Web Development, Big Data and DevOps—OSI Days 2014, India

By Selvakumar Arumugam
January 12, 2015
This is the second part of an article about the conference Open Source India, 2014 was held at Bengaluru, India. The first part is available here. The second day of the conference started with the same excitement level. I plan to attend talks covering Web, Big Data, Logs monitoring and Docker.
Web Personalisation
Jacob Singh started the first talk session with a wonderful presentation along with real-world cases which explained the importance of personalisation in the web. It extended to content personalisation for users and A/B testing (comparing two versions of a webpage to see which one performs better). The demo used the Acquia Lift personalisation module for the Drupal CMS which is developed by his team.
MEAN Stack
Sateesh Kavuri of Yodlee spoke about the MEAN stack which is a web development stack equivalent to popular LAMP stack. MEAN provides a flexible compatibility to web and mobile applications. He explained the architecture of MEAN stack.
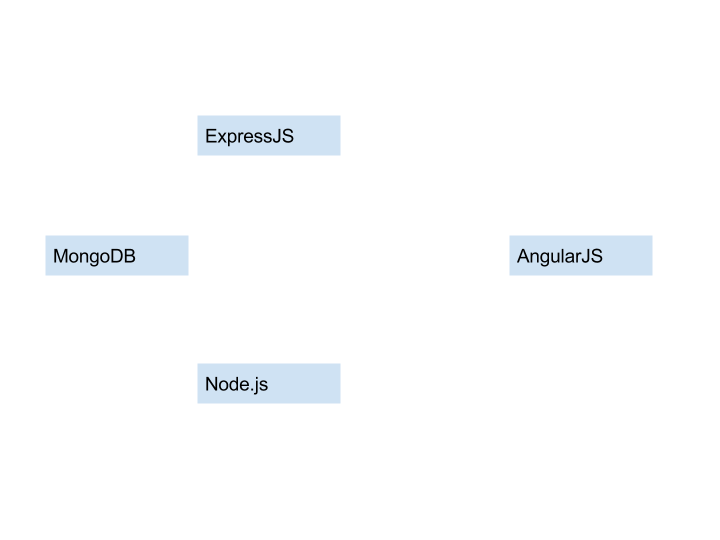
He also provided an overview of each component involved in MEAN Stack.
MongoDB — NoSQL database with dynamic schema, in-built aggregation, mapreduce, JSON style document, auto-sharding, extensive query mechanism and high availability.
ExpressJS — A node.js framework to provide features to web and mobile applications.
AngularJS — seamless bi-directional model with extensive features like services and directives.
Node.js — A server side JavaScript framework with event based programming and single threaded (non blocking I/O with help of request queue).
Sails.js — MEAN Stack provisioner to develop applications quickly.
Finally he demonstrated a MEAN Stack demo application provisioned with help of Sails.js.
Moving fast with high performance Hack and PHP
Dushyant Min spoke about the way Facebook optimised the PHP code base to deliver better performance when they supposed to handle a massive growth of users. Earlier there were compilers HipHop for PHP (HPHPc) or HPHPi (developer mode) to convert the php code to C++ binary and executed to provide the response. After sometime, Facebook developed a new compilation engine called HipHop Virtual Machine which uses Just-In-Time (JIT) compilation approach and converts the code to HipHop ByteCode (HHBC). Both Facebook’s production and development environment code runs over HHVM.
Facebook also created a new language called Hack which is very similar to PHP which added static typing and many other new features. The main reason for Hack is to get the fastest development cycle to add new features and release frequent versions. Hack also uses the HHVM engine.
HHVM engine supports both PHP and Hack, also it provides better performance compare to Zend engine. So Zend Engine can be replaced with HHVM without any issues in the existing PHP applications to get much better performance. It is simple as below:
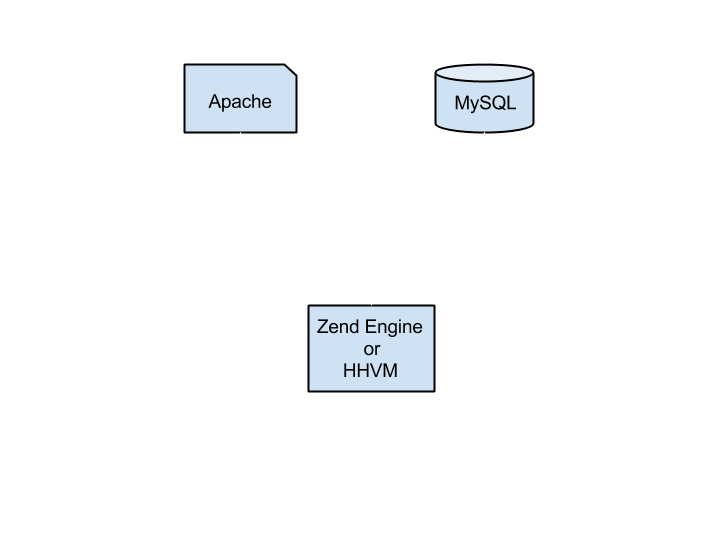
Also PHP code can be migrated to Hack by changing the <?php tag to <?hh and there are some converters (hackficator) available for code migration. Both PHP and Hack provide almost the same performance on the HHVM engine, but Hack has some additional developer-focussed features.
Application Monitoring and Log Management
Abhishek Dwivedi spoke about a stack to process the logs with various formats, myriad timestamp and no context. He explains a stack of tools to process the logs, store and visualize in a elegant way.
ELK Stack = Elasticsearch, LogStash, Kibana. The architecture and the data flow of ELK stack is stated below:
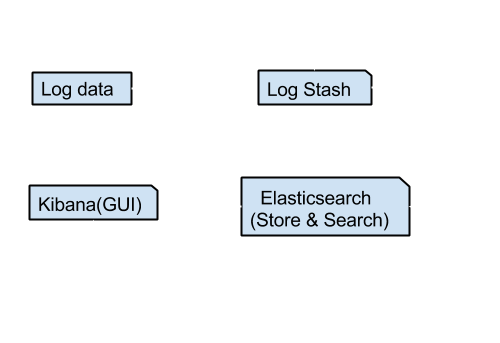
Elasticsearch — Open source full text search and analytics engine
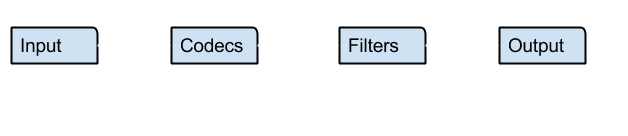
Log Stash — Open source tool for managing events and logs which has following steps to process the logs
Kibana — seamlessly works with Elasticsearch and provides elegant user interface with various types of graphs
Apache Spark
Prajod and Namitha presented the overview of Apache Spark which is a real time data processing system. It can work on top of Hadoop Distributed FileSystem (HDFS). Apache Spark performs 100x faster in memory and 10x faster in disk compare to Hadoop. It fits with Streaming and Interactive scale of Big Data processing.
Apache Spark has certain features in processing the data to deliver the promising performance:
- Multistep Directed Acyclic Graph
- Cached Intermediate Data
- Resilient Distributed Data
- Spark Streaming — Adjust batch time to get the near real time data process
- Implementation of Lambda architecture
- Graphx and Mlib libraries play an important role
Online Data Processing in Twitter
Lohit Vijayarenu from Twitter spoke about the technologies used at Twitter and their contributions to Open Source. Also he explained the higher level architecture and technologies used in the Twitter microblogging social media platform.
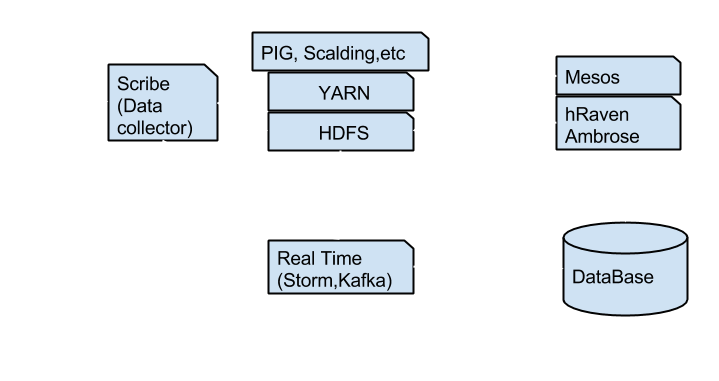
The Twitter front end is the main data input for the system. The Facebook-developed Scribe log servers gather the data from the Twitter front end application and transfers the data to both batch and real time Big Data processing systems. Storm is a real time data processing system which takes care of the happening events at the site. Hadoop is a batch processing system which runs over historical data and generates result data to perform analysis. Several high level abstraction tools like PIG are used write the MR jobs. Along with these frameworks and tools at the high level architecture, there are plenty of Open Source tools used in Twitter. Lohit also strongly mentioned that in addition to using Open Source tools, Twitter contributes back to Open Source.
Docker
Neependra Khare from Red Hat given a talk and demo on Docker which was very interactive session. The gist of Docker is to build, ship and run any application anywhere. It provides good performance and resource utilization compared to the traditional VM model. It uses the Linux core feature called containerization. The container storage is ephemeral, so the important data can be stored in persistent external storage volumes. Slides can be found here.
angular conference docker containers mongodb nodejs php cms
Comments