List Google Pages Indexed for SEO: Two Step How To

By Steph Skardal
December 11, 2009
Whenever I work on SEO reports, I often start by looking at pages indexed in Google. I just want a simple list of the URLs indexed by the GOOG. I usually use this list to get a general idea of navigation, look for duplicate content, and examine initial counts of different types of pages indexed.
Yesterday, I finally got around to figuring out a command line solution to generate this desired indexation list. Here’s how to use the command line using http://www.endpoint.com/ as an example:
Step 1
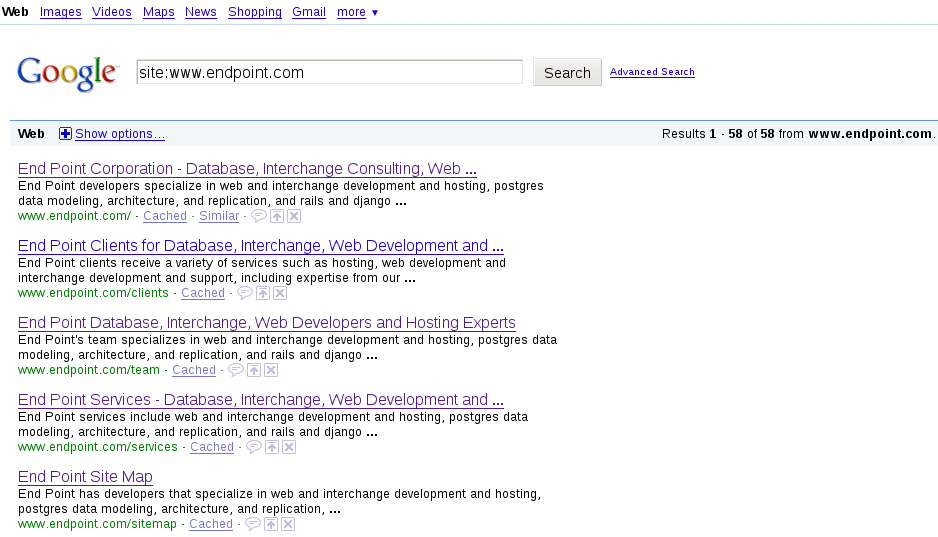
Grab the search results using the “site:” operator and make sure you run an advanced search that shows 100 results. The URL will look something like: https://www.google.com/search?num=100&as_sitesearch=www.endpoint.com
But it will likely have lots of other query parameters of lesser importance [to us]. Save the search results page as search.html.
Step 2
Run the following command:
sed 's/<h3 class="r">/\n/g; s/class="l"/LINK\n/g' search.html | grep LINK | sed 's/<a href="\|" LINK//g'There you have it. Interestingly enough, the order of pages can be an indicator of which pages rank well. Typically, pages with higher PageRank will be near the top, although I have seen some strange exceptions. End Point’s indexed pages:
http://www.endpoint.com/
http://www.endpoint.com/clients
http://www.endpoint.com/team
http://www.endpoint.com/services
http://www.endpoint.com/sitemap
http://www.endpoint.com/contact
http://www.endpoint.com/team/selena_deckelmann
http://www.endpoint.com/team/josh_tolley
http://www.endpoint.com/team/steph_powell
http://www.endpoint.com/team/ethan_rowe
http://www.endpoint.com/team/greg_sabino_mullane
http://www.endpoint.com/team/mark_johnson
http://www.endpoint.com/team/jeff_boes
http://www.endpoint.com/team/ron_phipps
http://www.endpoint.com/team/david_christensen
http://www.endpoint.com/team/carl_bailey
http://www.endpoint.com/services/spree
...For the site I examined yesterday, I saved the pages as one.html, two.html, three.html and four.html because the site had about 350 results. I wrote a simple script to concatenate all the results:
#!/bin/bash
rm results.txt
for ARG in $*
do
sed 's/<h3 class="r">/\n/g; s/class="l"/LINK\n/g' $ARG | grep LINK | sed 's/<a href="\|" LINK//g' >> results.txt
doneAnd I called the script above with:
./list_google_index.sh one.html two.html three.html four.htmlThis solution isn’t scalable nor is it particularly elegant. But it’s good for a quick and dirty list of pages indexed by the GOOG. I’ve worked with the WWW::Google::PageRank module before and there are restrictions on API request limits and frequency, so I would highly advise against writing a script that makes requests to Google repeatedly. I’ll likely use the script described above for sites with less than 1000 pages indexed. There may be other solutions out there to list pages indexed by Google, but as I said, I was going for a quick and dirty approach.
Remember not to get eaten by the Google Monster
Comments