High Level System Analysis and Design with Domain-Driven Design

By Kevin Campusano
April 6, 2026

Photo by Zed Jensen, 2022.
Domain-Driven Design is an approach to software development that focuses on, as Eric Evans puts it, “tackling the complexity in the heart of software”. And what is in the heart of software? The business domain in which it operates. Or more specifically: a model of it, made of code. That is, the code that implements the business logic that comes into play when solving problems within the realm of a particular business activity.
DDD is not just about writing code though. It’s a whole methodology that touches on business needs, requirements gathering, organizational dynamics, high level architectural design, and lower level patterns for implementing software intensive systems.
As a result, DDD offers a treasure trove of concepts, patterns and tools that can be applied to any software project, regardless of the size and complexity.
In this series of blog posts we’re going to explore many aspects of DDD. We will be following the structure laid out by Vlad Khononov’s excellent book on the topic “Learning Domain-Driven Design: Aligning Software Architecture and Business Strategy”. So you can think of this series as a summary of that book. An abridged version that can serve as a review for anybody who has read it; but also as an entry point for people who are new to DDD.
Table of contents
- High level system analysis and design with Domain-Driven Design
Section 1. Analyzing business domains
It is a well understood notion that before writing code, we need to understand the problem we’re trying to solve. DDD is consistent with this notion and argues that developers need to, first and foremost, gain an understanding of the business that the software is being built for. To this end, DDD relies on three concepts: domains, subdomains and domain experts.
Domains and subdomains
In simple terms, the domain of a business is what it does, its area of activity. For example, Starbucks is in the business of making coffee, Ford is in the business of making automobiles, AMC is in the business of movie theaters.
Of course, analyzing a business as a single integrated whole can be unmanageable. That’s where subdomains come in. Subdomains are the different divisions within a domain. Starbuck’s domain for example, is making coffee. But there are many smaller parts that make up that business and allow it to be successful. There’s of course, the subdomain of coffee preparation. But there’s also real estate management to find and secure good locations, there’s inventory management and logistics, there’s marketing, there’s human resources, etc. All these are the subdomains that make up the overall business of Starbucks.
Depending on the business and on the project, these will vary greatly in granularity. And you can also decompose subdomains further and discover new fine-grained subdomains nested within more coarse-grained ones. The sizes and nesting levels can be very different from business to business, so it can be difficult to clearly delineate where a subdomain ends and another one starts, which activities belong to one or the other. One good rule of thumb to keep in mind is that generally, subdomains encapsulate a set of coherent, closely related use cases. That is, use cases that involve the same set of closely related actors, business entities and/or data.
And finally, we have domain experts. As the name suggests, these are the people within the organization who have intimate knowledge of the business, or certain areas of it. They are the subject matter experts. Usually they are the ones who identify the problems and come up with requirements. Developers need to rely on domain experts to gain the necessary understanding to be able to produce useful software solutions.
So, when approaching software projects, DDD suggests that developers work closely with domain experts in order to learn from them about the business domain and subdomains. After all, it is their mental models and understanding that will be modeled and implemented in code.
Types of subdomains
With the help of domain experts, developers can identify subdomains, understand their business value and how they fit within the overall business strategy. This is very important because it helps making some initial architecturally significant decisions. Namely, the general approach to solving the problems in the subdomains, how much to invest, how to organize development teams, etc. The main objective in this analysis stage is to identify the subdomains and whether they fall into one of three types: core, generic, and supporting.
Core subdomains are the activities of the business with highest value. The ones that confer differentiation in the market and a competitive advantage. They are the business’ raison d’être. For example, for Google, their search engine is a core subdomain. For Ford, their automotive engineering area would be a core subdomain. Core subdomains are generally the most complex parts of the business. They are constantly evolving and improving, and the company is compelled to invest heavily in them.
Generic subdomains are also very complex. However, they are not business differentiators. Instead, these are the areas of the business that all organizations handle in the same way. Think accounting, a ticketing system, an online storefront. There’s no pressure to innovate in these areas, so the solutions are very stable and evolution is slow.
Supporting subdomains on the other hand, do not provide any competitive advantage, nor are they very complex. They are however, necessary because they support the core business activities, and are fairly unique. The solutions to problems in these areas usually take the form of CRUD or ETL oriented activities. Imagine for example populating a data warehouse, translating transactional business data into a format appropriate for analytics and business intelligence in a manufacturing corporation. Or maybe the digitization and storage of a registry of court documents for a law firm. These are behind the scenes activities that support the organizations’ main businesses, but their business logic complexity is not high, and they don’t really represent big selling points for the company.
It’s worth noting as well, that there may be subdomains where software solutions are not appropriate, even if they are highly complex core subdomains. They are still part of the business so it’s worth identifying and considering for high level architectural design decisions. If anything, to know what parts of the business the planned software system should and should not focus on. You could have a restaurant, for example, who prides itself in having the best desserts in the city. For their business, the recipe development activities constitute a core subdomain. This is dependent on the art and craftsmanship of the chefs. Not an area in which software solutions could help a whole lot.
It’s also worth noting that, just as organizations’ business strategies are dynamic, so too can be their subdomain distribution. Today’s generic subdomain can be tomorrow’s core subdomain, and so on. For example, imagine a big retail store chain that, up until now, managed its inventory in an industry standard way. But it has grown so much that the standard way of doing things has become a bottleneck for them. So they design a new procedure for highly efficient inventory management, and that gives them an edge against competitors. Inventory management started as a generic subdomain for them, but due to an ever evolving business strategy, it became a core subdomain.
The knowledge of subdomain types can also help the analysis when dividing the business and discovering subdomains. If you find yourself recursively finding more and more fine-grained subdomains from already identified ones, a good time to stop recursing is when you find that a generic or supporting subdomain, when broken down, reveals only new finer-grained generic or supporting subdomains. The reasoning for this is simple: this analysis activity is most valuable when trying to identify core subdomains. When there are no more core subdomains to be found within a particular area of the business, then it’s probably not worth it to keep digging deeper.
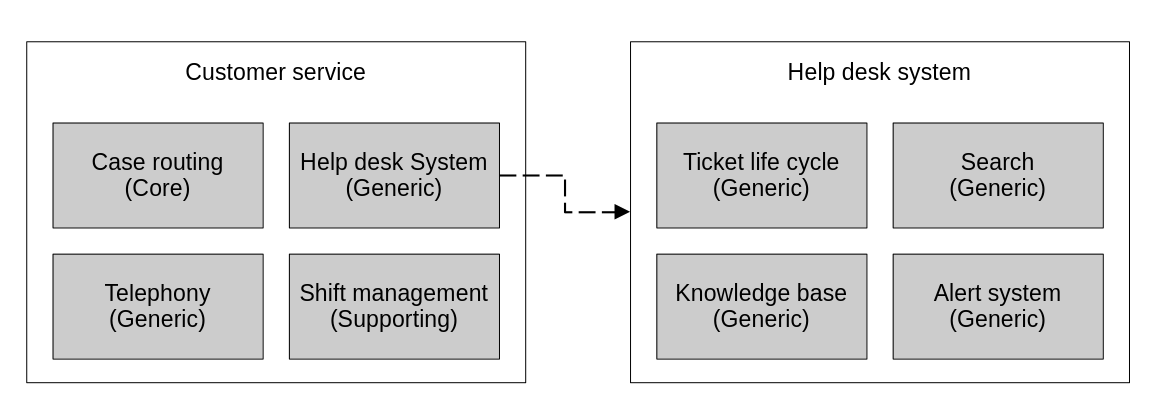
Here we have an example of a hypothetical help desk system subdomain, part of a customer service subdomain, being decomposed and revealing that it only contains generic subdomains.
In summary, these are the main characteristics of the three types of subdomains:
- Core subdomains have high complexity, provide competitive advantage, and change and evolve frequently.
- Generic subdomains have high complexity, do not provide competitive advantage and change overtime, although at a slower pace than core subdomains.
- Support subdomains have low complexity, do not provide competitive advantage and are the slowest to change.
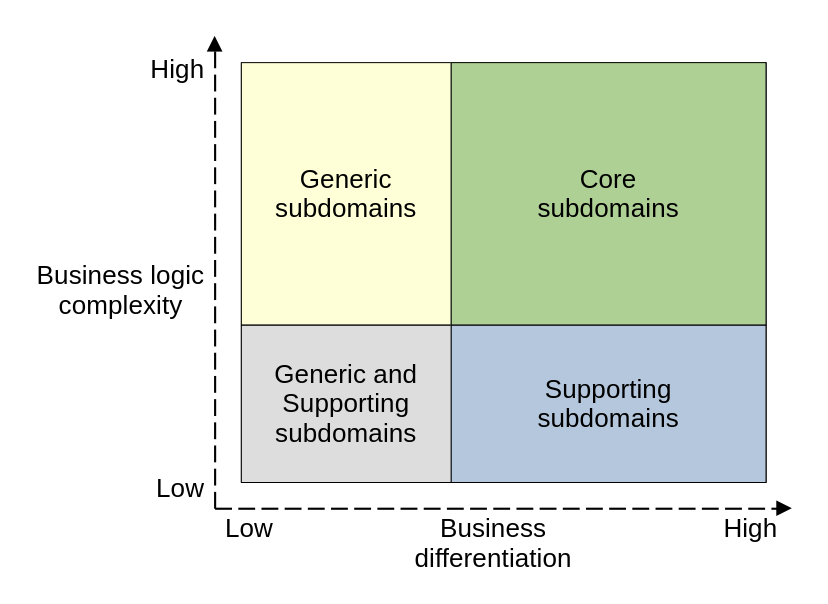
This is where each type of subdomain fall when considering their business logic complexity and business differentiation.
Using subdomains to make strategic decisions
Like I’ve already alluded to, armed with this knowledge, DDD practitioners are ready to start making some higher level architectural decisions. Depending on the type of subdomain that a problem belongs to, DDD has specific prescriptions on how to handle the implementation of software solutions for them.
When working on core subdomains, that’s where we want to make the biggest investments. We deploy the most advanced engineering tools, patterns and practices. This is to make sure that the software is efficient and high quality, and also easy to maintain and evolve. This is necessary because core subdomains have to evolve rapidly by nature, if the business is to maintain competitive advantage. Software solutions that operate within the context of core subdomains have to be implemented by high skill and high trust teams. Either in-house, or via trusted development partners, working hand in hand with domain experts.
Problems in generic subdomains, by nature of their business logic being very complex but also very common, are likely to have already been solved. For these types of problems, DDD recommends against implementing custom software, and instead buying and/or adopting tried and true, industry standard, off-the-shelf solutions. Their implementation and integration can be outsourced or handled by less specialized or skilled teams. The change management of these solutions is simple, as they get delivered generally via patches and updates.
For support subdomains, whose business logic is generally simple but uncommon, it is less likely that off-the-shelf solutions would be available. So software addressing problems in these subdomains will most likely have to be implemented as custom solutions. Due to their low complexity though, they can be easily outsourced, or handled by more junior team members. They can also be handled with RAD, low-to-no-code technologies, since often times they are little more than ETL and pure CRUD applications.
Here’s a table to summarizes the differences between the types of subdomains:
| Type of subdomain | Core | Generic | Supporting |
|---|---|---|---|
| Competitive advantage | Yes | No | No |
| Complexity | High | High | Low |
| Rate of change | High | Medium | Low |
| Implementation | Custom development | Buy/adopt off-the-shelf | Custom development |
| Team composition | In-house/partners | Can outsource | Can outsource |
| Skill level | High | High/regular | Low |
| Investment | High | Medium | Low |
| Problems | Interesting | Solved | Simple |
Section 2. Discovering domain knowledge
After identifying the business domain and categorizing the various subdomains that compose it, we have a bird’s-eye view of the business. This is good enough to get started and make high level architectural decisions of potential software solutions to problems within these domains. To actually build the software though, we need much more than that. In order to gain a thorough understanding of the business logic, and be able to eventually model and implement it in code, DDD proposes the ubiquitous language as a tool.
The ubiquitous language
The ubiquitous language is DDD’s tool for knowledge sharing, effective communication and software modeling. In simple terms, the ubiquitous language is the language of the business. It’s the language that domain experts use on a day to day basis to talk and reason about the business.
For a software project to be successful, it’s essential that engineers and stakeholders understand each other. They have to be aligned when it comes to the meanings of the core concepts of the business domain. That’s why it’s so important that everybody uses the ubiquitous language for all project related communications, requirements, documentation, face to face discussions, and even code itself. It all needs to share the same language.
Engineers will need to interact with domain experts in order to learn about the business domain and its rules. They need to acquire the necessary knowledge that allows them to implement these rules in the software. During these interactions, they converse using the ubiquitous language. However, the knowledge transfer is not always strictly unidirectional. Yes, engineers have to learn from the domain experts. But also, through conversations and questioning, engineers can help domain experts deepen and flesh out their own understanding about their domains.
A classic example of this is when domain experts focus too much on the “happy paths” of given business processes. Then, through discussions with developers, on account of the inherent precision that software demands, they are forced to consider more edge cases, better specify ambiguous terms and fill out gaps in their understanding.
This deepening of knowledge feeds back into the ubiquitous language and improves it. Making it more insightful and more precise. This means that, throughout the life cycle of a project, the ubiquitous language should keep evolving, expanding and refining. This allows it to continuously improve as an effective model of the business domain, for the problem that it’s trying to solve. Indeed, just like code is a model of the business domain, so too is the ubiquitous language.
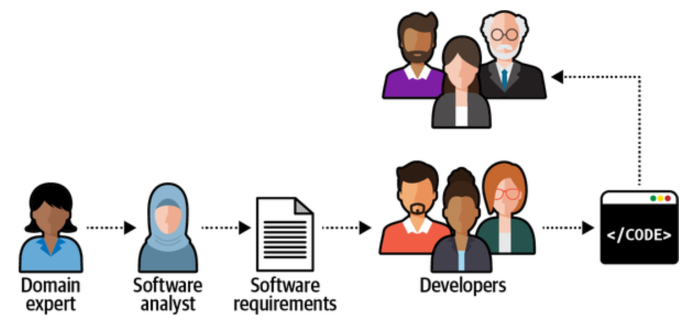
A classic pitfall in software projects is a manner of communication and knowledge sharing where developers are various steps removed from the domain experts. Consistent use of the ubiquitous language addresses this.
The ubiquitous language as a model of the domain
Through consistent use of the ubiquitous language, developers are able to obtain a deeper understanding of the domain, the problems we’re trying to solve, the reasoning behind the requirements and the mental model of the domain experts. This allows the construction of effective software solutions, with deep business insight, that go beyond simply translating requirements into code. If the implementation models the business domain effectively, there is potential for it to evolve with the business and better adapt as requirements change; and we reduce the risk of missing edge cases that may not be obvious to domain experts.
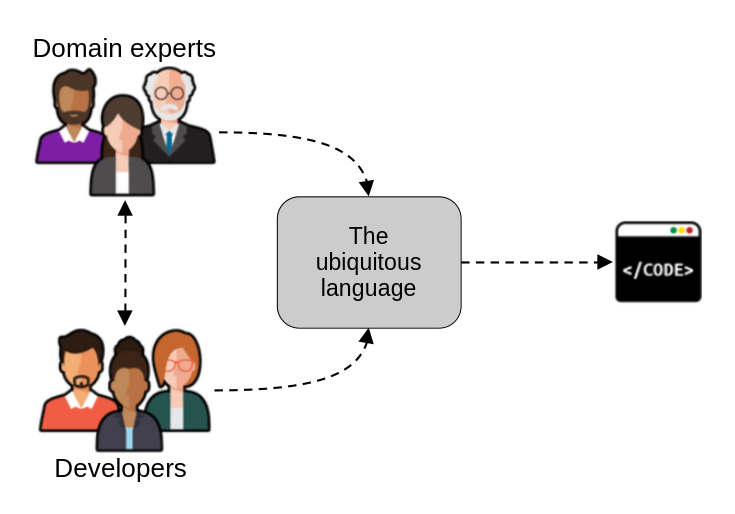 Under DDD, developers and domain experts develop the ubiquitous language, which then informs the implementation.
Under DDD, developers and domain experts develop the ubiquitous language, which then informs the implementation.
Effectively, when we build a ubiquitous language, we’re building a model of the domain. A model that reflects the relevant business entities, their behavior, and relationships. A model that will be eventually implemented into code, but also a model that needs to be understood by all stakeholders, regardless of their technical level. So it needs to be precise and rigorous, but also understandable. As such, in order to be useful, the ubiquitous language needs to respect certain restrictions:
- It must not include technical jargon like programming languages, constructs or frameworks; nor mention specific system structures like database tables, servers or programs. It is the language of the business and it needs to be understandable by non technical folks.
- It must avoid using the same term for different concepts. In conversation with humans, a lot of the meaning is extracted from the context. In software, not so much. Just like you can’t have two classes with the same name within the same namespace, the ubiquitous language cannot allow such ambiguities.
- It should also avoid using different words for the same concept. The classic example for this is words like users, accounts, customers, visitors. They all refer to closely related concepts which might actually have differences. The problem with these overlapping terms is that those differences are obscured by the notion of them “being the same” and being used interchangeably. For usage within the ubiquitous language, it’s best to be precise and clearly delineate terms and definitions. Eliminate what’s redundant, be strict with definitions.
- It should avoid including extraneous details. Just like code needs to include only what’s needed to solve the problem at hand and nothing else (in order to avoid accidental complexity); the ubiquitous language must not be polluted with details from outside of the area of business activity that it represents. That can create confusion and unnecessary cognitive load.
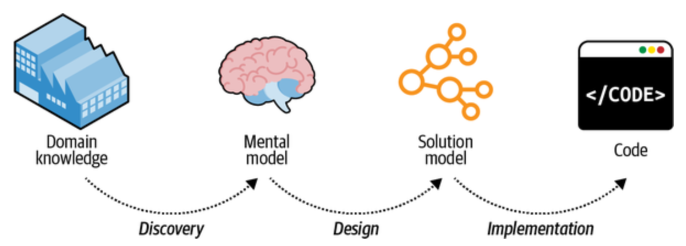 The ubiquitous language represents a unified model of the domain. This is in contrast to a more traditional process where domain knowledge gets “translated” multiple times before turning into code.
The ubiquitous language represents a unified model of the domain. This is in contrast to a more traditional process where domain knowledge gets “translated” multiple times before turning into code.
Tools for capturing the ubiquitous language
The Agile Manifesto declares: “Individuals and interactions over processes and tools”. And of course, when it comes to the ubiquitous language, direct interaction and conversations between engineers, domain experts and other stakeholders reigns supreme. That’s when it can be most useful. It can also be useful, however, to capture the ubiquitous language in documentation and even in runnable form.
A glossary of terms is a great asset for keeping a ubiquitous language. A wiki is a good place to put this. Definitions for key concepts in the business like entities, processes and rules can be captured here. The only caveat is that documentation is static by nature, while the ubiquitous language is continually evolving. So, great care needs to be taken to keep the wiki updated at all times to reflect the latest and most complete understanding of the domain. This should not be relegated to or gate-keeped by only certain people; it should be a team effort where everyone contributes.
An automated acceptance tests suite, written using Behavior Driven Development frameworks, like Cucumber, is also a great way of capturing the ubiquitous language. The advantage of these tests is that they are written in plain human-readable language, not code. And while it may be far fetched to think that non technical domain experts would be capable of writing and maintaining such tests, they certainly can read and understand them, which is a great boon. These tests speak the language they understand: the language of the business.
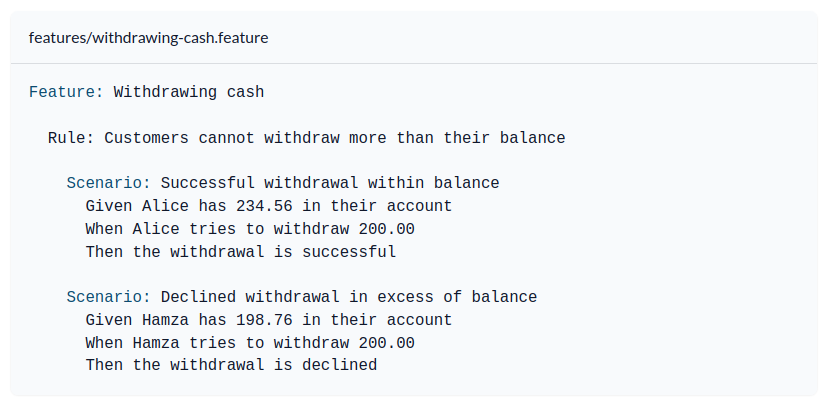 This is what Cucumber tests look like.
This is what Cucumber tests look like.
By nature of being executable and tied closely to the implementation code, there is less chance that they become out of date. This can happen more easily with static documentation written in a wiki. The disadvantage is that they require much more effort. But for the right kind of project, one where business logic is very complex or the scope is very wide, they can be very well worth the cost.
Section 3. Managing domain complexity
We can attempt to model an entire business domain with one big ubiquitous language, but sometimes that’s impossible. Especially so for businesses of a certain size, you will inevitably find inconsistencies and conflicts between the mental models of different domain experts. The simplest example of this scenario is when different experts from different areas of the organization have the same word to describe different concepts. Or when they look at the same business entity with different levels of detail.
When the different mental models are valid, and these inconsistencies are legitimate and cannot be reconciled, the solution is to follow the divide and conquer principle and decompose the language into separate ones, each one working within its own bounded context.
Simply put, a bounded context is the context within which a ubiquitous language, and the model it represents, operate, have meaning and are useful. Sure enough, just like a domain can be divided into subdomains, a ubiquitous language can be decomposed into smaller languages, each with its own context, to model different parts of the business. While we can attempt to capture an entire business domain with a single model, this is not advisable in the case of complex systems. It’s better to split up the model into smaller, more precise ones, tailored to work on specific problem domains.
Reasons for creating bounded contexts
Like mentioned before, different domain experts having conflicting mental models is a clear indication that a division in the model needs to happen. However, that only tells us half of the story. There are other indicators that point to when and where further division should happen:
First of all, there is of course, size. Size by itself is not a deciding factor, but it is something to consider and balance. Fewer, bigger models can help keep the overall environment simpler, but if they become too big they can become unmanageable and prone to corruption. A higher number of smaller models keep cognitive load low, but you run the risk of exploding integration and management complexity. The better principles to keep in mind here are coupling and cohesion. Beware of separating closely tied use cases, that deal with similar actors, entities and data.
System-level nonfunctional requirements also play a role in dividing a model into separate bounded contexts. For example, you might need to decouple the life cycle of several software components. Have them be developed, evolved, versioned and deployed independently. You might also need them to scale separately. You might even need to use completely different technology stacks, whatever is appropriate for the task at hand. This means that bounded contexts generally get implemented as individual services and/or applications. That is, as individual runtime components.
The organization’s composition also plays a role when designing bounded contexts. The general rule is that a given ubiquitous language, the model it represents and the bounded context is lives in, must be owned by a single team. In software, high ownership, cohesion and consistency are desirable traits. Having a single team own and maintain a particular component foments these. Single ownership also helps reduce communication overhead, and prevents people from stepping on one another’s toes. Of course, a single team can own multiple bounded contexts, what cannot happen is one bounded context being owned by multiple teams.
Indeed, in bounded contexts, we have the tools we need to make strategic decisions related to the decomposition of software systems into architecturally significant components or modules. With bounded contexts, we are able to specify the physical and ownership boundaries of these components.
Bounded contexts vs subdomains
Bounded contexts and subdomains are closely related concepts, but there’s one key distinction: subdomains are discovered, while bounded contexts are designed. Subdomains are useful because they help us understand the business strategy. Splitting the business domain into smaller problem domains is useful because it can break down a complex whole into smaller and more manageable parts.
Depending on the situation, it is certainly possible to end up with a set of bounded contexts that align one-to-one with the business subdomains. However, this is not mandatory. We can develop a solution with a single bounded context that spans multiple subdomains; the same way that we can decompose the problem into many bounded contexts, some of which operate within the same particular subdomain.
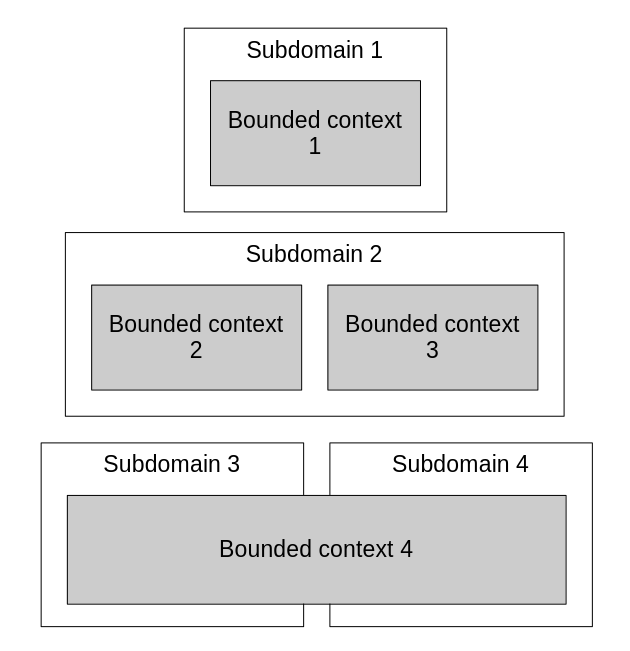
Bounded contexts are closely related to subdomains, but aren’t tied to them. They are flexible and can be organized in many ways.
Each bounded context becomes a separate major architectural component. That is, a (micro) service, a project, an application. When we have a component that spans multiple subdomains, programming language organizational structures like namespaces or modules can be used to logically separate the subdomains within.
Section 4. Integrating bounded contexts
For a system to function, its components need to interact with each other. So, once we have decomposed the problem domain into separate bounded contexts, we need to decide their relationship and integration strategies. This need for interaction between them implies that there are touch points between bounded contexts. We call them contracts.
These contracts are necessary because each bounded context contains its own version of the world. That is, its own model and ubiquitous language. In order to integrate, some level of translation needs to happen. They need to be adapted to one another. The contracts define these adaptations.
Domain-Driven Design offers various patterns that are useful for defining contracts between bounded contexts. The decision to use one pattern vs the other depends greatly on the nature of the teams tackling the project. Depending on the teams’ relationship, we can put the patterns in one of three categories: cooperation, customer-supplier, and separate ways.
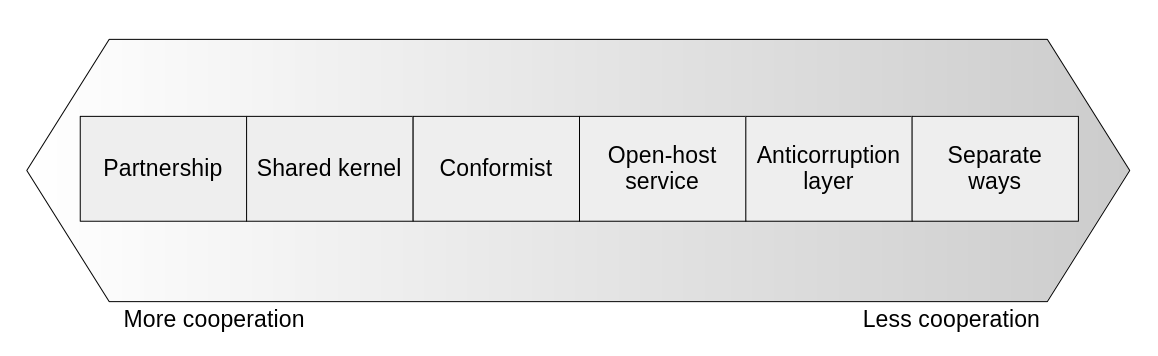
Integration patterns are determined mainly by the level of cooperation between the teams that own the interacting bounded contexts.
Cooperation patterns
When the components that need to interact are owned by teams which are in close communication, work well together, and whose goals are aligned, cooperation patterns can be applied.
If the teams meet these criteria, a partnership model can be implemented. This is where the integration is managed in an ad-hoc manner. Both teams work together to define the API through which their components interact and that’s that. Whenever changes happen on either side, the other team learns about it quickly and adjusts their code right away. Continuous integration is a great tool here, as breakages are immediately apparent, closing down the feedback loop.
Sometimes, when different bounded contexts need to implement the same functionality, it makes more sense to develop this functionality once and package it as a reusable library, or a sub-module within a shared repository. This is what DDD calls a shared kernel. A shared kernel is effectively a bounded context of its own, one that is statically linked to other components and implements the logic that others depend on.
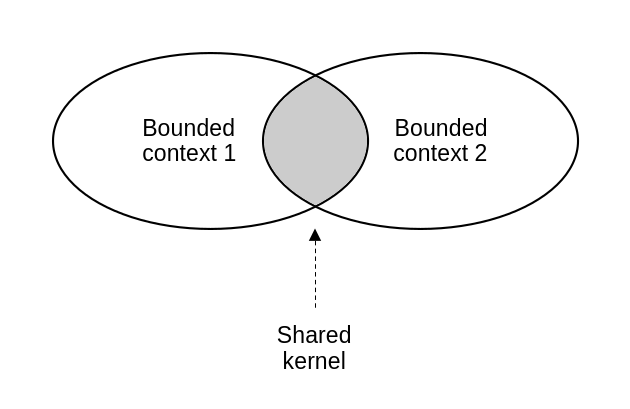
A shared kernel is its own bounded context, but also “belongs” to multiple other bounded contexts.
The shared kernel integration pattern needs to be used carefully though, as it creates tight coupling between the components that use it. If the involved bounded contexts are owned by different teams, then this shared kernel that emerges violates the DDD principle of bounded contexts having single-team ownership. This is something to watch out for, as bad team synergy can produce problems during development and maintenance.
When using a shared kernel, the quality of the communication and the coordination between the teams has to strike the right balance: when they aren’t strong enough to support a partnership model, but not so weak that the shared kernel would become more trouble than it’s worth.
The alternative to a shared kernel is the duplication of the logic across multiple components. When deciding whether to apply this pattern, the costs of duplication vs coordination need to be considered. That is, the cost of implementing the same logic within multiple components and its subsequent changes, vs the cost of changes in the shared kernel propagating into dependent components and coordinating with the owners of each. When it is cheaper to just duplicate the logic, shared kernel should not be applied.
This means that complicated models that change frequently, like those of core subdomains, are good candidates for shared kernel. Shared kernels allow complexity to be encapsulated and exposed through stable contracts. This means that frequent changes are easier to contain. Frequent changes in logic that’s highly complex and also repeated in multiple places, quickly becomes much more expensive to maintain.
Another good scenario for applying a shared kernel is when refactoring a legacy monolithic system into more separated modules. The legacy system can become the shared kernel during the time that modules are being extracted from it but not yet fully decoupled.
Customer-supplier patterns
Customer-supplier patterns establish a relationship between components where one (the provider, who is “upstream”), provides a service to another (the consumer, who is “downstream”). These types of patterns emerge when the teams who own the involved bounded contexts are not in close collaboration and have their own independent goals.
One form of customer-supplier integration is the conformist pattern. This happens when the supplier defines the integration contract/API, using its own language, concepts and model, and the consumer accepts it. This can happen when the upstream service has a well established or industry-standard model. Or maybe the model is “good enough” for the consumer to interact with directly. Organizational politics may also be a reason for this type of integration, where there is an imbalance of power favoring the supplier’s team, and they get to impose their model or can’t be bothered to adapt it.
Sometimes, the consumer won’t accept the supplier’s model. In that case, an anticorruption layer can be created. An anticorruption layer is implemented by the consumer and translates the supplier’s model into its own. This allows the consumer to use the supplier’s service without polluting its model with extraneous concepts.
Anticorruption layers can be good solutions for the following scenarios:
- When the consumer represents a core subdomain. The consumer is solving hard and interesting problems, so it’s best to protect its model with the ACL.
- When the supplier’s model is messy and inconvenient. The ACL can protect the consumer’s model from having to contend with a mess of extraneous concepts.
- When the supplier’s contract changes frequently. The ACL can protect the consumer from those changes, encapsulating them, allowing it to be less volatile.
A third pattern represents an anticorruption layer of sorts, only built on the supplier’s side. DDD calls this the open-host service pattern. Here, the upstream service comes up with a new language, separate from its own, tailored to its consumers’ convenience, and exposes that as its contract. This public protocol is called a “published language”.
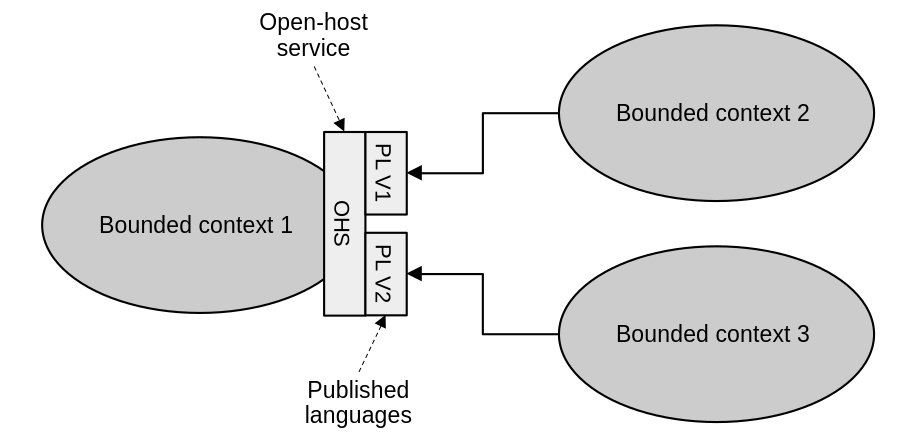
An open-host service provides a protocol for consumers to interact with. It can also support multiple versions of this protocol simultaneously.
An open-host service applies to similar scenarios as an anticorruption layer. Decoupling a service’s internal model from its integration model frees it up for continuous evolution without fear of breaking its consumers. Another advantage of this is that multiple versions of the published language can be exposed, affording clients options on what to support and gradually migrate if they so choose.
Separate ways
Sometimes, the right decision is to not integrate at all. I alluded to this outcome back when discussing the pitfalls of the shared kernel. Sometimes duplication, in spite of how bad it smells, may be the most cost effective solution to a given situation. So the teams go their separate ways.
This can happen when the involved teams cannot collaborate effectively for whatever reason. It could be due to geographical, timezone, or organizational issues.
This can also be a good solution when the repeated logic belongs in a generic subdomain, and it’s easy to integrate. For example consider a logging framework. Exposing that kind of functionality in a service for others to consume, in most cases would be much more trouble than just including some third party library or package.
It may also be that the models being integrated are just so different that they are fundamentally incompatible. It may be cost-prohibitive for collaboration or customer-supplier patterns to be applied; and duplication again, is cheaper.
Going separate ways can be dangerous when we’re talking about core subdomains though. So we have to tread carefully in those scenarios. Remember that models that represent core subdomain should be implemented in the most effective and efficient ways, with few shortcuts and minimized technical debt.
The context map
The context map can be a useful tool for high level design as it plots all the major bounded contexts (i.e. modules, components, subsystems) that we’ve designed and their interaction patterns.
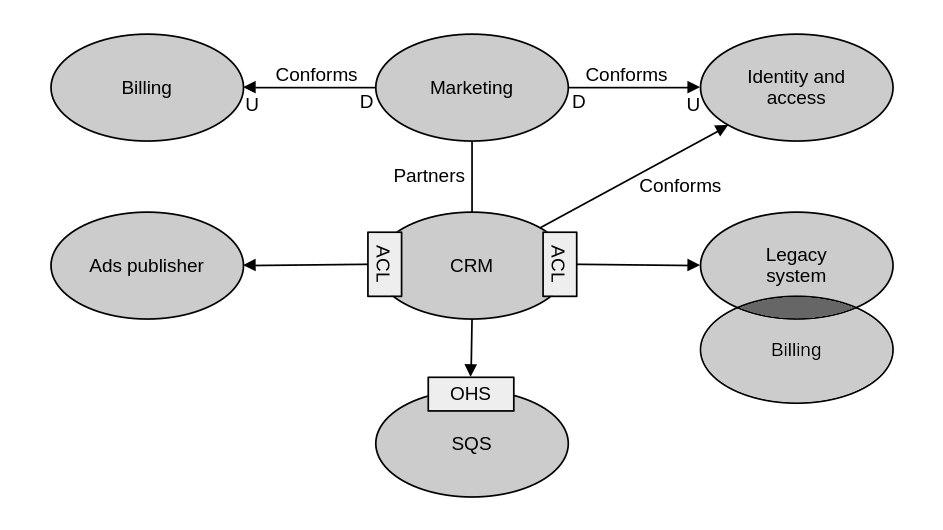
Here’s a context map which captures the various bounded contexts that compose a big system and their interactions. The arrows point to the upstream component in the relationship. “ACL” denotes an anticorruption layer and “OHS” represents an open-host service.
Of course, they can also offer valuable insight into organizational dynamics, as team composition and relationships with others are intrinsic parts of the discussion when talking about bounded contexts. For example, it can show teams that prefer to collaborate closely or at a healthy distance. I can also show problematic components, which are surrounded by anticorruption layers or have had their ties completely cut via a separate ways approach.
As with any document, they run the risk of becoming stale as the system evolves. So it should be a team-wide responsibility to keep it up to date. Each team taking care of their own components and their integration points.
The DDD high level design concept map
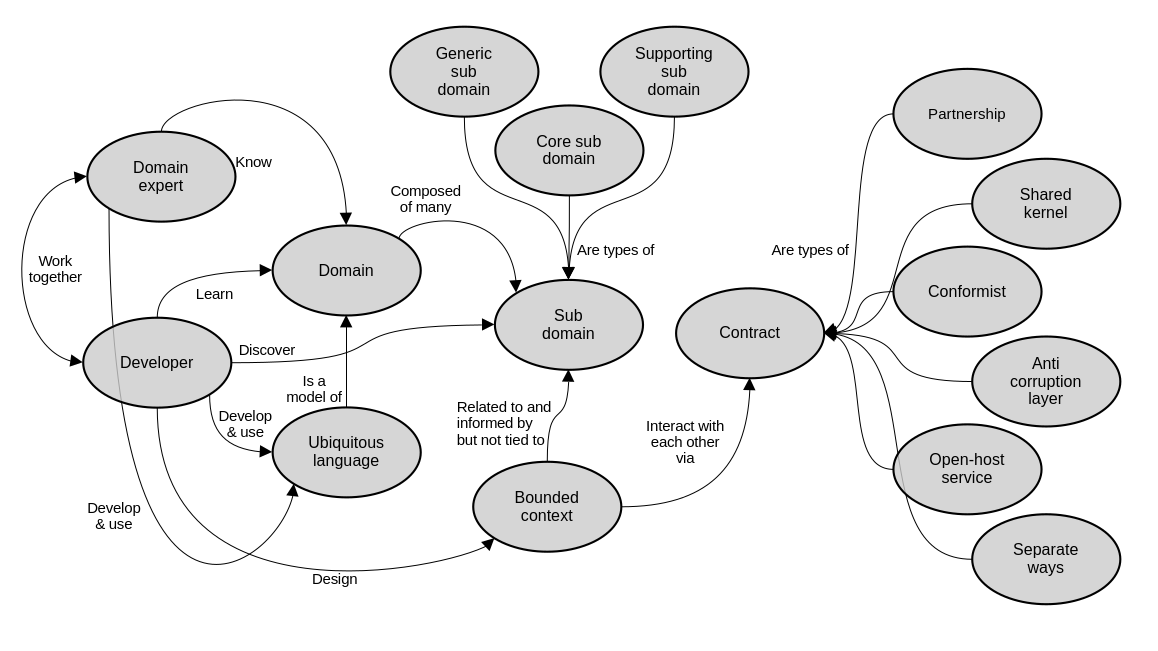
These are the main concepts that we’ve explored so far, and how they relate to each other.
software architecture design books
Comments