of tieing infrastructure concerns (i.e. data access logic) with the business logic, you have to jump through some hoops to make it work with a domain model. But it can be done. The repository pattern is also a good fit for solving the data access problem in the context of DDD. It offers a clear, intention-revealing interface for data retrieval and modification. Unit of work is also a pattern worth looking into, for coordinating numerous database operations.
But the main takeaway is this: the domain model does not concern itself with data access, or frameworks, or infrastructure. So make sure to keep it plain and use abstractions to keep it unconcerned.
Section 7: Modeling the dimension of time
The event sourced domain model is a further evolution of the domain model which incorporates the dimension of time. By leveraging domain events as the source of truth for system data, it allows for a model that can provide deeper insight into the data, rich audit logging, and visibility into the state of the aggregates and entities at any previous point in their lifecycle.
Data storage and retrieval
The main characteristic that differentiates event sourcing from a traditional domain modeling is how the data that represents the aggregates is persisted. Instead of persisting the aggregate’s current state, event sourced domain models persist the domain events produced by the aggregates. These domain events are generated as a result of any operation that changes the state of the aggregate. Then, to obtain the current state of the aggregates, all the events are retrieved from storage and used to reconstruct the full object in memory.
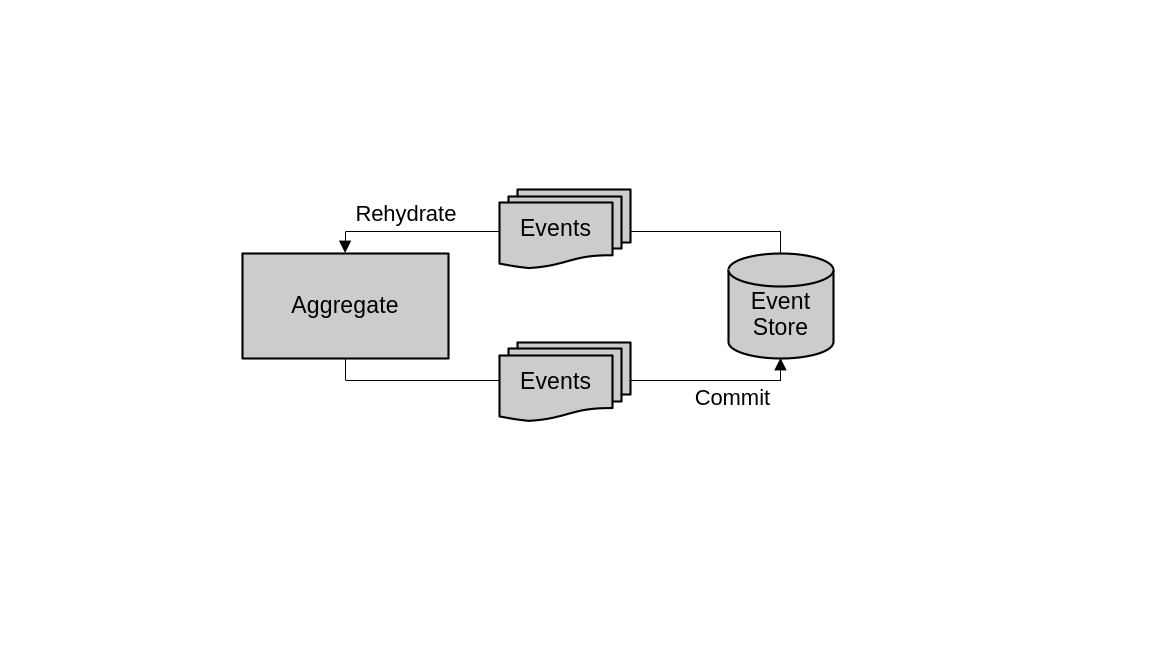
In an event sourced domain model, aggregates produce events and commit them to the event store. To instantiate aggregates then, the same events are fetched from the event store and used to rehydrate the in-memory objects.
For example, in a database that backs an order processing system, an orders table might look like this:
| id | status | phone | shipping_weight | country_code | created_at | updated_at | |
|---|---|---|---|---|---|---|---|
| 1 | pending | john.doe@example.com | 555-0101 | 2.5 | US | 2025-01-10 | 2025-01-10 |
| 2 | paid | sarah.smith@example.com | 555-0102 | 5.3 | CA | 2025-01-09 | 2025-01-11 |
| 3 | shipped | mike.johnson@example.com | 555-0103 | 1.8 | GB | 2025-01-08 | 2025-01-12 |
| 4 | pending | emma.wilson@example.com | 555-0104 | 3.2 | AU | 2025-01-11 | 2025-01-11 |
| 5 | cancelled | david.brown@example.com | 555-0105 | 4.7 | US | 2025-01-07 | 2025-01-13 |
Here, each row represents an order and their current state. The database schema resembles the order domain entity.
With event sourcing, what we persist into our database is a series of events that capture the full history of each order, as they journey through the system:
{
"order_id": 123,
"event_id": 0,
"event_type": "order_created",
"timestamp": "2025-01-10T10:00:00Z",
"data": {
"email": "john.doe@example.com",
"phone": "555-0101",
"country_code": "US",
"status": "pending",
// ...
}
},
{
"order_id": 123,
"event_id": 1,
"event_type": "payment_failed",
"timestamp": "2025-01-11T12:00:00Z",
"data": {
"status": "payment_failed",
"reason": "insufficient_funds"
}
},
{
"order_id": 123,
"event_id": 2,
"event_type": "payment_details_updated",
"timestamp": "2025-01-11T12:05:00Z",
"data": {
"status": "pending",
"payment_method_nonce": "new-nonce-xyz",
}
},
{
"order_id": 123,
"event_id": 3,
"event_type": "payment_succeeded",
"timestamp": "2025-01-11T12:05:00Z",
"data": {
"status": "paid"
}
},
{
"order_id": 123,
"event_id": 4,
"event_type": "inventory_stock_updated",
"timestamp": "2025-01-11T15:00:00Z",
"data": {
"status": "processing",
"items": [
{"product_id": "A1", "quantity": 2},
{"product_id": "B2", "quantity": 1}
]
}
},
{
"order_id": 123,
"event_id": 5,
"event_type": "shipping_scheduled",
"timestamp": "2025-01-12T09:00:00Z",
"data": {
"status": "awaiting_shipment",
"shipping_number": "TRACK1234567890"
}
},
{
"order_id": 123,
"event_id": 6,
"event_type": "order_shipped",
"timestamp": "2025-01-13T14:00:00Z",
"data": {
"status": "shipped"
}
}We call this database, the event store. This is an append-only storage mechanism that needs to support two features: fetching events that belong to a particular business entity and adding new ones.
// An event store only needs to support two features: fetching and appending.
interface IEventStore
{
IEnumerable<DomainEvent> Fetch(Guid Id);
void Append(Guid Id, IEnumerable<DomainEvent> events, int expectedVersion);
}In code, when we want to retrieve an order from storage, what we do is fetch all its events, iterate over them and apply the changes they represent to an in-memory object, until it is fully reconstructed, or “rehydrated”. In the context of event sourcing, we call these representations of collections of events, projections. In an event sourced domain model, aggregates leverage these projections to figure out their current state.
// This is a hypothetical order aggregate in an event sourced domain model.
// Its constructor expects a collection of domain events which it iterates over
// to apply them to its internal state representaton object.
class Order
{
private List<DomainEvent> _events = new();
private OrderStateProjection _state = new();
public Order(IEnumerable<DomainEvent> events)
{
_state = new OrderStateProjection();
foreach (var e in events)
{
_events.Add(e);
_state.Apply((dynamic)e);
}
}
// Properties can be exposed to the outside world by leveraging the state
// projection.
public OrderId Id => _state.Id;
public int Version => _state.Version;
// ...
}
// This is a general use event sourced projection of an order, used to capture
// the current state of an order entity or aggregate.
class OrderStateProjection
{
// This projection is meant to expose the full state of the order aggregate
// so it includes all the properties that belong to the order.
public OrderId Id { get; private set; }
// With event sourcing, we need to keep track of the version of the entity.
// Every event that happens increments the version number.
public int Version { get; private set; }
public OrderStatus Status { get; private set; }
public PersonName Name { get; private set; }
public EmailAddress Email { get; private set; }
public PhoneNumber Phone { get; private set; }
public Weight ShippingWeight { get; private set; }
public CountryCode Country { get; private set; }
public string PaymentMethodNonce { get; private set; }
public bool InventoryResolved { get; private set; }
public string TrackingNumber { get; private set; }
// It defines a series of "Apply" method overloads, one for each supported
// domain event. The Order aggregate from above passes all the domain events
// to the various overloads, calling them one by one, in order, until the
// full state is rehydrated into the projection. Each "Apply" overload takes
// the data captured in its event and assigns it to the correct property in
// the projection.
public void Apply(OrderCreatedEvent e)
{
Id = e.Id;
Status = e.Status;
Name = e.Name;
Email = e.Email;
Phone = e.Phone;
ShippingWeight = e.ShippingWeight;
Country = e.Country;
Version = 1;
}
public void Apply(PaymentFailedEvent e)
{
Status = OrderStatus.PaymentFailed;
Version++;
}
public void Apply(PaymentDetailsUpdatedEvent e)
{
Status = OrderStatus.Pending;
PaymentMethodNonce = e.PaymentMethodNonce;
Version++;
}
public void Apply(PaymentSucceededEvent e)
{
Status = OrderStatus.Processing;
Version++;
}
public void Apply(InventoryStockUpdatedEvent e)
{
Status = OrderStatus.Processing;
InventoryResolved = true;
Version++;
}
public void Apply(ShippingScheduledEvent e)
{
Status = OrderStatus.AwaitingShipment;
TrackingNumber = e.TrackingNumber;
Version++;
}
public void Apply(OrderShippedEvent e)
{
Status = OrderStatus.Shipped;
Version++;
}
}Notice the Version field in the projection, which indicates the number of changes that the entity has gone through.
On the other hand, when it comes to appending new events for an aggregate, the event store needs to be aware of potential concurrency problems and handle them. After all, the ordering of the events matter. That’s why the event store usually implements optimistic concurrency control, leveraging the version field we touched on earlier. Essentially, when trying to append new events, the version being worked with is specified. If it doesn’t match the current version of the aggregate in the event store (maybe because some other process appended a new event), then the operation has to fail, or otherwise adapt to make sure the data remains consistent.
Advantages and disadvantages
One advantage of this design is that we can produce many distinct projections of the same underlying event sourced data. In the previous example, we saw a projection that represents the full current state of the order. But we might need other projections which are optimized for different use cases.
For example here’s a projection that captures all the statuses that an order went through, which might help different business analysis use cases:
// This projection only cares about the changes in status of the order, so
// instead of attempting to capture its full state, in keeps track of all the
// statuses in a collection.
class OrderStatusHistoryProjection
{
public OrderId Id { get; private set; }
public int Version { get; private set; }
public List<OrderStatus> Statuses = new();
// All the "Apply" overloads capture the status change that each event
// caused.
public void Apply(OrderCreatedEvent e)
{
Statuses.Add(OrderStatus.Pending);
Version = 1;
}
public void Apply(PaymentFailedEvent e)
{
Statuses.Add(OrderStatus.PaymentFailed);
Version++;
}
public void Apply(PaymentDetailsUpdatedEvent e)
{
Statuses.Add(OrderStatus.Pending);
Version++;
}
public void Apply(PaymentSucceededEvent e)
{
Statuses.Add(OrderStatus.Processing);
Version++;
}
public void Apply(InventoryStockUpdatedEvent e)
{
Statuses.Add(OrderStatus.Processing);
Version++;
}
public void Apply(ShippingScheduledEvent e)
{
Statuses.Add(OrderStatus.AwaitingShipment);
Version++;
}
public void Apply(OrderShippedEvent e)
{
Statuses.Add(OrderStatus.Shipped);
Version++;
}
}We can even store these projections into separate databases if we need to. We’ll learn more about that aspect later when we discuss CQRS.
Another feature that we can implement easily thanks to event sourcing is time travel. We can easily apply the stored events up to a specific point in time or up to a specific version number and obtain the state of the entity as it was at that time. This can, for example, help troubleshooting, and unlock more avenues for business analysis.
An obvious disadvantage of event sourcing is the complexity that it introduces. This complexity, compounded by the potential learning curve on teams that aren’t used to this kind of design, can be very detrimental when utilized in projects that don’t need it. As usual, follow DDD’s core principle of tying the system’s design to the domain’s needs, make sure to use the right tool for the job, and only deploy an event sourced domain model when the situation really calls for it. That is, whenever requirements dictate that the features enabled by such a design are necessary.
The event sourced domain model
So, in summary, an event sourced domain model is a domain model that uses the event sourcing pattern to represent and operate on its aggregates. In a traditional, non-event-sourced domain model, the current state of the aggregates is persisted, commands modify this state and domain events are emitted for certain important operations, when needed. In the event sourced variant, domain events are used much more frequently, as they are the only source of truth. Everything and anything that changes the state of the aggregates produces an event. No changes are done directly, only through events. This is necessary because it is the events that are persisted, and it is from these events that the aggregates’ current state is derived.
In general, operations involving event sourced aggregates go through the following steps:
- Load the aggregate’s domain events from the event store.
- Reconstruct the aggregate’s state using these events. You can use the particular projection needed for the task at hand.
- Run the necessary aggregate commands. Which in turn produce new domain events.
- Append the new events into the event store. Making sure to handle any concurrency errors.
public class RescheduleOrderForPayment
{
private IOrderRepository _orderRepository;
// ...
// This is the general pattern that application services often follow when
// interacted with event sourced domain model aggregates: load events,
// construct the aggregate with the events, run commands and save the newly
// created events.
public Result Run(OrderId orderId, string paymentMethodNonce)
{
try
{
var events = _orderRepository.LoadEvents(orderId);
var order = new Order(events);
var originalVersion = order.Version;
// See below for what commands like these generally look like.
order.UpdatePaymentDetails(paymentMethodNonce);
order.ScheduleForPaymentProcessing();
_orderRepository.Save(order, expectedVersion: originalVersion);
return Result.Success();
}
// The repository uses the given version parameter to implement
// optimistic concurrency control.
catch (ConcurrencyException ex)
{
return Result.Error(ex.Message);
}
}
}
// ...
class Order
{
// ...
// Commands of event sourced aggregates don't modify state directly.
// Instead, they create the appropriate events and append them.
public void UpdatePaymentDetails(string paymentMethodNonce)
{
var e = new PaymentDetailsUpdatedEvent(_state.Id, paymentMethodNonce);
_events.Add(e);
_state.Apply(e);
}
}DDD tools for implementing business logic
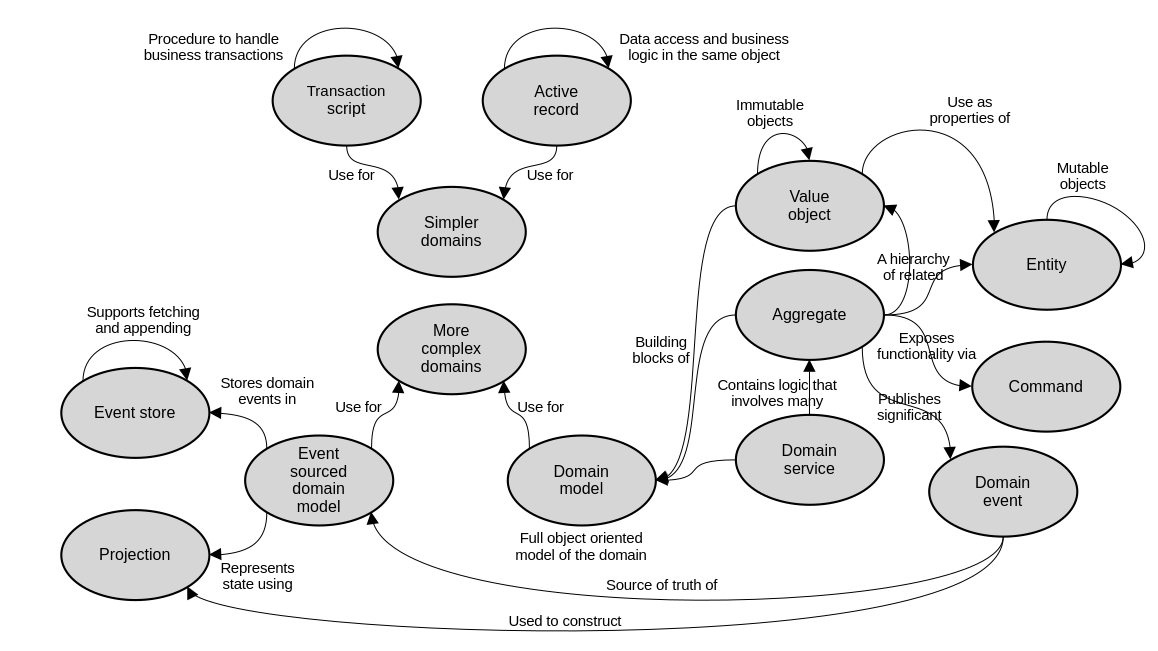
These are the main concepts that we’ve explored, and how they relate to each other.
software architecture design books
Comments