Rails Optimization: Advanced Techniques with Solr

By Steph Skardal
July 22, 2011
Recently, I’ve been involved in optimization on a Rails 2.3 application. The application had pre-existing fragment caches throughout the views with the use of Rails sweepers. Fragment caches are used throughout the site (rather than action or page caches) because the application has a fairly complex role management system that manages edit access at the instance, class, and site level. In addition to server-side optimization with more fragment caching and query clean-up, I did significant asset-related optimization including extensive use of CSS sprites, combining JavaScript and CSS requests where ever applicable, and optimizing images with tools like pngcrush and jpegtran. Unfortunately, even with the server-side and client-side optimization, my response times were still sluggish, and the server response was the most time consuming part of the request for a certain type of page that’s expected to be hit frequently:
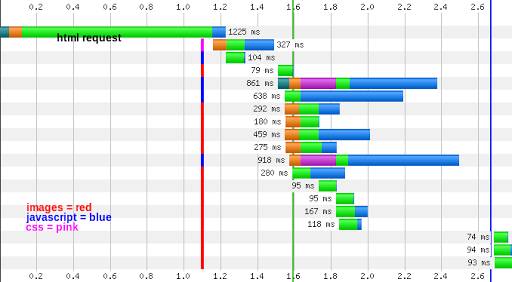
A first stop in optimization was to investigate if memcached would speed up the site, described in this article Unfortunately, that did not improve the speed much.
Next, I re-examined the debug log to see what was taking so much time. The debug log looked like this (note that table names have been changed):
Processing ThingsController#index (for 174.111.14.48 at 2011-07-12 16:32:04) [GET]
Parameters: {"action"=>"index", "controller"=>"things"}
Thing Load (441.2ms) SELECT * FROM "things" WHERE ("things"."id" IN (22,6,23,7,35,24,36,25,14,9,37,26,15,...))
Rendering template within layouts/application
Rendering things/index
Cached fragment hit: views/all-tags (1.6ms)
Rendered things/_nav_search (3.3ms)
Rendered shared/_sort (0.2ms)
Cached fragment hit: ...
Cached fragment hit: ...
Cached fragment hit: ...
Rendered ...
Rendered ...
Completed in 821ms (View: 297, DB: 443) | 200 OK [http://www.mysite.com/things]From the debug log, we can point out:
- The page loads in 821ms according to Rails, which is similar to the time reported in the waterfall shown above.
- The page is loading several cached fragments, which is good.
- The biggest time-suck of the page loading is a SELECT * FROM things …
To rule out any database slowness due to missing indexes, I examined the query speed via console (note that this application runs on PostgreSQL):
=> EXPLAIN ANALYZE SELECT * FROM "things" WHERE ("things"."id" IN (22,6,23,7,35,24,36,25,14,9,37,26,15,...));
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Seq Scan on things (cost=0.00..42.19 rows=24 width=760) (actual time=0.023..0.414 rows=25 loops=1)
Filter: (id = ANY ('{22,6,23,7,35,24,36,25,14,9,37,26,15,...}'::integer[]))
Total runtime: 0.452 ms
(3 rows)The query here is on the scale of 1000 times faster than the loading of the objects from the ThingsController. It’s well known that object instantiation in Ruby is slow. There’s not much I can do to speed up the pure performance of object instantation except possibly 1) upgrade to Ruby 1.9 or 2) try something like JRuby or Rubinius, which are both out of the scope of this project.
My next best option is to investigate using Rails low-level caching here to cache my objects pulled from the database, but there are a few challenges with this:
- The object instantiation is happening as part of a Solr (via sunspot) query, not a standard ActiveRecord lookup.
- The Solr object that’s retrieved is used for pagination with the will_paginate gem.
- Rails low-level caches can only store serializable objects. The Solr search object and WillPaginate:Collection object (a wrapper around an array of elements that can be paginated) are not serializable, so I must determine a suitable structure to store in the cache.
Controller
After troubleshooting, here’s what I came up with:
@things = Rails.cache.fetch("things-search-#{params[:page]}-#{params[:tag]}-#{params[:sort]}") do
things = Sunspot.new_search(Thing)
things.build do
if params.has_key?(:tag)
with :tag_list, CGI.unescape(params[:tag])
end
with :active, true
paginate :page => params[:page], :per_page => 25
order_by params[:sort].to_sym, :asc
end
things.execute!
t = things.hits.inject([]) { |arr, h| arr.push(h.result); arr }
{ :results => t,
:count => things.total }
end
@things = WillPaginate::Collection.create(params[:page], 25, @things[:count]) { |pager| pager.replace(@things[:results]) }Here’s how it breaks down:
- My cache key is based on the page #, tag information, and sort type, shown in the argument passed into the low-level cache build:
@things = Rails.cache.fetch("things-search-#{params[:page]}-#{params[:tag]}-#{params[:sort]}") do
###
end - All this stuff creates a Solr object, sets the Solr object details, and builds the result set. In this particular Solr object, we are pulling things that have an :active value of true, may or may not have a specific tag, limiting the result set to 25, and ordering by the :sort parameter:
things = Sunspot.new_search(Thing)
things.build do
if params.has_key?(:tag)
with :tag_list, CGI.unescape(params[:tag])
end
with :active, true
paginate :page => params[:page], :per_page => 25
order_by params[:sort].to_sym, :asc
end
things.execute!- things is my Sunspot/Solr object. I build an array of the Solr result set items and record the total number of things found. A hash that contains an array of “things” and a total count is my serializable cacheable object.
t = things.hits.inject([]) { |arr, h| arr.push(h.result); arr }
{ :results => t,
:count => things.total }- The tricky part here is building a WillPaginate::Collection object after pulling the cached data, since a WillPaginate object is also not serializable. This needs to know what the current page is, things per page, and total number of things found to correctly build the pagination links, but it doesn’t require that you have all the other “things” available:
@things = WillPaginate::Collection.create(params[:page], 25, @things[:count]) { |pager| pager.replace(@things[:results]) }View
My view contains the standard will_paginate reference:
There are <%= pluralize @things.total_entries, 'Thing' %> Total
<%= will_paginate @things %>And I pass the result set in a partial as a collection to display my listed items:
<%= render :partial => 'shared/single_thing', :collection => @things %>Sweepers
Another thing to get right here is clearing the low-level cache with Rails sweepers. I have a fairly standard Sweeper setup similar to the one described here. I utilize two ActiveRecord callbacks (after_save, before_destroy) in my sweeper to clear the cache, shown below.
class ThingSweeper < ActionController::Caching::Sweeper
observe Thing
def after_save(record)
Rails.cache.delete_matched(%r{things-search*})
# expire_fragment ...
end
def before_destroy(record)
Rails.cache.delete_matched(%r{things-search*})
# expire_fragment ...
end
endWith the changes described here (caching a serializable hash with the Solr results and total count, generating a WillPaginate:Collection object, and defining the Sweepers to clear the cache), I saw great improvements in performance. The standard “index” page request does not hit the database at all for users not logged in nor does it experience the sluggish object instantiation. My waterfall now looks like this:
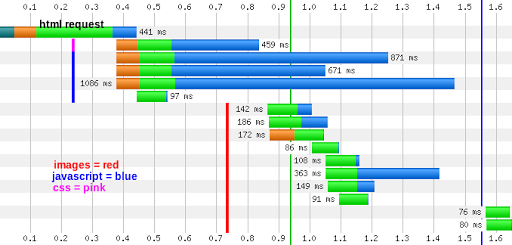
And running 100 requests at a concurrency of 1 on the system (running in production on a development server) shows the requests are averaging 165ms, which is decent. After I wrote this post, I did a even more optimization on a different page type in the application that I hope to share in a future blog post.
Note: Ideally, it would be better to cache individual objects so that I would not have expire entire search caches on every save or delete. However, I could not find methods in Solr that allows us to pull a list of ids of the result set without building the result set.
performance ruby rails solr sunspot
Comments