Kubernetes 101: Deploying a web application and database

By Kevin Campusano
January 8, 2022

The DevOps world seems to have been taken over by Kubernetes during the past few years. And rightfully so, I believe, as it is a great piece of software that promises and delivers when it comes to managing deployments of complex systems.
Kubernetes is hard though. But it’s all good, I’m not a DevOps engineer. As a software developer, I shouldn’t care about any of that. Or should I? Well… Yes. I know that very well after being thrown head first into a project that heavily involves Kubernetes, without knowing the first thing about it.
Even if I wasn’t in the role of a DevOps engineer, as a software developer, I had to work with it in order to set up dev environments, troubleshoot system issues, and make sound design and architectural decisions.
After a healthy amount of struggle, I eventually gained some understanding on the subject. In this blog post I’ll share what I learned. My hope is to put out there the things I wish I knew when I first encountered and had to work with Kubernetes.
So, I’m going to introduce the basic concepts and building blocks of Kubernetes. Then, I’m going to walk you through the process of containerizing a sample application, developing all the Kubernetes configuration files necessary for deploying it into a Kubernetes cluster, and actually deploying it into a local development cluster. We will end up with an application and its associated database running completely on and being managed by Kubernetes.
In short: If you know nothing about Kubernetes, and are interested in learning, read on. This post is for you.
What is Kubernetes?
Simply put, Kubernetes (or K8s) is software for managing computer clusters. That is, groups of computers that are working together in order to process some workload or offer a service. Kubernetes does this by leveraging application containers. Kubernetes will help you out in automating the deployment, scaling, and management of containerized applications.
Once you’ve designed an application’s complete execution environment and associated components, using Kubernetes you can specify all that declaratively via configuration files. Then, you’ll be able to deploy that application with a single command. Once deployed, Kubernetes will give you tools to check on the health of your application, recover from issues, keep it running, scale it, etc.
There are a few basic concepts that we need to be familiar with in order to effectively work with Kubernetes. I think the official documentation does a great job in explaining this, but I’ll try to summarize.
Nodes, pods, and containers
First up are containers. If you’re interested in Kubernetes, chances are that you’ve already been exposed to some sort of container technology like Docker. If not, no worries. For our purposes here, we can think of a container as an isolated process with its own resources and file system in which an application can run.
A container has all the software dependencies that an application needs to run, including the application itself. From the application’s perspective, the container is its execution environment: the “machine” in which it’s running. In more practical terms, a container is a form of packaging, delivering, and executing an application. What’s the advantage? Instead of installing the application and its dependencies directly into the machine that’s going to run it, having it containerized allows for a container runtime (like Docker) to just run it as a self-contained unit. This makes it possible for the application to run anywhere that has the container runtime installed, with minimal configuration.
Something very closely related to containers is the concept of images. You can think of images as the blueprint for containers. An image is the spec, and the container is the instance that’s actually running.
When deploying applications into Kubernetes, this is how it runs them: via containers. In other words, for Kubernetes to be able to run an application, it needs to be delivered within a container.
Next is the concept of a node. This is very straightforward and not even specific to Kubernetes. A node is a computer within the cluster. That’s it. Like I said before, Kubernetes is built to manage computer clusters. A node is just one computer, either virtual or physical, within that cluster.
Then there are pods. Pods are the main executable units in Kubernetes. When we deploy an application or service into a Kubernetes cluster, it runs within a pod. Kubernetes works with containerized applications though, so it is the pods that take care of running said containers within them.
These three work very closely together within Kubernetes. To summarize: containers run within pods which in turn exist within nodes in the cluster.
There are other key components to talk about like deployments, services, replica sets, and persistent volumes. But I think that’s enough theory for now. We’ll learn more about all these as we get our hands dirty working though our example. So let’s get started with our demo and we’ll be discovering and discussing them organically as we go through it.
Installing and setting up Kubernetes
The first thing we need is a Kubernetes environment. There are many Kubernetes implementations out there. Google, Microsoft, and Amazon offer Kubernetes solutions on their respective cloud platforms, for example. There are also implementations that one can install and run on their own, like kind, minikube, and MicroK8s. We are going to use MicroK8s for our demo, for no particular reason other than “this is the one I know”.
When done installing, MicroK8s will have set up a whole Kubernetes cluster, with your machine as its one and only node.
Installing MicroK8s
So, if you’re in Ubuntu and have snapd, installing MicroK8s is easy. The official documentation explains it best. You install it with a command like this:
$ sudo snap install microk8s --classic --channel=1.21MicroK8s will create a user group which is best to add your user account to so you can execute commands that would otherwise require admin privileges. You can do so with:
$ sudo usermod -a -G microk8s $USER
$ sudo chown -f -R $USER ~/.kubeWith that, our very own Kubernetes cluster, courtesy of MicroK8s, should be ready to go. Check its status with:
$ microk8s status --wait-readyYou should see a “MicroK8s is running” message along with some specifications on your cluster. Including the available add-ons, which ones are enabled and which ones are disabled.
You can also shut down your cluster anytime with microk8s stop. Use microk8s start to bring it back up.
Introducing kubectl
MicroK8s also comes with kubectl. This is our gateway into Kubernetes, as this is the command line tool that we use to interact with it. By default, MicroK8s makes it so we can call it using microk8s kubectl .... That is, namespaced. This is useful if you have multiple Kubernetes implementations running at the same time, or another, separate kubectl. I don’t, so I like to create an alias for it, so that I can call it without having to use the microk8s prefix. You can do it like so:
$ sudo snap alias microk8s.kubectl kubectlNow that all that’s done, we can start talking to our Kubernetes cluster. We can ask it for example to tell us which are the nodes in the cluster with this command:
$ kubectl get nodesThat will result in something like:
NAME STATUS ROLES AGE VERSION
pop-os Ready <none> 67d v1.21.4-3+e5758f73ed2a04The only node in the cluster is your own machine. In my case, my machine is called “pop-os” so that’s what shows up. You can get more information out of this command by using kubectl get nodes -o wide.
Installing add-ons
MicroK8s supports many add-ons that we can use to enhance our Kubernetes installation. We are going to need a few of them so let’s install them now. They are:
- The dashboard, which gives us a nice web GUI which serves as a window into our cluster. In there we can see everything that’s running, read logs, run commands, etc.
- dns, which sets up DNS for within the cluster. In general it’s a good idea to enable this one because other add-ons use it.
- storage, which allows the cluster to access the host machine’s disk for storage. The application that we will deploy needs a persistent database so we need this plugin to make it happen.
- registry, which sets up a container image registry that Kubernetes can access. Kubernetes runs containerized applications, containers are based on images. So, having this add-on allows us to define an image for our application and make it available to Kubernetes.
To install these, just run the following commands:
$ microk8s enable dashboard
$ microk8s enable dns
$ microk8s enable storage
$ microk8s enable registryThose are all the add-ons that we’ll use.
Introducing the Dashboard
The dashboard is one we can play with right now. In order to access it, first run this:
$ microk8s dashboard-proxyThat will start up a proxy into the dashboard. The command will give you a URL and login token that you can use to access the dashboard. It results in an output like this:
Checking if Dashboard is running.
Dashboard will be available at https://127.0.0.1:10443
Use the following token to login:
<YOUR LOGIN TOKEN>Now you can navigate to that URL in your browser and you’ll find a screen like this:
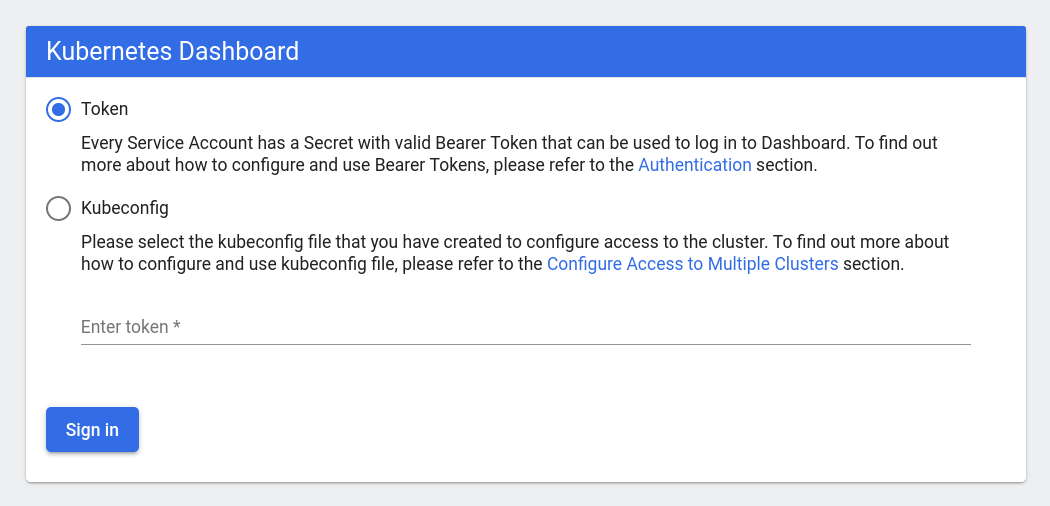
Make sure the “Token” option is selected and take the login token generated by the microk8s dashboard-proxy command from before and paste it in the field in the page. Click the “Sign In” button and you’ll be able to see the dashboard, allowing you access to many aspects of your cluster. It should look like this:
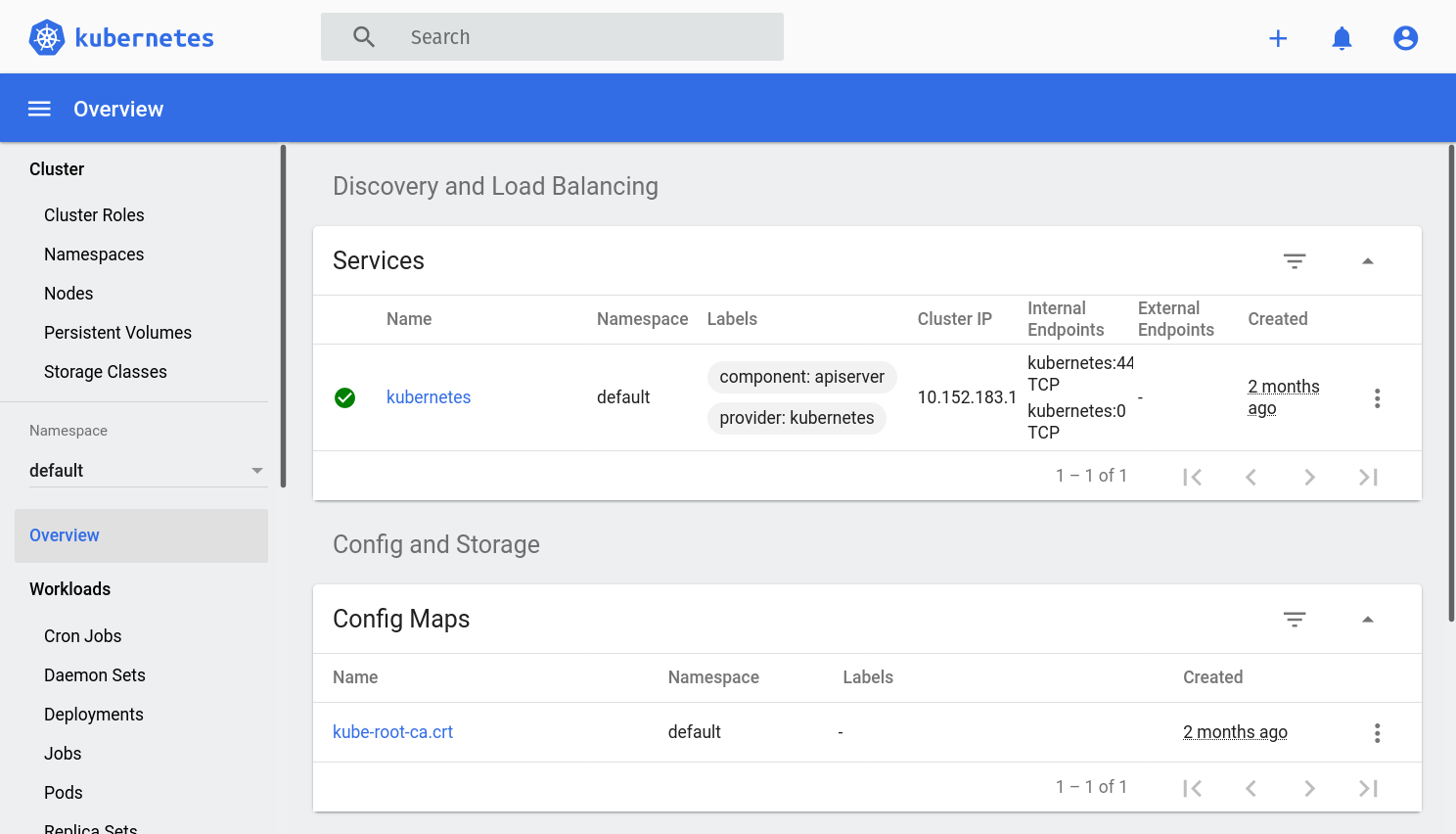
Feel free to play around with it a little bit. You don’t have to understand everything yet. As we work through our example, we’ll see how the dashboard and the other add-ons come into play.
There’s also a very useful command line tool called K9s, which helps in interacting with our cluster. We will not be discussing it further in this article but feel free to explore it if you need or want a command line alternative to the built-in dashboard.
Deploying applications into a Kubernetes cluster
With all that setup out of the way, we can start using our K8s cluster for what it was designed: running applications.
Deployments
Pods are very much the stars of the show when it comes to Kubernetes. However, most of the time we don’t create them directly. We usually do so through “deployments”. Deployments are a more abstract concept in Kubernetes. They basically control pods and make sure they behave as specified. You can think of them as wrappers for pods which make our lives easier than if we had to handle pods directly. Let’s go ahead and create a deployment so things will be clearer.
In Kubernetes, there are various ways of managing objects like deployments. For this post, I’m going to focus exclusively on the configuration-file-driven declarative approach as that’s the one better suited for real world scenarios.
You can learn more about the different ways of interacting with Kubernetes objects in the official documentation.
So, simply put, if we want to create a deployment, then we need to author a file that defines it. A simple deployment specification looks like this:
# nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80This example is taken straight from the official documentation.
Don’t worry if most of that doesn’t make sense at this point. I’ll explain it in detail later. First, let’s actually do something with it.
Save that in a new file. You can call it nginx-deployment.yaml. Once that’s done, you can actually create the deployment (and its associated objects) in your K8s cluster with this command:
$ kubectl apply -f nginx-deployment.yamlWhich should result in the following message:
deployment.apps/nginx-deployment createdAnd that’s it for creating deployments! (Or any other type of object in Kubernetes for that matter.) We define the object in a file and then invoke kubectl’s apply command. Pretty simple.
If you want to delete the deployment, then this command will do it:
$ kubectl delete -f nginx-deployment.yaml deployment.apps "nginx-deployment" deleted
Using kubectl to explore a deployment
Now, let’s inspect our cluster to see what this command has done for us.
First, we can ask it directly for the deployment with:
$ kubectl get deploymentsWhich outputs:
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 2m54sNow you can see that the deployment that we just created is right there with the name that we gave it.
As I said earlier, deployments are used to manage pods, and that’s just what the READY, UP-TO-DATE and AVAILABLE columns allude to with those values of 3. This deployment has three pods because, in our YAML file, we specified we wanted three replicas with the replicas: 3 line. Each “replica” is a pod. For our example, that means that we will have three instances of NGINX running side by side.
We can see the pods that have been created for us with this command:
$ kubectl get podsWhich gives us something like this:
NAME READY STATUS RESTARTS AGE
nginx-deployment-66b6c48dd5-fs5rq 1/1 Running 0 55m
nginx-deployment-66b6c48dd5-xmnl2 1/1 Running 0 55m
nginx-deployment-66b6c48dd5-sfzxm 1/1 Running 0 55mThe exact names will vary, as the IDs are auto-generated. But as you can see, this command gives us some basic information about our pods. Remember that pods are the ones that actually run our workloads via containers. The READY field is particularly interesting in this sense because it tells us how many containers are running in the pods vs how many are supposed to run. So, 1/1 means that the pod has one container ready out of 1. In other words, the pod is fully ready.
Using the dashboard to explore a deployment
Like I said before, the dashboard offers us a window into our cluster. Let’s see how we can use it to see the information that we just saw via kubectl. Navigate into the dashboard via your browser and you should now see that some new things have appeared:
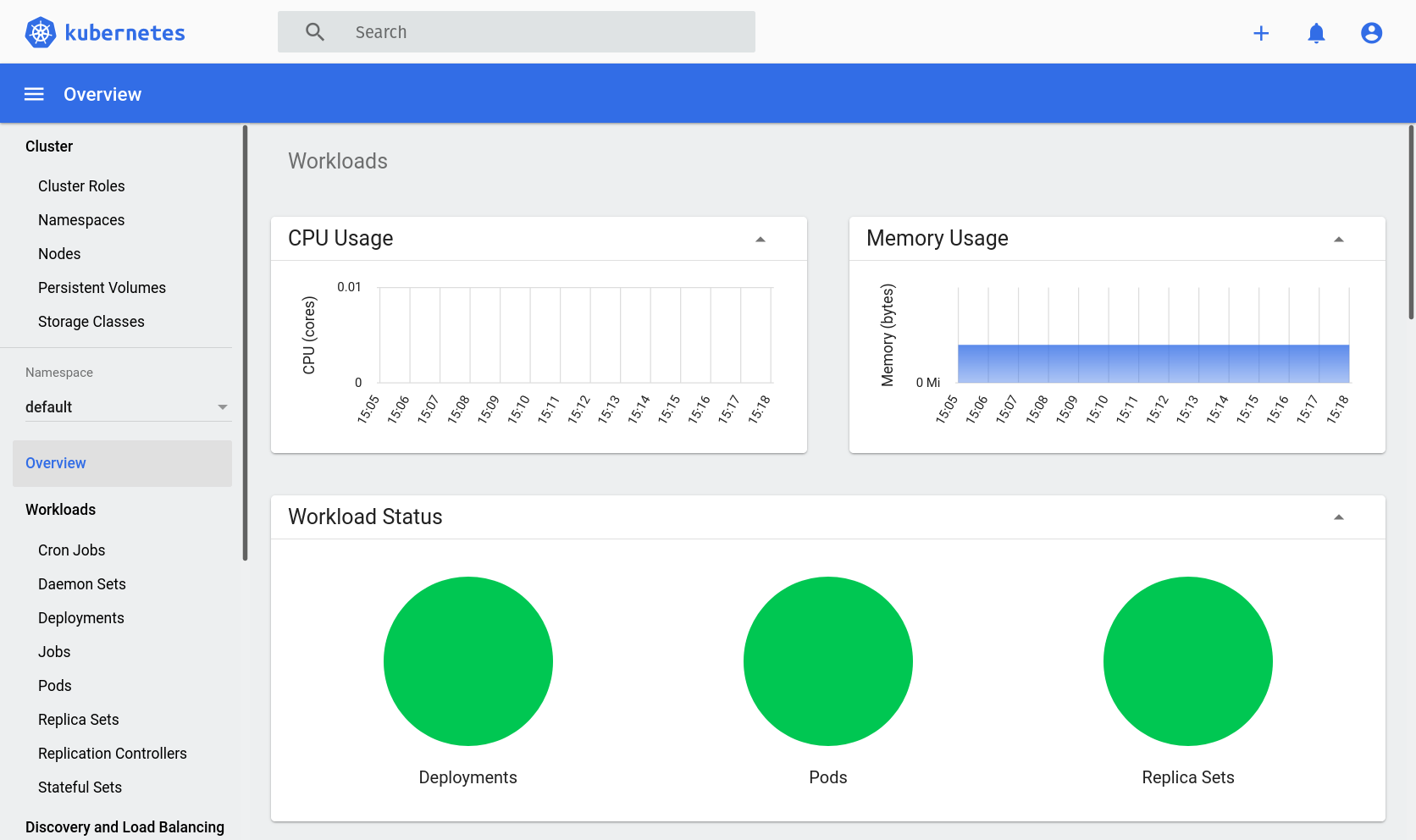
We now have new “CPU Usage” and “Memory Usage” sections that give us insight into the utilization of our machine’s resources.
There’s also “Workload status” that has some nice graphs giving us a glance at the status of our deployments, pods, and replica sets.
Don’t worry too much about replica sets right now, as we seldom interact with them directly. Suffice it to say, replica sets are objects that deployments rely on to make sure that the number of specified replica pods is maintained. As always, there’s more info in the official documentation.
Scroll down a little bit more and you’ll find the “Deployments” and “Pods” sections, which contain the information that we’ve already seen via kubectl before.
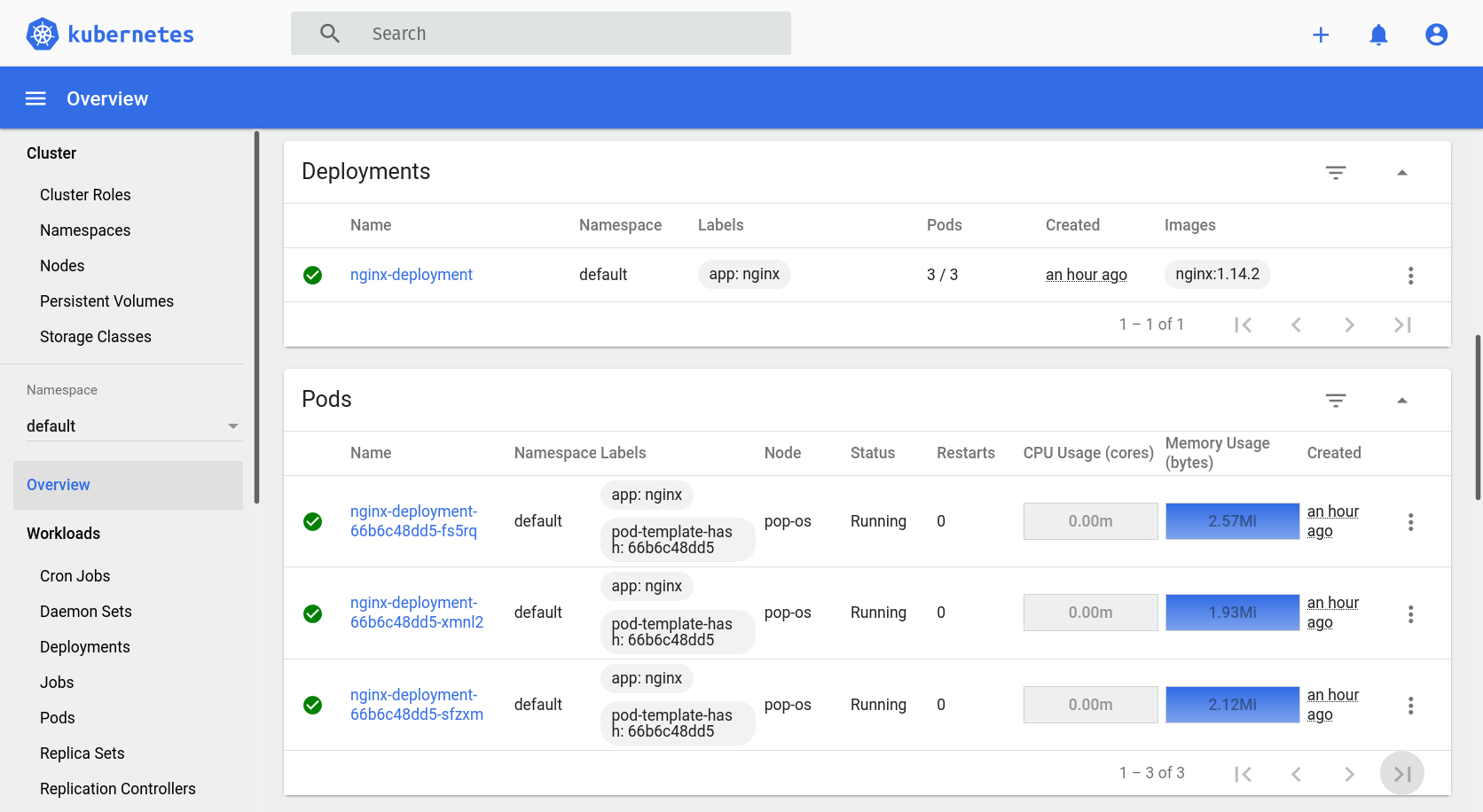
Feel free to click around and explore the capabilities of the dashboard.
Dissecting the deployment configuration file
Now that we have a basic understanding of deployments and pods and how to create them, let’s look more closely into the configuration file that defines it. This is what we had:
# nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80This example is very simple, but it touches on the key aspects of deployment configuration. We will be building more complex deployments as we work through this article, but this is a great start. Let’s start at the top:
apiVersion: Under the hood, a Kubernetes cluster exposes its functionality via a REST API. We seldom interact with this API directly because we havekubectlthat takes care of it for us.kubectltakes our commands, translates them into HTTP requests that the K8s REST API can understand, sends them, and gives us back the results. So, thisapiVersionfield specifies which version of the K8s REST API we are expecting to talk to.kind: It represents the type of object that the configuration file defines. All objects in Kubernetes can be managed via YAML configuration files andkubectl apply. So, this field specifies which one we are managing at any given time.metadata.name: Quite simply, the name of the object. It’s how we and Kubernetes refer to it.metadata.labels: These help us further categorize cluster objects. These have no real effect in the system so they are useful for user help more than anything else.spec: This contains the actual functional specification for the behavior of the deployment. More details below.spec.replicas: The number of replica pods that the deployment should create. We already talked a bit about this before.spec.selector.labels: This is one case when labels are actually important. Remember that when we create deployments, replica sets and pods are created with it. Within the K8s cluster, they each are their own individual objects though. This field is the mechanism that K8s uses to associate a given deployment with its replica set and pods. In practice, that means that whatever labels are in this field need to match the labels inspec.template.metadata.labels. More on that one below.spec.template: Specifies the configuration of the pods that will be part of the deployment.spec.template.metadata.labels: Very similar tometadata.labels. The only difference is that those labels are added to the deployment while these ones are added to the pods. The only notable thing is that these labels are key for the deployment to know which pods it should care about (as explained in above inspec.selector.labels).spec.template.spec: This section specifies the actual functional configuration of the pods.spec.template.spec.containers: This section specifies the configuration of the containers that will be running inside the pods. It’s an array so there can be many. In our example we have only one.spec.template.spec.containers[0].name: The name of the container.spec.template.spec.containers[0].image: The image that will be used to build the container.spec.template.spec.containers[0].ports[0].containerPort: A port through which the container will accept traffic from the outside. In this case,80.
You can find a detailed description of all the fields supported by deployment configuration files in the official API reference documentation. And much more!
Connecting to the containers in the pods
Kubernetes allows us to connect to the containers running inside a pod. This is pretty easy to do with kubectl. All we need to know is the name of the pod and the container that we want to connect to. If the pod is running only one container (like our NGINX one does) then we don’t need the container name. We can find out the names of our pods with:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-66b6c48dd5-85nwq 1/1 Running 0 25s
nginx-deployment-66b6c48dd5-x5b4x 1/1 Running 0 25s
nginx-deployment-66b6c48dd5-wvkhc 1/1 Running 0 25sPick one of those and we can open a bash session in it with:
$ kubectl exec -it nginx-deployment-66b6c48dd5-85nwq -- bashWhich results in a prompt like this:
root@nginx-deployment-66b6c48dd5-85nwq:/#We’re now connected to the container in one of our NGINX pods. There isn’t a lot to do with this right now, but feel free to explore it. It’s got its own processes and file system which are isolated from the other replica pods and your actual machine.
We can also connect to containers via the dashboard. Go back to the dashboard in your browser, log in again if the session expired, and scroll down to the “Pods” section. Each pod in the list has an action menu with an “Exec” command. See it here:
Click it and you’ll be taken to a screen with a console just like the one we obtained via kubectl exec:
The dashboard is quite useful, right?
Services
So far, we’ve learned quite a bit about deployments. How to specify and create them, how to explore them via command line and the dashboard, how to interact with the pods, etc. We haven’t seen a very important part yet, though: actually accessing the application that has been deployed. That’s where services come in. We use services to expose an application running in a set of pods to the world outside the cluster.
Here’s what a configuration file for a service that exposes access to our NGINX deployment could look like:
# nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
selector:
app: nginx
ports:
- name: "http"
port: 80
targetPort: 80
nodePort: 30080Same as with the deployment’s configuration file, this one also has a kind field that specifies what it is; and a name given to it via the metadata.name field. The spec section is where things get interesting.
spec.typespecifies, well… The type of the service. Kubernetes supports many types of services. For now, we want aNodePort. This type of service makes sure to expose itself as a static port (given byspec.ports[0].nodePort) on every node in the cluster. In our setup, we only have one node, which is our own machine.spec.portsdefines which ports of the pods’ containers the service will expose.spec.ports[0].name: The name of the port. To be used elsewhere to reference the specific port.spec.ports[0].port: The port that will be exposed by the service.spec.ports[0].targetPort: The port that the service will target in the container.spec.ports[0].nodePort: The port that the service will expose in all the nodes of the cluster.
Same as with deployments, we can create such a service with the kubectl apply command. If you save the contents from the YAML above into a nginx-service.yaml file, you can run the following to create it:
$ kubectl apply -f nginx-service.yamlAnd to inspect it and validate that it was in fact created:
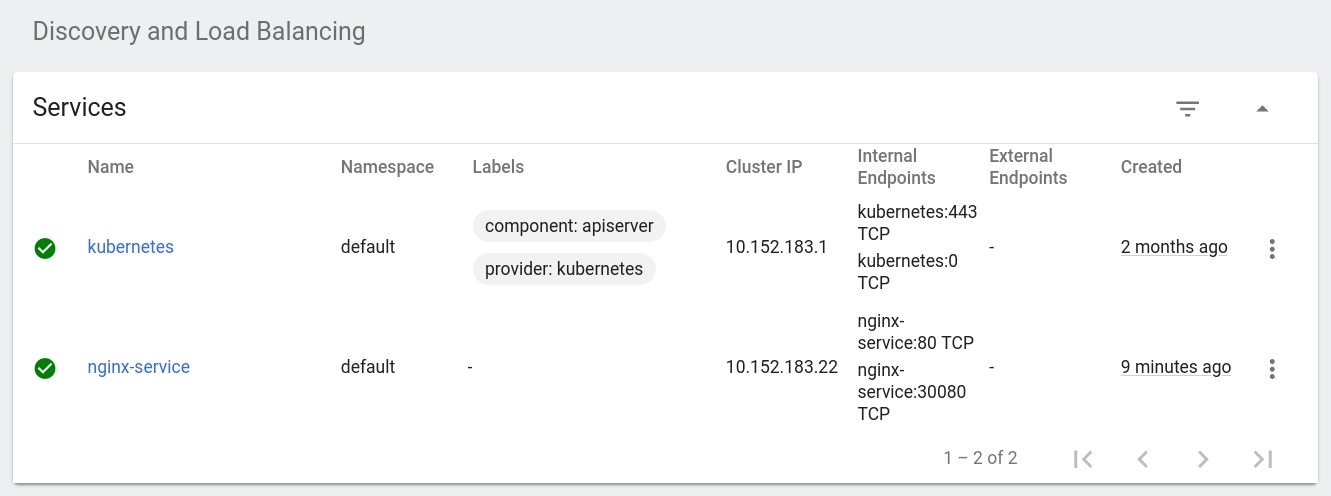
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.152.183.1 <none> 443/TCP 68d
nginx-service NodePort 10.152.183.22 <none> 80:30080/TCP 27sThe dashboard also has a section for services. It looks like this:
Accessing an application via a service
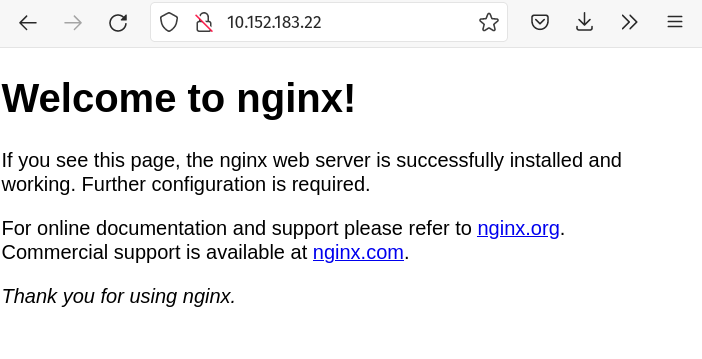
We can access our service in a few different ways. We can use its “cluster IP” which we obtain from the output of the kubectl get services command. As given by the example above, that would be 10.152.183.22 in my case. Browsing to that IP gives us the familiar NGINX default welcome page:
Another way is by using the “NodePort”. Remember that the “NodePort” specifies the port in which the service will be available on every node of the cluster. With our current MicroK8s setup, our own machine is a node in the cluster, so we can also access the NGINX that’s running in our Kubernetes cluster using localhost:30080. 30080 is given by the spec.ports[0].nodePort field in the service configuration file from before. Try it out:
How cool is that? We have identical, replicated NGINX instances running in a Kubernetes cluster that’s installed locally in our machine.
Deploying our own custom application
Alright, by deploying NGINX, we’ve learned a lot about nodes, pods, deployments, services, and how they all work together to run and serve an application from a Kubernetes cluster. Now, let’s take all that knowledge and try to do the same for a completely custom application of our own.
What are we building
The application that we are going to deploy into our cluster is a simple one with only two components: a REST API written with .NET 5 and a Postgres database. You can find the source code in GitHub. It’s an API for supporting a hypothetical front end application for capturing used vehicle information and calculating their value in dollars.
If you’re interested in learning more about the process of actually writing that app, it’s all documented in another blog post: Building REST APIs with .NET 5, ASP.NET Core, and PostgreSQL.
If you’re following along, now would be a good time to download the source code of the web application that we’re going to be playing with. You can find it on GitHub. From now on, we’ll use that as the root directory of all the files we create and modify.
Also, be sure to delete or put aside the
k8sdirectory. We’ll be building that throughout the rest of this post.
Deploying the database
Let’s begin with the Postgres database. Similar as before, we start by setting up a deployment with one pod and one container. We can do so with a deployment configuration YAML file like this:
# db-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vehicle-quotes-db
spec:
selector:
matchLabels:
app: vehicle-quotes-db
replicas: 1
template:
metadata:
labels:
app: vehicle-quotes-db
spec:
containers:
- name: vehicle-quotes-db
image: postgres:13
ports:
- containerPort: 5432
name: "postgres"
env:
- name: POSTGRES_DB
value: vehicle_quotes
- name: POSTGRES_USER
value: vehicle_quotes
- name: POSTGRES_PASSWORD
value: password
resources:
limits:
memory: 4Gi
cpu: "2"This deployment configuration YAML file is similar to the one we used for NGINX before, but it introduces a few new elements:
spec.template.spec.containers[0].ports[0].name: We can give specific names to ports which we can reference later, elsewhere in the K8s configurations, which is what this field is for.spec.template.spec.containers[0].env: This is a list of environment variables that will be defined in the container inside the pod. In this case, we’ve specified a few variables that are necessary to configure the Postgres instance that will be running. We’re using the official Postgres image from Dockerhub, and it calls for these variables. Their purpose is straightforward: they specify database name, username, and password.spec.template.spec.containers[0].resources: This field defines the hardware resources that the container needs in order to function. We can specify upper limits withlimitsand lower ones withrequests. You can learn more about resource management in the official documentation. In our case, we’ve kept it simple and usedlimitsto prevent the container from using more than 4Gi of memory and 2 CPU cores.
Now, let’s save that YAML into a new file called db-deployment.yaml and run the following:
$ kubectl apply -f db-deployment.yamlWhich should output:
deployment.apps/vehicle-quotes-db createdAfter a few seconds, you should be able to see the new deployment and pod via kubectl:
$ kubectl get deployment -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
...
default vehicle-quotes-db 1/1 1 1 9m20s$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
...
default vehicle-quotes-db-5fb576778-gx7j6 1/1 Running 0 9m22sRemember you can also see them in the dashboard:
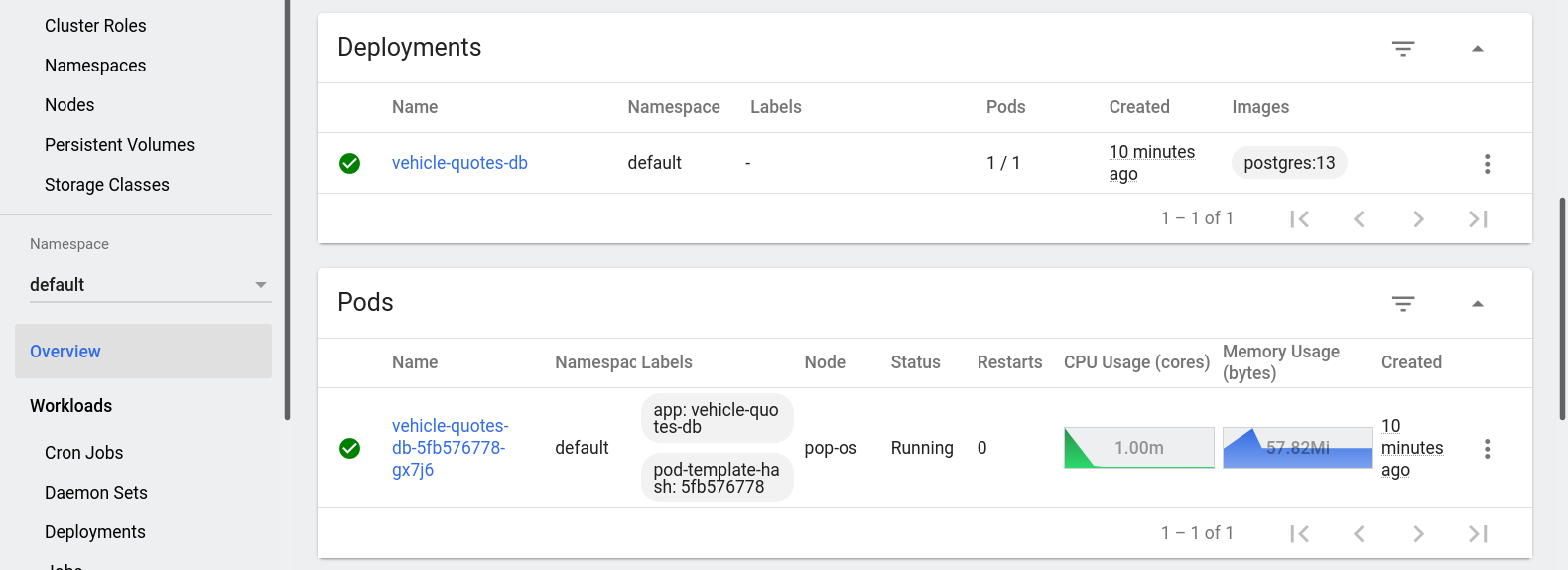
Connecting to the database
Let’s try connecting to the Postgres instance that we just deployed. Take note of the pod’s name and try:
$ kubectl exec -it <DB_POD_NAME> -- bashYou’ll get a bash session on the container that’s running the database. For me, given the pod’s auto-generated name, it looks like this:
root@vehicle-quotes-db-5fb576778-gx7j6:/#From here, you can connect to the database using the psql command line client. Remember that we told the Postgres instance to create a vehicle_quotes user. We set it up via the container environment variables on our deployment configuration. As a result, we can do psql -U vehicle_quotes to connect to the database. Put together, it all looks like this:
$ kubectl exec -it vehicle-quotes-db-5fb576778-gx7j6 -- bash
root@vehicle-quotes-db-5fb576778-gx7j6:/# psql -U vehicle_quotes
psql (13.3 (Debian 13.3-1.pgdg100+1))
Type "help" for help.
vehicle_quotes=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------------+----------------+----------+------------+------------+-----------------------------------
postgres | vehicle_quotes | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | vehicle_quotes | UTF8 | en_US.utf8 | en_US.utf8 | =c/vehicle_quotes +
| | | | | vehicle_quotes=CTc/vehicle_quotes
template1 | vehicle_quotes | UTF8 | en_US.utf8 | en_US.utf8 | =c/vehicle_quotes +
| | | | | vehicle_quotes=CTc/vehicle_quotes
vehicle_quotes | vehicle_quotes | UTF8 | en_US.utf8 | en_US.utf8 |
(4 rows)Pretty cool, don’t you think? We have a database running on our cluster now with minimal effort. There’s a slight problem though…
Persistent volumes and claims
The problem in our database is that any changes are lost if the pod or container were to shut down or reset for some reason. This is because all the database files live inside the container’s file system, so when the container is gone, the data is also gone.
In Kubernetes, pods are supposed to be treated as ephemeral entities. The idea is that pods should easily be brought down and replaced by new pods and users and clients shouldn’t even notice. This is all Kubernetes working as expected. That is to say, pods should be as stateless as possible to work well with this behavior.
However, a database is, by definition, not stateless. So what we need to do to solve this problem is have some available disk space from outside the cluster that can be used by our database to store its files. Something persistent that won’t go away if the pod or container goes away. That’s where persistent volumes and persistent volume claims come in.
We will use a persistent volume (PV) to define a directory in our host machine that we will allow our Postgres container to use to store data files. Then, a persistent volume claim (PVC) is used to define a “request” for some of that available disk space that a specific container can make. In short, a persistent volume says to K8s “here’s some storage that the cluster can use” and a persistent volume claim says “here’s a portion of that storage that’s available for containers to use”.
Configuration files for the PV and PVC
Start by tearing down our currently broken Postgres deployment:
$ kubectl delete -f db-deployment.yamlNow let’s add two new YAML configuration files. One is for the persistent volume:
# db-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: vehicle-quotes-postgres-data-persisent-volume
labels:
type: local
spec:
claimRef:
namespace: default
name: vehicle-quotes-postgres-data-persisent-volume-claim
storageClassName: manual
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/home/kevin/projects/vehicle-quotes-postgres-data"In this config file, we already know about the kind and metadata fields. A few of the other elements are interesting though:
spec.claimRef: Contains identifying information about the claim that’s associated with the PV. Used to bind the PVC with a specific PVC. Notice how it matches the name defined in the PVC config file from below.spec.capacity.storage: Is pretty straightforward in that it specifies the size of the persistent volume.spec.accessModes: Defines how the PV can be accessed. In this case, we’re usingReadWriteOnceso that it can only be used by a single node in the cluster which is allowed to read from and write into the PV.spec.hostPath.path: Specifies the directory in the host machine’s file system where the PV will be mounted. Simply put, the containers in the cluster will have access to the specific directory defined here. I’ve used/home/kevin/projects/vehicle-quotes-postgres-databecause that makes sense on my own machine. If you’re following along, make sure to set it to something that makes sense in your environment.
hostPathis just one type of persistent volume which works well for development deployments. Managed Kubernetes implementations like the ones from Google or Amazon have their own types which are more appropriate for production.
We also need another config file for the persistent volume claim:
# db-persistent-volume-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vehicle-quotes-postgres-data-persisent-volume-claim
spec:
volumeName: vehicle-quotes-postgres-data-persisent-volume
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5GiLike I said, PVCs are essentially usage requests for PVs. So, the config file is simple in that it’s mostly specified to match the PV.
spec.volumeName: The name of the PV that this PVC is going to access. Notice how it matches the name that we defined in the PV’s config file.spec.resources.requests: Defines how much space this PVC requests from the PV. In this case, we’re just requesting all the space that the PV has available to it, as given by its config file:5Gi.
Configuring the deployment to use the PVC
After saving those files, all that’s left is to update the database deployment configuration to use the PVC. Here’s what the updated config file would look like:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vehicle-quotes-db
spec:
selector:
matchLabels:
app: vehicle-quotes-db
replicas: 1
template:
metadata:
labels:
app: vehicle-quotes-db
spec:
containers:
- name: vehicle-quotes-db
image: postgres:13
ports:
- containerPort: 5432
name: "postgres"
+ volumeMounts:
+ - mountPath: "/var/lib/postgresql/data"
+ name: vehicle-quotes-postgres-data-storage
env:
- name: POSTGRES_DB
value: vehicle_quotes
- name: POSTGRES_USER
value: vehicle_quotes
- name: POSTGRES_PASSWORD
value: password
resources:
limits:
memory: 4Gi
cpu: "2"
+ volumes:
+ - name: vehicle-quotes-postgres-data-storage
+ persistentVolumeClaim:
+ claimName: vehicle-quotes-postgres-data-persisent-volume-claim
First, notice the volumes section at the bottom of the file. Here’s where we define the volume that will be available to the container, give it a name and specify which PVC it will use. The spec.template.volumes[0].persistentVolumeClaim.claimName needs to match the name of the PVC that we defined in db-persistent-volume-claim.yaml.
Then, up in the containers section, we define a volumeMounts element. We use that to specify which directory within the container will map to our PV. In this case, we’ve set the container’s /var/lib/postgresql/data directory to use the volume that we defined at the bottom of the file. That volume is backed by our persistent volume claim, which is in turn backed by our persistent volume. The significance of the /var/lib/postgresql/data directory is that this is where Postgres stores database files by default.
In summary: We created a persistent volume that defines some disk space in our machine that’s available to the cluster; then we defined a persistent volume claim that represents a request of some of that space that a container can have access to; after that we defined a volume within our pod configuration in our deployment to point to that persistent volume claim; and finally we defined a volume mount in our container that uses that volume to store the Postgres database files.
By setting it up this way, we’ve made it so that regardless of how many Postgres pods come and go, the database files will always be persisted, because the files now live outside of the container. They are stored in our host machine instead.
There’s another limitation that’s important to note. Just using the approach that we discussed, it’s not possible to deploy multiple replicas of Postgres which work in tandem and operate on the same data. Even though the data files can be defined outside of the cluster and persisted that way, there can only be one single Postgres instance running against it at any given time.
In production, the high availability problem is better solved leveraging the features provided by the database software itself. Postgres offers various options in that area. Or, if you are deploying to the cloud, the best strategy may be to use a relational database service managed by your cloud provider. Examples are Amazon’s RDS and Microsoft’s Azure SQL Database.
Applying changes
Now let’s see it in action. Run the following three commands to create the objects:
$ kubectl apply -f db-persistent-volume.yaml
$ kubectl apply -f db-persistent-volume-claim.yaml
$ kubectl apply -f db-deployment.yamlAfter a while, they will show up in the dashboard. You already know how to look for deployments and pods. For persistent volumes, click the “Persistent Volumes” option under the “Cluster” section in the sidebar:
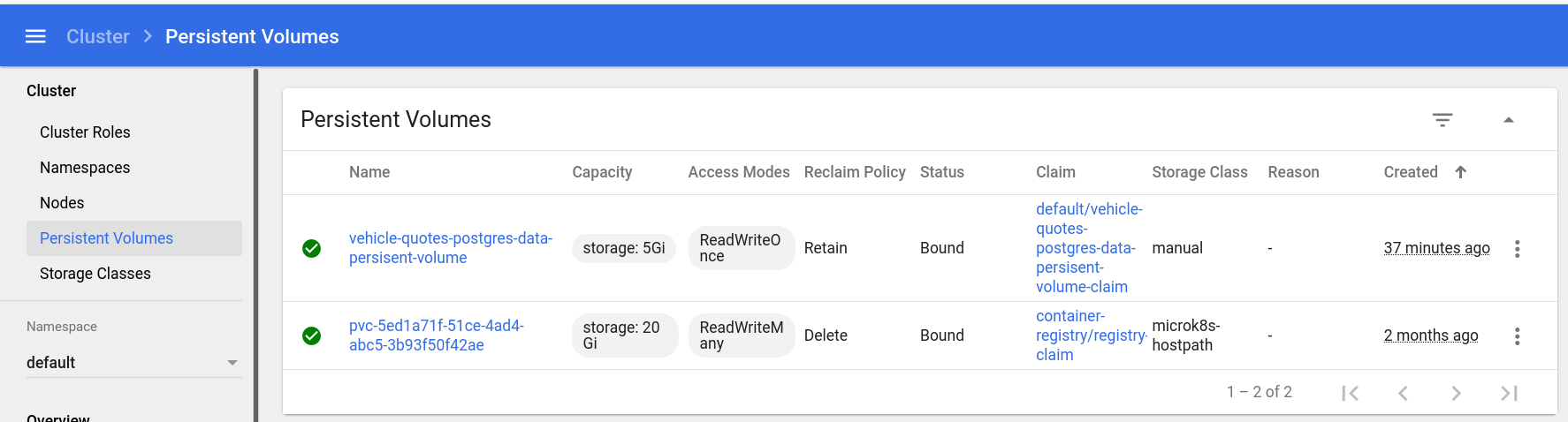
Persistent volume claims can be found in the “Persistent Volume Claims” option under the “Config and Storage” section in the sidebar:
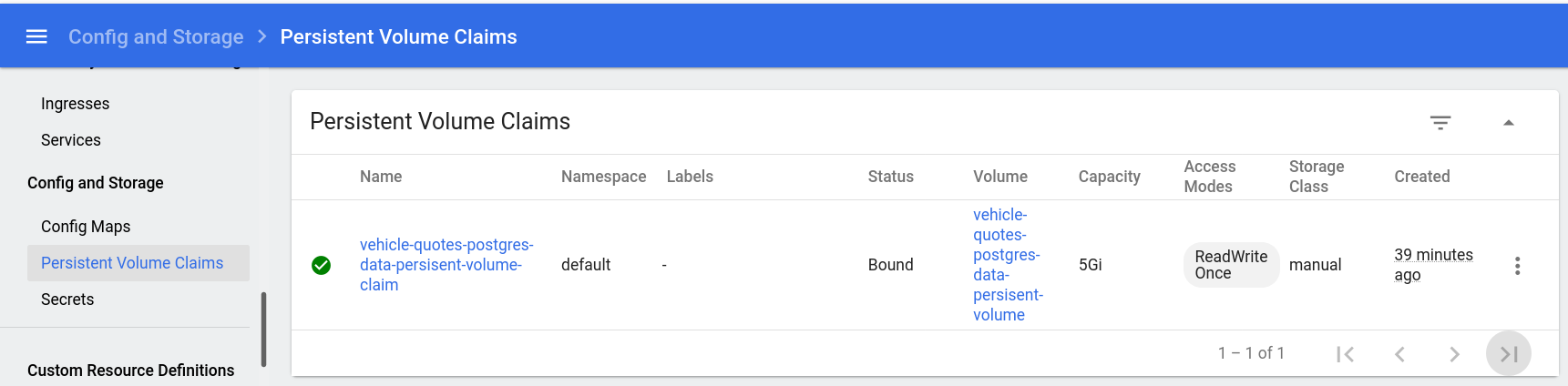
Now, try connecting to the database (using kubectl exec -it <VEHICLE_QUOTES_DB_POD_NAME> -- bash and then psql -U vehicle_quotes) and creating some tables. Something simple like this would work:
CREATE TABLE test (test_field varchar);Now, close psql and the bash in the pod and delete the objects:
$ kubectl delete -f db-deployment.yaml
$ kubectl delete -f db-persistent-volume-claim.yaml
$ kubectl delete -f db-persistent-volume.yamlCreate them again:
$ kubectl apply -f db-persistent-volume.yaml
$ kubectl apply -f db-persistent-volume-claim.yaml
$ kubectl apply -f db-deployment.yamlConnect to the database again and you should see that the table is still there:
vehicle_quotes=# \c vehicle_quotes
You are now connected to database "vehicle_quotes" as user "vehicle_quotes".
vehicle_quotes=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------------
public | test | table | vehicle_quotes
(1 row)That’s just what we wanted: the database is persisting independently of what happens to the pods and containers.
Exposing the database as a service
Lastly, we need to expose the database as a service so that the rest of the cluster can access it without having to use explicit pod names. We don’t need this for our testing, but we do need it for later when we deploy our web app, so that it can reach the database. As you’ve seen, services are easy to create. Here’s the YAML config file:
# db-service.yaml
apiVersion: v1
kind: Service
metadata:
name: vehicle-quotes-db-service
spec:
type: NodePort
selector:
app: vehicle-quotes-db
ports:
- name: "postgres"
protocol: TCP
port: 5432
targetPort: 5432
nodePort: 30432Save that into a new db-service.yaml file and don’t forget to kubectl apply -f db-service.yaml.
Deploying the web application
Now that we’ve got the database sorted out, let’s turn our attention to the app itself. As you’ve seen, Kubernetes runs apps as containers. That means that we need images to build those containers. A custom web application is no exception. We need to build a custom image that contains our application so that it can be deployed into Kubernetes.
Building the web application image
The first step for building a container image is writing a Dockerfile. Since our application is a Web API built using .NET 5, I’m going to use a slightly modified version of the Dockerfile used by Visual Studio Code’s development container demo for .NET. These development containers are excellent for, well… development. You can see the original in the link above, but here’s mine:
# [Choice] .NET version: 5.0, 3.1, 2.1
ARG VARIANT="5.0"
FROM mcr.microsoft.com/vscode/devcontainers/dotnet:0-${VARIANT}
# [Option] Install Node.js
ARG INSTALL_NODE="false"
# [Option] Install Azure CLI
ARG INSTALL_AZURE_CLI="false"
# Install additional OS packages.
RUN apt-get update && export DEBIAN_FRONTEND=noninteractive \
&& apt-get -y install --no-install-recommends postgresql-client-common postgresql-client
# Run the remaining commands as the "vscode" user
USER vscode
# Install EF and code generator development tools
RUN dotnet tool install --global dotnet-ef
RUN dotnet tool install --global dotnet-aspnet-codegenerator
RUN echo 'export PATH="$PATH:/home/vscode/.dotnet/tools"' >> /home/vscode/.bashrc
WORKDIR /app
# Prevent the container from closing automatically
ENTRYPOINT ["tail", "-f", "/dev/null"]There are many other development containers for other languages and frameworks. Take a look at the microsoft/vscode-dev-containers GitHub repo to learn more.
An interesting thing about this Dockerfile is that we install the psql command line client so that we can connect to our Postgres database from within the web application container. The rest is stuff specific to .NET and the particular image we’re basing this Dockerfile on, so don’t sweat it too much.
If you’ve downloaded the source code, this Dockerfile should already be there as Dockerfile.dev.
Making the image accessible to Kubernetes
Now that we have a Dockerfile, we can use it to build an image that Kubernetes is able to use to build a container to deploy. So that Kubernetes can see it, we need to build it in a specific way and push it into a registry that’s accessible to Kubernetes. Remember how we ran microk8s enable registry to install the registry add-on when we were setting up MicroK8s? That will pay off now, as that’s the registry to which we’ll push our image.
First, we build the image:
$ docker build . -f Dockerfile.dev -t localhost:32000/vehicle-quotes-dev:registryThat will take some time to download and set up everything. Once that’s done, we push the image to the registry:
$ docker push localhost:32000/vehicle-quotes-dev:registryThat will also take a little while.
Deploying the web application
The next step is to create a deployment for the web app. Like usual, we start with a deployment YAML configuration file. Let’s call it web-deployment.yaml:
# web-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vehicle-quotes-web
spec:
selector:
matchLabels:
app: vehicle-quotes-web
replicas: 1
template:
metadata:
labels:
app: vehicle-quotes-web
spec:
containers:
- name: vehicle-quotes-web
image: localhost:32000/vehicle-quotes-dev:registry
ports:
- containerPort: 5000
name: "http"
- containerPort: 5001
name: "https"
volumeMounts:
- mountPath: "/app"
name: vehicle-quotes-source-code-storage
env:
- name: POSTGRES_DB
value: vehicle_quotes
- name: POSTGRES_USER
value: vehicle_quotes
- name: POSTGRES_PASSWORD
value: password
- name: CUSTOMCONNSTR_VehicleQuotesContext
value: Host=$(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST);Database=$(POSTGRES_DB);Username=$(POSTGRES_USER);Password=$(POSTGRES_PASSWORD)
resources:
limits:
memory: 2Gi
cpu: "1"
volumes:
- name: vehicle-quotes-source-code-storage
persistentVolumeClaim:
claimName: vehicle-quotes-source-code-persisent-volume-claimThis deployment configuration should look very familiar to you by now as it is very similar to the ones we’ve already seen. There are a few notable elements though:
- Notice how we specified
localhost:32000/vehicle-quotes-dev:registryas the container image. This is the exact same name of the image that we built and pushed into the registry before. - In the environment variables section, the one named
CUSTOMCONNSTR_VehicleQuotesContextis interesting for a couple of reasons:- First, the value is a Postgres connection string being built off of other environment variables using the following format:
$(ENV_VAR_NAME). That’s a neat feature of Kubernetes config files that allows us to reference variables to build other ones. - Second, the
VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOSTenvironment variable used within that connection string is not defined anywhere in our configuration files. That’s an automatic environment variable that Kubernetes injects on all containers when there are services available. In this case, it contains the hostname of thevehicle-quotes-db-servicethat we created a few sections ago. The automatic injection of this*_SERVICE_HOSTvariable always happens as long as the service is already created by the time that the pod gets created. We have already created the service so we should be fine using the variable here. As usual, there’s more info in the official documentation.
- First, the value is a Postgres connection string being built off of other environment variables using the following format:
As you may have noticed, this deployment has a persistent volume. That’s to store the application’s source code. Or, more accurately, to make the source code, which lives in our machine, available to the container. This is a development setup after all, so we want to be able to edit the code from the comfort of our own file system, and have the container inside the cluster be aware of that.
Anyway, let’s create the associated persistent volume and persistent volume claim. Here’s the PV (save it as web-persistent-volume.yaml):
# web-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: vehicle-quotes-source-code-persisent-volume
labels:
type: local
spec:
claimRef:
namespace: default
name: vehicle-quotes-source-code-persisent-volume-claim
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/home/kevin/projects/vehicle-quotes"And here’s the PVC (save it as web-persistent-volume-claim.yaml):
# web-persistent-volume-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vehicle-quotes-source-code-persisent-volume-claim
spec:
volumeName: vehicle-quotes-source-code-persisent-volume
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiThe only notable element here is the PV’s hostPath. I have it pointing to the path where I downloaded the app’s source code from GitHub. Make sure to do the same on your end.
Finally, tie it all up with a service that will expose the development build of our REST API. Here’s the config file:
# web-service.yaml
apiVersion: v1
kind: Service
metadata:
name: vehicle-quotes-web-service
spec:
type: NodePort
selector:
app: vehicle-quotes-web
ports:
- name: "http"
protocol: TCP
port: 5000
targetPort: 5000
nodePort: 30000
- name: "https"
protocol: TCP
port: 5001
targetPort: 5001
nodePort: 30001Should be pretty self-explanatory at this point. In this case, we expose two ports, one for HTTP and another for HTTPS. Our .NET 5 Web API works with both so that’s why we specify them here. This configuration says that the service should expose port 30000 and send traffic that comes into that port from the outside world into port 5000 on the container. Likewise, outside traffic coming to port 30001 will be sent to port 5001 in the container.
Save that file as web-service.yaml and we’re ready to apply the changes:
$ kubectl apply -f web-persistent-volume.yaml
$ kubectl apply -f web-persistent-volume-claim.yaml
$ kubectl apply -f web-deployment.yaml
$ kubectl apply -f web-service.yamlFeel free to explore the dashboard’s “Deployments”, “Pods”, “Services”, “Persistent Volumes”, and “Persistent Volume Claims” sections to see the fruits of our labor.
Starting the application
Let’s now do some final setup and start up our application. Start by connecting to the web application pod:
$ kubectl exec -it vehicle-quotes-web-86cbc65c7f-5cpg8 -- bashRemember that the pod name will be different for you, so copy it from the dashboard or
kubectl get pods -A.
You’ll get a prompt like this:
vscode ➜ /app (master ✗) $Try ls to see all of the app’s source code files courtesy of the PV that we set up before:
vscode ➜ /app (master ✗) $ ls
Controllers Dockerfile.prod Models README.md Startup.cs appsettings.Development.json k8s queries.sql
Data K8S_README.md Program.cs ResourceModels Validations appsettings.json k8s_wip
Dockerfile.dev Migrations Properties Services VehicleQuotes.csproj database.dbml objNow it’s just a few .NET commands to get the app up and running. First, compile and download packages:
$ dotnet buildThat will take a while. Once done, let’s build the database schema:
$ dotnet ef database updateAnd finally, run the development web server:
$ dotnet runIf you get the error message “System.InvalidOperationException: Unable to configure HTTPS endpoint.” while trying
dotnet run, follow the error message’s instructions and rundotnet dev-certs https --trust. This will generate a development certificate so that the dev server can serve HTTPS.
As a result, you should see this:
vscode ➜ /app (master ✗) $ dotnet run
Building...
info: Microsoft.Hosting.Lifetime[0]
Now listening on: https://0.0.0.0:5001
info: Microsoft.Hosting.Lifetime[0]
Now listening on: http://0.0.0.0:5000
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
info: Microsoft.Hosting.Lifetime[0]
Hosting environment: Development
info: Microsoft.Hosting.Lifetime[0]
Content root path: /appIt indicates that the application is up and running. Now, navigate to http://localhost:30000 in your browser of choice and you should see our REST API’s Swagger UI:
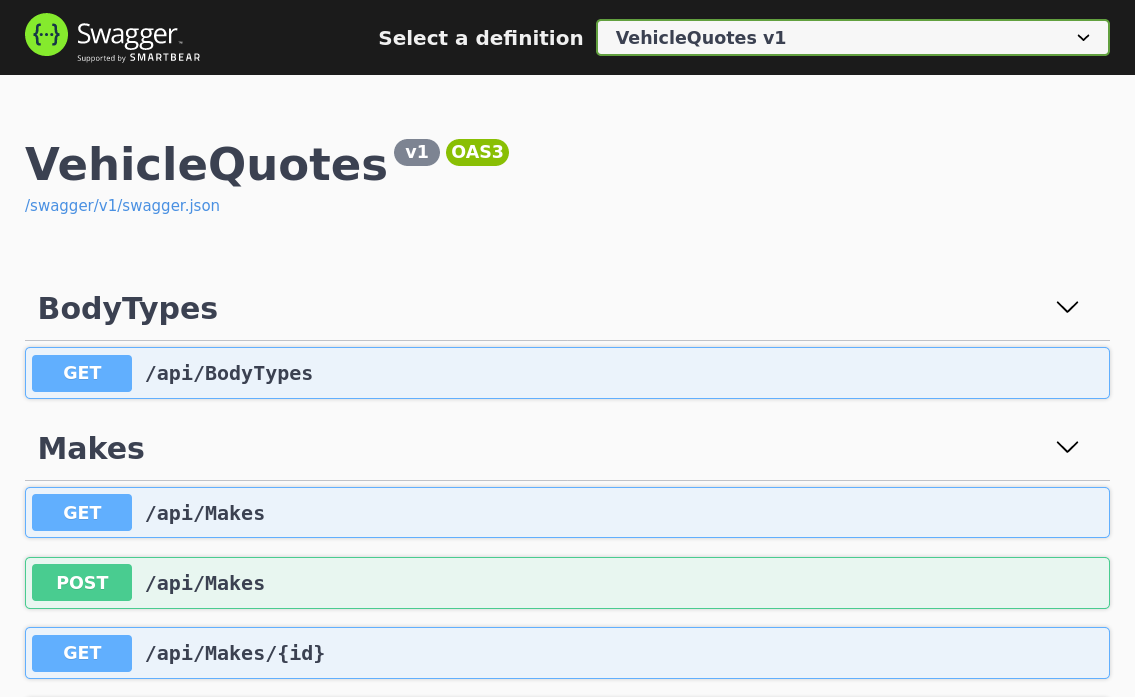
Notice that 30000 is the port we specified in the web-service.yaml’s nodePort for the http port. That’s the port that the service exposes to the world outside the cluster. Notice also how our .NET web app’s development server listens to traffic coming from ports 5000 and 5001 for HTTP and HTTPS respectively. That’s why we configured web-service.yaml like we did.
Outstanding! All our hard work has paid off and we have a full-fledged web application running in our Kubernetes cluster. This is quite a momentous occasion. We’ve built a custom image that can be used to create containers to run a .NET web application, pushed that image into our local registry so that K8s could use it, and deployed a functioning application. As a cherry on top, we made it so the source code is super easy to edit, as it lives within our own machine’s file system and the container in the cluster accesses it directly from there. Quite an accomplishment.
Now it’s time to go the extra mile and organize things a bit. Let’s talk about Kustomize next.
Putting it all together with Kustomize
Kustomize is a tool that helps us improve Kubernetes’ declarative object management with configuration files (which is what we’ve been doing throughout this post). Kustomize has useful features that help with better organizing configuration files, managing configuration variables, and support for deployment variants (for things like dev vs. test vs. prod environments). Let’s explore what Kustomize has to offer.
First, be sure to tear down all the objects that we have created so far as we will be replacing them later once we have a setup with Kustomize. This will work for that:
$ kubectl delete -f db-service.yaml
$ kubectl delete -f db-deployment.yaml
$ kubectl delete -f db-persistent-volume-claim.yaml
$ kubectl delete -f db-persistent-volume.yaml
$ kubectl delete -f web-service.yaml
$ kubectl delete -f web-deployment.yaml
$ kubectl delete -f web-persistent-volume-claim.yaml
$ kubectl delete -f web-persistent-volume.yamlNext, let’s reorganize our db-* and web-* YAML files like this:
k8s
├── db
│ ├── db-deployment.yaml
│ ├── db-persistent-volume-claim.yaml
│ ├── db-persistent-volume.yaml
│ └── db-service.yaml
└── web
├── web-deployment.yaml
├── web-persistent-volume-claim.yaml
├── web-persistent-volume.yaml
└── web-service.yamlAs you can see, we’ve put them all inside a new k8s directory, and further divided them into db and web sub-directories. web-* files went into the web directory and db-* files went into db. At this point, the prefixes on the files are a bit redundant so we can remove them. After all, we know what component they belong to because of the name of their respective sub-directories.
There’s already a
k8sdirectory in the repo. Feel free to get rid of it as we will build it back up from scratch now.
So it should end up looking like this:
k8s
├── db
│ ├── deployment.yaml
│ ├── persistent-volume-claim.yaml
│ ├── persistent-volume.yaml
│ └── service.yaml
└── web
├── deployment.yaml
├── persistent-volume-claim.yaml
├── persistent-volume.yaml
└── service.yamlkubectl’s
applyanddeletecommands support directories as well, not only individual files. That means that, at this point, to build up all of our objects you could simply dokubectl apply -f k8s/dbandkubectl apply -f k8s/web. This is much better than what we’ve been doing until now where we had to specify every single file. Still, with Kustomize, we can do better than that…
The Kustomization file
We can bring everything together with a kustomization.yaml file. For our setup, here’s what it could look like:
# k8s/kustomization.yaml
kind: Kustomization
resources:
- db/persistent-volume.yaml
- db/persistent-volume-claim.yaml
- db/service.yaml
- db/deployment.yaml
- web/persistent-volume.yaml
- web/persistent-volume-claim.yaml
- web/service.yaml
- web/deployment.yamlThis first iteration of the Kustomization file is simple. It just lists all of our other config files in the resources section in their relative locations. Save that as k8s/kustomization.yaml and you can apply it with the following:
$ kubectl apply -k k8sThe -k option tells kubectl apply to look for a Kustomization within the given directory and use that to build the cluster objects. After running it, you should see familiar output:
service/vehicle-quotes-db-service created
service/vehicle-quotes-web-service created
persistentvolume/vehicle-quotes-postgres-data-persisent-volume created
persistentvolume/vehicle-quotes-source-code-persisent-volume created
persistentvolumeclaim/vehicle-quotes-postgres-data-persisent-volume-claim created
persistentvolumeclaim/vehicle-quotes-source-code-persisent-volume-claim created
deployment.apps/vehicle-quotes-db created
deployment.apps/vehicle-quotes-web createdFeel free to explore the dashboard or kubectl get commands to see the objects that got created. You can connect to pods, run the app, query the database, everything. Just like we did before. The only difference is that now everything is neatly organized and there’s a single file that serves as bootstrap for the whole setup. All thanks to Kustomize and the -k option.
kubectl delete -k k8s can be used to tear everything down.
Defining reusable configuration values with ConfigMaps
Another useful feature of Kustomize is ConfigMaps. These allow us to specify configuration variables in the Kustomization and use them throughout the rest of the resource config files. A good candidate to demonstrate their use are the environment variables that configure our Postgres database and the connection string in our web application.
We’re going to make changes to the config so be sure to tear everything down with kubectl delete -k k8s.
We can start by adding the following to the kustomization.yaml file:
# k8s/kustomization.yaml
kind: Kustomization
resources:
- db/persistent-volume.yaml
- db/persistent-volume-claim.yaml
- db/service.yaml
- db/deployment.yaml
- web/persistent-volume.yaml
- web/persistent-volume-claim.yaml
- web/service.yaml
- web/deployment.yaml
+configMapGenerator:
+ - name: postgres-config
+ literals:
+ - POSTGRES_DB=vehicle_quotes
+ - POSTGRES_USER=vehicle_quotes
+ - POSTGRES_PASSWORD=password
The configMapGenerator section is where the magic happens. We’ve kept it simple and defined the variables as literals. configMapGenerator is much more flexible than that though, accepting external configuration files. The official documentation has more details.
Now, let’s see what we have to do to actually use those values in our configuration.
First up is the database deployment configuration file, k8s/db/deployment.yaml. Update its env section like so:
# k8s/db/deployment.yaml
# ...
env:
- - name: POSTGRES_DB
- value: vehicle_quotes
- - name: POSTGRES_USER
- value: vehicle_quotes
- - name: POSTGRES_PASSWORD
- value: password
+ - name: POSTGRES_DB
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_DB
+ - name: POSTGRES_USER
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_USER
+ - name: POSTGRES_PASSWORD
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_PASSWORD
# ...
Notice how we’ve replaced the simple key-value pairs with new, more complex objects. Their names are still the same, they have to be because that’s what the Postgres database container expects. But instead of a literal, hard-coded value, we have changed them to these valueFrom.configMapKeyRef objects. Their names match the name of the configMapGenerator we configured in the Kustomization. Their keys match the keys of the literal values that we specified in the configMapGenerator’s literals field. That’s how it all ties together.
Similarly, we can update the web application deployment configuration file, k8s/web/deployment.yaml. Its env section would look like this:
# k8s/web/deployment.yaml
# ...
env:
- - name: POSTGRES_DB
- value: vehicle_quotes
- - name: POSTGRES_USER
- value: vehicle_quotes
- - name: POSTGRES_PASSWORD
- value: password
+ - name: POSTGRES_DB
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_DB
+ - name: POSTGRES_USER
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_USER
+ - name: POSTGRES_PASSWORD
+ valueFrom:
+ configMapKeyRef:
+ name: postgres-config
+ key: POSTGRES_PASSWORD
- name: CUSTOMCONNSTR_VehicleQuotesContext
value: Host=$(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST);Database=$(POSTGRES_DB);Username=$(POSTGRES_USER);Password=$(POSTGRES_PASSWORD)
# ...
This is the exact same change as with the database deployment. Out with the hard coded values and in with the new ConfigMap-driven ones.
Try kubectl apply -k k8s and you’ll see that things are still working well. Try to connect to the web application pod and build and run the app.
For data that’s important to secure like passwords, tokens, and keys, Kubernetes and Kustomize also offer Secrets and
secretGenerator. Secrets are very similar to ConfigMaps in how they work, but are tailored specifically for handling secret data. You can learn more about them in the official documentation.
Creating variants for production and development environments
The crowning achievement of Kustomize is its ability to facilitate multiple deployment variants. Variants, as the name suggests, are variations of deployment configurations that are ideal for setting up various execution environments for an application. Think development, staging, production, etc., all based on a common set of reusable configurations to avoid superfluous repetition.
Kustomize does this by introducing the concepts of bases and overlays. A base is a set of configs that can be reused but not deployed on its own, and overlays are the actual configurations that use and extend the base and can be deployed.
To demonstrate this, let’s build two variants: one for development and another for production. Let’s consider the one we’ve already built to be the development variant and work towards properly specifying it as so, and then building a new production variant.
Note that the so-called “production” variant we’ll build is not actually meant to be production worthy. It’s just an example to illustrate the concepts and process of building bases and overlays. It does not meet the rigors of a proper production system.
Creating the base and overlays
The strategy I like to use is to just copy everything over from one variant to another, implement the differences, identify the common elements, and extract them into a base that both use.
Let’s begin by creating a new k8s/dev directory and move all of our YAML files into it. That will be our “development overlay”. Then, make a copy the k8s/dev directory and all of its contents and call it k8s/prod. That will be our “production overlay”. Let’s also create a k8s/base directory to store the common files. That will be our “base”. It should be like this:
k8s
├── base
├── dev
│ ├── kustomization.yaml
│ ├── db
│ │ ├── deployment.yaml
│ │ ├── persistent-volume-claim.yaml
│ │ ├── persistent-volume.yaml
│ │ └── service.yaml
│ └── web
│ ├── deployment.yaml
│ ├── persistent-volume-claim.yaml
│ ├── persistent-volume.yaml
│ └── service.yaml
└── prod
├── kustomization.yaml
├── db
│ ├── deployment.yaml
│ ├── persistent-volume-claim.yaml
│ ├── persistent-volume.yaml
│ └── service.yaml
└── web
├── deployment.yaml
├── persistent-volume-claim.yaml
├── persistent-volume.yaml
└── service.yamlNow we have two variants, but they don’t do us any good because they aren’t any different. We’ll now go through each file one by one and identify which aspects need to be the same and which need to be different between our two variants:
db/deployment.yaml: I want the same database instance configuration for both our variants. So we copy the file intobase/db/deployment.yamland deletedev/db/deployment.yamlandprod/db/deployment.yaml.db/persistent-volume-claim.yaml: This one is also the same for both variants. So we copy the file intobase/db/persistent-volume-claim.yamland deletedev/db/persistent-volume-claim.yamlandprod/db/persistent-volume-claim.yaml.db/persistent-volume.yaml: This file defines the location in the host machine that will be available for the Postgres instance that’s running in the cluster to store its data files. I do want this path to be different between variants. So let’s leave them where they are and do the following changes to them: Fordev/db/persistent-volume.yaml, change itsspec.hostPath.pathto"/path/to/vehicle-quotes-postgres-data-dev". Forprod/db/persistent-volume.yaml, change itsspec.hostPath.pathto"/path/to/vehicle-quotes-postgres-data-prod". Of course, adjust the paths to something that makes sense in your environment.db/service.yaml: There doesn’t need to be any difference in this file between the variants so we copy it intobase/db/service.yamland deletedev/db/service.yamlandprod/db/service.yaml.web/deployment.yaml: There are going to be quite a few differences between the dev and prod deployments of the web application. So we leave them as they are. Later we’ll see the differences in detail.web/persistent-volume-claim.yaml: This is also going to be different. Let’s leave it be now and we’ll come back to it later.web/persistent-volume.yaml: Same asweb/persistent-volume-claim.yaml. Leave it be for now.wev/service.yaml: This one is going to be the same for both dev and prod so let’s do the usual and copy it intobase/web/service.yamland removedev/web/service.yamlandprod/web/service.yaml
The decisions made when designing these overlays and the base may seem arbitrary. That’s because they totally are. The purpose of this article is to demonstrate Kustomize’s features, not produce a real-world, production-worthy setup.
Once all those changes are done, you should have the following file structure:
k8s
├── base
│ ├── db
│ │ ├── deployment.yaml
│ │ ├── persistent-volume-claim.yaml
│ │ └── service.yaml
│ └── web
│ └── service.yaml
├── dev
│ ├── kustomization.yaml
│ ├── db
│ │ └── persistent-volume.yaml
│ └── web
│ ├── deployment.yaml
│ ├── persistent-volume-claim.yaml
│ └── persistent-volume.yaml
└── prod
├── kustomization.yaml
├── db
│ └── persistent-volume.yaml
└── web
├── deployment.yaml
├── persistent-volume-claim.yaml
└── persistent-volume.yamlMuch better, huh? We’ve gotten rid of quite a bit of repetition. But we’re not done just yet. The base also needs a Kustomization file. Let’s create it as k8s/base/kustomization.yaml and add these contents:
# k8s/base/kustomization.yaml
kind: Kustomization
resources:
- db/persistent-volume-claim.yaml
- db/service.yaml
- db/deployment.yaml
- web/service.yaml
configMapGenerator:
- name: postgres-config
literals:
- POSTGRES_DB=vehicle_quotes
- POSTGRES_USER=vehicle_quotes
- POSTGRES_PASSWORD=passwordAs you can see, the file is very similar to the other one we created. We just list the resources that we moved into the base directory and define the database environment variables via the configMapGenerator. We need to define the configMapGenerator here because we’ve moved all the other files that use them into here.
Now that we have the base defined, we need to update the kustomization.yaml files of the overlays to use it. We also need to update them so that they only point to the resources that they need to.
Here’s how the changes to the “dev” overlay’s kustomization.yaml file look:
# dev/kustomization.yaml
kind: Kustomization
+bases:
+ - ../base
resources:
- db/persistent-volume.yaml
- - db/persistent-volume-claim.yaml
- - db/service.yaml
- - db/deployment.yaml
- web/persistent-volume.yaml
- web/persistent-volume-claim.yaml
- - web/service.yaml
- web/deployment.yaml
-configMapGenerator:
- - name: postgres-config
- literals:
- - POSTGRES_DB=vehicle_quotes
- - POSTGRES_USER=vehicle_quotes
- - POSTGRES_PASSWORD=password
As you can see we removed the configMapGenerator and the individual resources that were already defined in the base. Most importantly, we’ve added a bases element that indicates that our Kustomization over on the base directory is this overlay’s base.
The changes to the “prod” overlay’s kustomization.yaml file are identical. Go ahead and make them.
At this point, you can run kubectl apply -k k8s/dev or kubectl apply -k k8s/prod and things should work just like before.
Don’t forget to also do
kubectl delete -k k8s/devorkubectl delete -k k8s/prodwhen you’re done testing the previous commands, as we’ll continue doing changes to the configs. Keep in mind also that both variants can’t be deployed at the same time. So be suredeleteone beforeapplying the other.
Developing the production variant
I want our production variant to use a different image for the web application. That means a new Dockerfile. If you downloaded the source code from the GitHub repo, you should see the production Dockerfile in the root directory of the repo. It’s called Dockerfile.prod.
Here’s what it looks like:
# Dockerfile.prod
ARG VARIANT="5.0"
FROM mcr.microsoft.com/dotnet/sdk:${VARIANT}
RUN apt-get update && export DEBIAN_FRONTEND=noninteractive \
&& apt-get -y install --no-install-recommends postgresql-client-common postgresql-client
RUN dotnet tool install --global dotnet-ef
ENV PATH $PATH:/root/.dotnet/tools
RUN dotnet dev-certs https
WORKDIR /source
COPY . .
ENTRYPOINT ["tail", "-f", "/dev/null"]The first takeaway from this production Dockerfile is that it is simpler, when compared to the development one. The image here is based on the official dotnet/sdk instead of the dev-ready one from vscode/devcontainers/dotnet. Also, this Dockerfile just copies all the source code into a /source directory within the image. This is because we want to “ship” the image with everything it needs to work without too much manual intervention. Also, we won’t be editing code live on the container, as opposed to how we set up the dev variant which allowed that. So we just copy the files over instead of leaving them out to provision them later via volumes. We’ll see how that pans out later.
Now that we have our production Dockerfile, we can build an image with it and push it to the registry so that Kubernetes can use it. So, save that file as Dockerfile.prod (or just use the one that’s already in the repo), and run the following commands:
Build the image with:
$ docker build . -f Dockerfile.prod -t localhost:32000/vehicle-quotes-prod:registryAnd push it to the registry with:
$ docker push localhost:32000/vehicle-quotes-prod:registryNow, we need to modify our prod variant’s deployment configuration so that it can work well with this new prod image. Here’s how the new k8s/prod/web/deployment.yaml should look:
# k8s/prod/web/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vehicle-quotes-web
spec:
selector:
matchLabels:
app: vehicle-quotes-web
replicas: 1
template:
metadata:
labels:
app: vehicle-quotes-web
spec:
initContainers:
- name: await-db-ready
image: postgres:13
command: ["/bin/sh"]
args: ["-c", "until pg_isready -h $(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST) -p 5432; do echo waiting for database; sleep 2; done;"]
- name: build
image: localhost:32000/vehicle-quotes-dev:registry
workingDir: "/source"
command: ["/bin/sh"]
args: ["-c", "dotnet restore -v n && dotnet ef database update && dotnet publish -c release -o /app --no-restore"]
volumeMounts:
- mountPath: "/app"
name: vehicle-quotes-source-code-storage
env:
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_PASSWORD
- name: CUSTOMCONNSTR_VehicleQuotesContext
value: Host=$(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST);Database=$(POSTGRES_DB);Username=$(POSTGRES_USER);Password=$(POSTGRES_PASSWORD)
containers:
- name: vehicle-quotes-web
image: localhost:32000/vehicle-quotes-dev:registry
workingDir: "/app"
command: ["/bin/sh"]
args: ["-c", "dotnet VehicleQuotes.dll --urls=https://0.0.0.0:5001/"]
ports:
- containerPort: 5001
name: "https"
volumeMounts:
- mountPath: "/app"
name: vehicle-quotes-source-code-storage
env:
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
configMapKeyRef:
name: postgres-config
key: POSTGRES_PASSWORD
- name: CUSTOMCONNSTR_VehicleQuotesContext
value: Host=$(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST);Database=$(POSTGRES_DB);Username=$(POSTGRES_USER);Password=$(POSTGRES_PASSWORD)
resources:
limits:
memory: 2Gi
cpu: "1"
volumes:
- name: vehicle-quotes-source-code-storage
emptyDir: {}This deployment config is similar to the one from the dev variant, but we’ve changed a few elements on it.
Init containers
The most notable change is that we added an initContainers section. Init Containers are one-and-done containers that run specific processes during pod initialization. They are good for doing any sort of initialization tasks that need to be run once, before a pod is ready to work. After they’ve done their task, they go away, and the pod is left with the containers specified in the containers section, like usual. In this case, we’ve added two init containers.
First is the await-db-ready one. This is a simple container based on the postgres:13 image that just sits there waiting for the database to become available. This is thanks to its command and args, which make up a simple shell script that leverages the pg_isready tool to continuously check if connections can be made to our database:
command: ["/bin/sh"]
args: ["-c", "until pg_isready -h $(VEHICLE_QUOTES_DB_SERVICE_SERVICE_HOST) -p 5432; do echo waiting for database; sleep 2; done;"]This will cause pod initialization to stop until the database is ready.
Thanks to this blog post for the very useful recipe.
We need to wait for the database to be ready before continuing because of what the second init container does. Among other things, the build init container sets up the database. The database needs to be available for it to be able to to do that. The init container also downloads dependencies, builds the app, produces the deployable artifacts and copies them over to the directory from which the app will run: /app. You can see that all that is specified in the command and args elements, which define a few shell commands to do those tasks.
command: ["/bin/sh"]
args: ["-c", "dotnet restore -v n && dotnet ef database update && dotnet publish -c release -o /app --no-restore"]Another interesting aspect of this deployment is the volume that we’ve defined. It’s at the bottom of the file, take a quick look:
volumes:
- name: vehicle-quotes-source-code-storage
emptyDir: {}This one is different from the ones we’ve seen before which relied on persistent volumes and persistent volume claims. This one uses emptyDir. This means that this volume will provide storage that is persistent throughout the lifetime of the pod. That is, not tied to any specific container. In other words, even when the container goes away, the files in this volume will stay. This is a mechanism that’s useful when we want one container to produce some files that another container will use. In our case, the build init container produces the artifacts/binaries that the main vehicle-quotes-web container will use to actually run the web app.
The only other notable difference of this deployment is how its containers use the new prod image that we built before, instead of the dev one. That is, it uses localhost:32000/vehicle-quotes-prod:registry instead of localhost:32000/vehicle-quotes-dev:registry.
The rest of the deployment doesn’t have anything we haven’t already seen. Feel free to explore it.
As you saw, this prod variant doesn’t need to access the source code via a persistent volume. So, we don’t need PV and PVC definitions for it. So feel free to delete k8s/prod/web/persistent-volume.yaml and k8s/prod/web/persistent-volume-claim.yaml. Remember to also remove them from the resources section in k8s/prod/kustomization.yaml.
With those changes done, we can fire up our prod variants with:
$ kubectl apply -k k8s/prodThe web pod will take quite a while to properly start up because it’s downloading a lot of dependencies. Remember that you can use kubectl get pods -A to see their current status. Take note of their names and you would also be able to see container specific logs.
- Use
kubectl logs -f <vehicle-quotes-web-pod-name> await-db-readyto see the logs from theawait-db-readyinit container. - Use
kubectl logs -f <vehicle-quotes-web-pod-name> buildto see the logs from thebuildinit container.
If this were an actual production setup, and we were worried about pod startup time, there’s one way we could make it faster. We could perform the “download dependencies” step when building the production image instead of when deploying the pods. So, we could have our
Dockerfile.prodcalldotnet restore -v n, instead of thebuildinit container. That way building the image would take more time, but it would have all dependencies already baked in by the time Kubernetes tries to use it to build containers. Then the web pod would start up much faster.
This deployment automatically starts the web app, so after the pods are in the “Running” status (or green in the dashboard!), we can just navigate to the app via a web browser. We’ve configured the deployment to only work over HTTPS (as given by the ports section in the vehicle-quotes-web container), so this is the only URL that’s available to us: https://localhost:30001. We can navigate to it and see the familiar screen:
At this point, we finally have fully working, distinct variants. However, we can take our configuration a few steps further by leveraging some additional Kustomize features.
Using patches for small, precise changes
Right now, the persistent volume configurations for the databases of both variants are pretty much identical. The only difference is the hostPath. With patches, we can focus in on that property and vary it specifically.
To do it, we first copy either of the variant’s db/persistent-volume.yaml into k8s/base/db/persistent-volume.yaml. We also need to add it under resources on k8s/base/kustomization.yaml:
# k8s/base/kustomization.yaml
# ...
resources:
+ - db/persistent-volume.yaml
- db/persistent-volume-claim.yaml
# ...
That will serve as the common ground for overlays to “patch over”. Now we can create the patches. First, the one for the one for the dev variant:
# k8s/dev/db/persistent-volume-host-path.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: vehicle-quotes-postgres-data-persisent-volume
spec:
hostPath:
path: "/home/kevin/projects/vehicle-quotes-postgres-data-dev"And then the one for the prod variant:
# k8s/prod/db/persistent-volume-host-path.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: vehicle-quotes-postgres-data-persisent-volume
spec:
hostPath:
path: "/home/kevin/projects/vehicle-quotes-postgres-data-prod"As you can see, these patches are sort of truncated persistent volume configs which only include the kind, metadata.name, and the value that actually changes: the hostPath.
Once those are saved, we need to include them in their respective kustomization.yaml. It’s the same modification to both k8s/dev/kustomization.yaml and k8s/prod/kustomization.yaml. Just remove the db/persistent-volume.yaml item from their resources sections and add the following to both of them:
patches:
- db/persistent-volume-host-path.yamlRight now, k8s/dev/kustomization.yaml should be:
# k8s/dev/kustomization.yaml
kind: Kustomization
bases:
- ../base
resources:
- web/persistent-volume.yaml
- web/persistent-volume-claim.yaml
- web/deployment.yaml
patches:
- db/persistent-volume-host-path.yamlAnd k8s/prod/kustomization.yaml should be:
# k8s/prod/kustomization.yaml
kind: Kustomization
bases:
- ../base
resources:
- web/deployment.yaml
patches:
- db/persistent-volume-host-path.yamlOverriding container images
Another improvement we can make is to use the images element in the kustomization.yaml files to control the web app images used by the deployments in the variants. This is easier for maintenance as it’s defined in one single, expected place. Also, the full name of the image doesn’t have to be used throughout the configs so it reduces repetition.
To put it in practice, add the following at the end of the k8s/dev/kustomization.yaml file:
images:
- name: vehicle-quotes-web
newName: localhost:32000/vehicle-quotes-dev
newTag: registrySimilar thing with k8s/prod/kustomization.yaml, only use the prod image for this one:
images:
- name: vehicle-quotes-web
newName: localhost:32000/vehicle-quotes-prod
newTag: registryNow, we can replace any mention of localhost:32000/vehicle-quotes-dev in the dev variant, and any mention of localhost:32000/vehicle-quotes-prod in the prod variant with vehicle-quotes-web. Which is simpler.
In k8s/dev/web/deployment.yaml:
# ...
spec:
containers:
- name: vehicle-quotes-web
- image: localhost:32000/vehicle-quotes-dev:registry
+ image: vehicle-quotes-web
ports:
# ...
And in k8s/prod/web/deployment.yaml:
# ...
- name: build
- image: localhost:32000/vehicle-quotes-prod:registry
+ image: vehicle-quotes-web
workingDir: "/source"
command: ["/bin/sh"]
# ...
containers:
- name: vehicle-quotes-web
- image: localhost:32000/vehicle-quotes-prod:registry
+ image: vehicle-quotes-web
workingDir: "/app"
# ...
Once that’s all done, you should be able to kubectl apply -k k8s/dev or kubectl apply -k k8s/prod and everything should work fine. Be sure to kubectl delete before kubectl applying a different variant though, as both of them cannot coexist in the same cluster, due to many objects having the same name.
Closing thoughts
Wow! That was a good one. In this post I’ve captured all the knowledge that I wish I had when I first encountered Kubernetes. We went from knowing nothing to being able to put together a competent environment. We figured out how to install Kubernetes locally via MicroK8s, along with a few useful add-ons. We learned about the main concepts in Kubernetes like nodes, pods, images, containers, deployments, services, and persistent volumes. Most importantly, we learned how to define and create them using a declarative configuration file approach.
Then, we learned about Kustomize and how to use it to implement variants of our configurations. And we did all that by actually getting our hands dirty and, step by step, deploying a real web application and its backing database system. When all was said and done, a simple kubeclt apply -k <kustomization> was all it took to get the app up and running fully. Not bad, eh?
Useful commands
- Start up MicroK8s:
microk8s start - Shut down MicroK8s:
microk8s stop - Check MicroK8s info:
microk8s status - Start up the K8s dashboard:
microk8s dashboard-proxy - Get available pods on all namespaces:
kubectl get pods -A - Watch and follow the logs on a specific container in a pod:
kubectl logs -f <POD_NAME> <CONTAINER_NAME> - Open a shell into the default container in a pod:
kubectl exec -it <POD_NAME> -- bash - Create a K8s resource given a YAML file or directory:
kubectl apply -f <FILE_OR_DIRECTORY_NAME> - Delete a K8s resource given a YAML file or directory:
kubectl delete -f <FILE_OR_DIRECTORY_NAME> - Create K8s resources with Kustomize:
kubectl apply -k <KUSTOMIZATION_DIR> - Delete K8s resources with Kustomize:
kubectl delete -k <KUSTOMIZATION_DIR> - Build custom images for the K8s registry:
docker build . -f <DOCKERFILE> -t localhost:32000/<IMAGE_NAME>:registry - Push custom images to the K8s registry:
docker push localhost:32000/<IMAGE_NAME>:registry
Table of contents
- What is Kubernetes?
- Installing and setting up Kubernetes
- Deploying applications into a Kubernetes cluster
- Deploying our own custom application
- Deploying the database
- Deploying the web application
- Putting it all together with Kustomize
- Creating variants for production and development environments
- Closing thoughts
- Useful commands
- Table of contents
kubernetes docker dotnet postgres containers
Comments