Deploying LLMs Efficiently with Mixture of Experts

By Edgar Mlowe
June 2, 2025
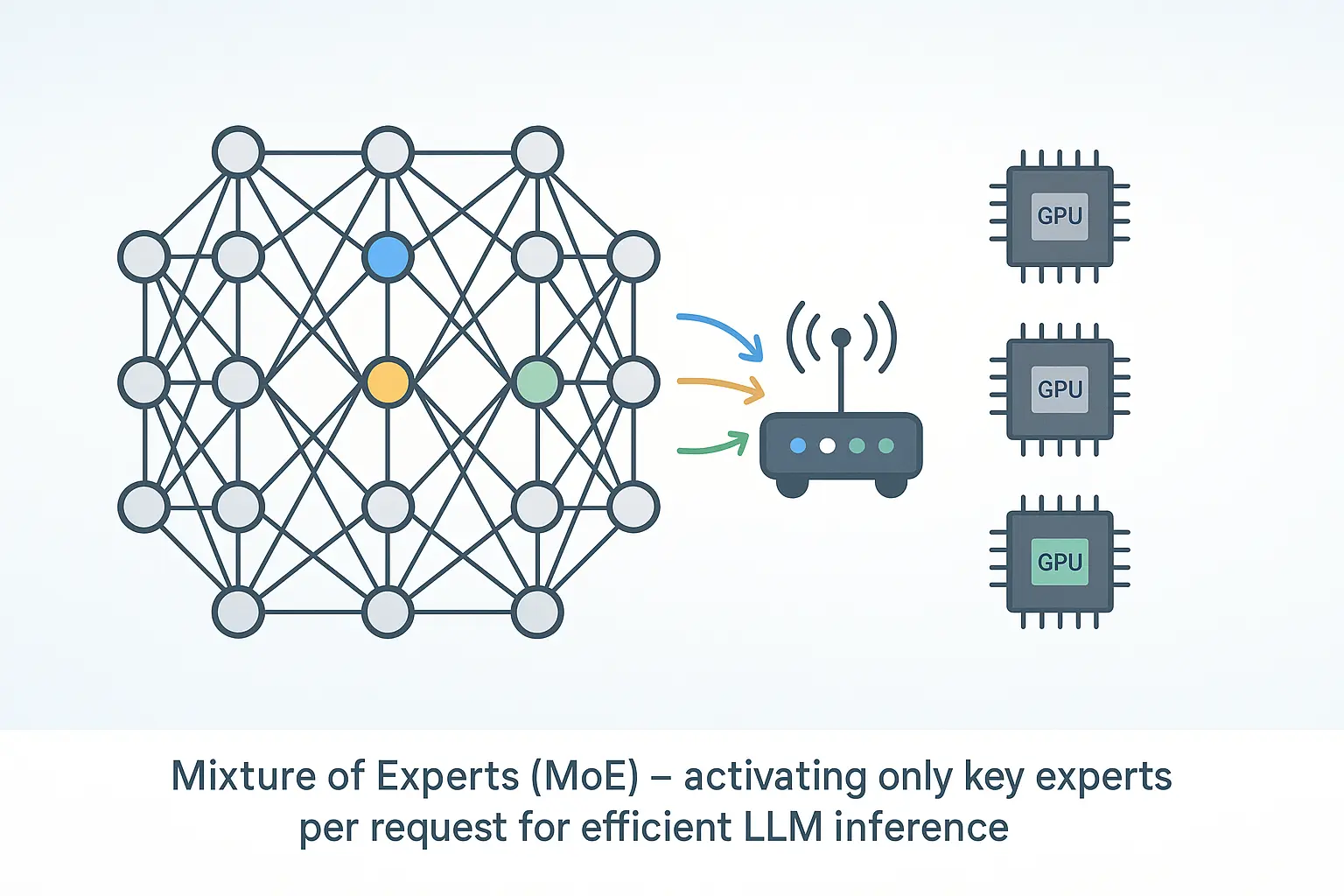
1. Why MoE?
Modern language models can have hundreds of billions of parameters. That power comes with a cost: high latency, high memory, and high energy use. Mixture‑of‑Experts (MoE) tackles the problem by letting only a few specialised sub‑networks run for each token, cutting compute while keeping quality.
In this post you’ll get:
- A short intro to MoE
- A simple diagram that shows how it works
- A look at Open‑Source MoE Models
- A quick guide to running one on your own machine with Docker + Ollama
- Deployment tips and extra resources
2. Key Ideas
| Term | Quick meaning |
|---|---|
| Dense model | Every weight is used for every token. |
| Expert | A feed‑forward network inside the layer. |
| Router | Tiny layer that scores experts for each token. |
| MoE layer | Router + experts; only the top‑k experts run. |
| Sparse activation | Most weights sleep for most tokens. |
Analogy: Think of triage in a hospital. The nurse (router) sends you to the right specialist (expert) instead of paging every doctor.
3. How a Token Moves Through an MoE Layer
Input Token
│
▼
┌────────┐
│ Router │ (scores all experts)
└────────┘
│ selects top‑k
▼
┌────────┐ ┌────────┐
│Expert 1│… │Expert k│ (inactive experts ≈ greyed‑out)
└────────┘ └────────┘
│
▼
Combined Output- The router scores all experts.
- It picks the best one or two.
- Only those experts process the token.
- Their outputs are combined and passed to the next layer.
- During training, a small penalty is added so the router spreads tokens evenly among the experts.
4. Why It Saves Compute
- Fewer active weights: DeepSeek‑R1 activates only 6 % of its weights per token (so 94 % stay idle), while Grok‑1 activates about 25 %. Because fewer weights run, the model performs fewer multiply‑add operations, directly cutting computation time and energy.
- Scale without extra cost: You can add more experts to grow the model’s capacity, and the router still activates only a few per token—so compute cost and latency remain almost unchanged.
- Focused fine‑tuning: You can fine‑tune a single expert to adapt the model to a new topic.
Example: Mixtral‑8×7B runs only 13 B parameters per token yet matches Llama‑2‑70B, while generating ~6× faster on the same GPU.
5. Quick Start with Ollama
Run a Mixture‑of‑Experts model in one line:
ollama run mixtral:8x7b "Why is MoE efficient?"If the model is not yet on your machine, Ollama will download a quantized copy automatically.
Need Ollama? Install it either way:
-
Native binary (macOS/Linux/Windows):
curl -fsSL https://ollama.com/install.sh | sh→ then use theollama runcommand above. -
Docker container:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama docker exec -it ollama ollama run mixtral:8x7b "Why is MoE efficient?"
Both methods expose a local REST endpoint on port 11434, so you can integrate the model into scripts or back‑end services.
Open‑Source MoE Models — At a Glance
- Entry‑level (single‑GPU): Mixtral‑8×7B, Qwen3‑30B‑A3B — fit in 12–16 GB of VRAM and are ideal for prototyping.
- Mid‑range (workstation‑class): Mixtral‑8×22B, DeepSeek‑R1‑32B — need ~32 GB of VRAM and provide near‑frontier accuracy with long context windows.
- Research‑scale (multi‑GPU): Grok‑1, DeepSeek‑R1‑671B — require 64 GB+ of VRAM or multi‑GPU clusters but offer state‑of‑the‑art performance.
- Models ship in a space‑saving 4‑bit form, so they use about half the memory of the standard 16‑bit (FP16) version—helpful if your GPU VRAM is tight.
- Start with an entry‑level model, validate your pipeline, and scale up only when the use‑case justifies the added cost.
6. Deployment Tips
-
Check GPU memory first. All model weights must fit into GPU VRAM during inference. If they don’t:
- Use the 4‑bit download — it needs roughly half the memory with only a small quality trade‑off.
- Off‑load to CPU RAM — frameworks such as DeepSpeed‑MoE or vLLM can park less‑used weights on the CPU; throughput drops, but the model still runs.
-
Spread the work. While fine‑tuning, watch router stats to confirm every expert is being used; add a load‑balancing loss if a few dominate.
-
Batch your prompts if experts sit on different GPUs or machines. When the model has to jump between devices, every prompt makes a short “network trip.” Sending many prompts together means fewer trips, so the overall run is faster.
Useful links
- Mixtral‑8×7B Instruct model card
- DeepSeek‑R1 technical report
- Hugging Face MoE tutorial
- vLLM inference engine
- DeepSpeed‑MoE documentation
7. Takeaway
Mixture‑of‑Experts lets you keep big‑model quality without the big‑model bill. Thanks to open models and tools like Ollama, you can spin up an MoE LLM on a single machine, test your ideas, and scale when you’re ready.
Got questions or feedback? Drop a comment below.
Comments