How to Migrate from Microsoft SQL Server to PostgreSQL

By Selvakumar Arumugam
January 23, 2019
One of our clients had a Java-based application stack on Linux that connected to a pretty old version of SQL Server on Windows. We wanted to migrate the entire system to a more consistent unified stack that developers are efficient with, and that is current so it receives regular updates.
We decided to migrate the database from SQL Server to PostgreSQL on Linux because porting the database, while not entirely quick or simple, was still much simpler than porting the app to .NET/C# would have been. Rewriting the application would have taken far longer, been much riskier to the business, and cost a lot more.
I experimented with a few approaches to the migration and decided to go with the process of schema migration and then the data migration approach which is referred to on the Postgres wiki. Let’s walk through the process of migration step by step.
Schema Migration
A schema of the SQL Server database tables and views needs to be exported to perform schema conversion. The following steps will show you how to export the schema.
Export SQL Server Database Schema
In SQL Management Studio, right click on the database and select Tasks → Generate Scripts.
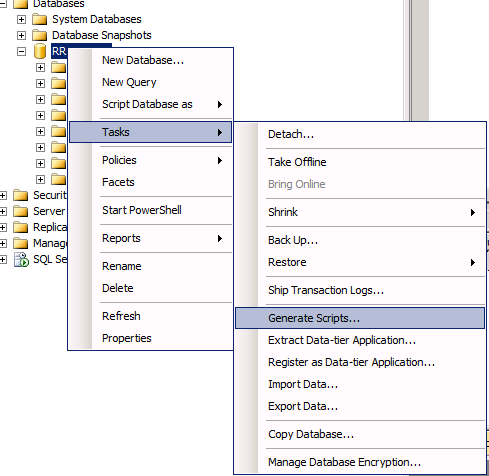
Choose “Select specific database objects” and check only your application schema Tables (untick dbo schema objects and others if any).
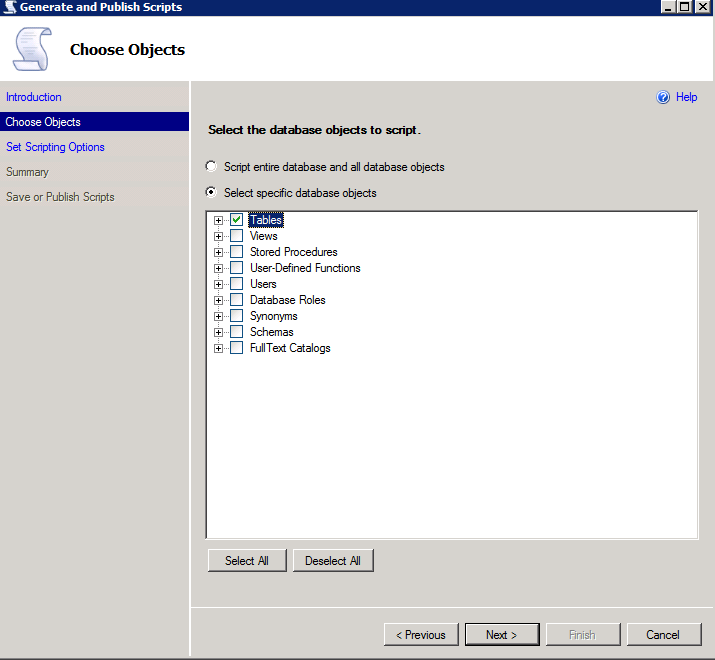
Ensure that “Types of data to script” in advanced options is set to “Schema only”.
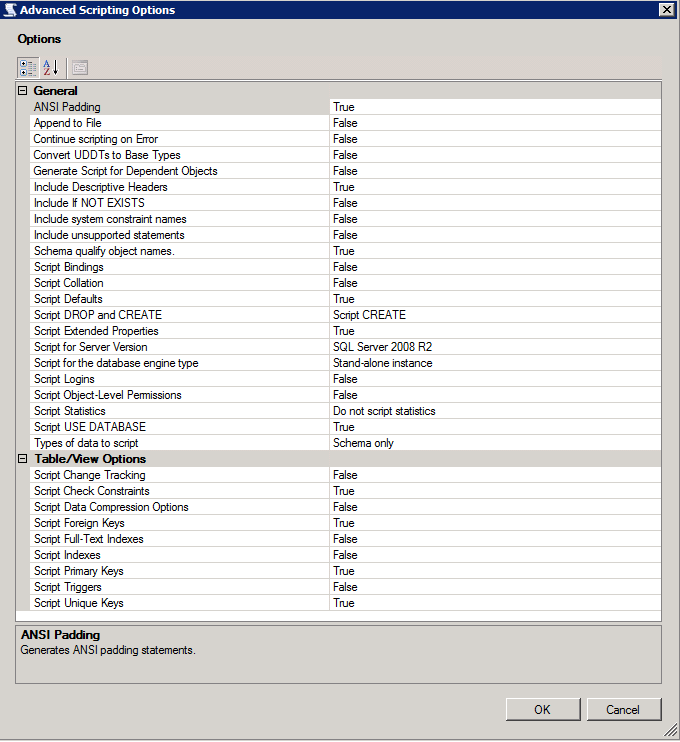
Review and save the database tables schema file tables.sql. Use WinSCP and public key auth to transfer tables.sql to the Linux server.
Convert Schema from SQL Server to Postgres
sqlserver2pgsql is a good migration tool written in Perl to convert SQL Server schemas to Postgres schemas. Clone it from GitHub to your database server and execute the following commands to convert the tables schema:
$ git clone https://github.com/dalibo/sqlserver2pgsql.git
$ cd sqlserver2pgsql
$ perl sqlserver2pgsql.pl -f tables.sql -b tables-before.sql -a tables-after.sql -u tables-unsure.sqlThe converted schema will be available in tables-before.sql and statements to create constraints will be in tables-after.sql to execute after data migration. Just review tables-unsure.sql and do what’s needed if there are any tables not converted by the tool. If you want to change any schema names in Postgres, you can rename them now in the SQL file, e.g.:
$ sed -i ‘s/sql_server_schema/public/g’ *.sqlSetup Postgres Database:
Hopefully, you have your Postgres database ready in your server. If not, install the latest version of Postgres on your server. Then create a Postgres user and database with permissions granted to the user.
CREATE USER <user_name> WITH
LOGIN
NOSUPERUSER
INHERIT
NOCREATEDB
NOCREATEROLE
NOREPLICATION;
CREATE DATABASE <database_name>
WITH
OWNER = <user_name>
ENCODING = 'UTF8'
LC_COLLATE = 'en_US.UTF-8'
LC_CTYPE = 'en_US.UTF-8'
TABLESPACE = pg_default
CONNECTION LIMIT = -1;Once the database and user account are ready, load the converted tables-before.sql script into your database to create tables. Then we can move forward with data migration.
psql -U user_name -p 5432 -h localhost -d database_name -f tables-before.sql
# or
database_name=# \i /path/to/tables-before.sqlData Migration
Data migration through data dump and restore makes the process cumbersome, with a huge manual process, data type mismatches, date formats, etc. It is wise to use existing stable systems instead of investing more time into it.
Pentaho Data Integration
Pentaho offers various stable data-centric products. Pentaho Data Integration (PDI) is an ETL tool which provides great support for migrating data between different databases without manual intervention. The community edition of PDI is good enough to perform our task here. It needs to establish a connection to both the source and destination databases. Then it will do the rest of work on migrating data from SQL server to Postgres database by executing a PDI job.
Download Pentaho Data Integration Community Edition and extract the tarball in your local environment. See:
- https://community.hitachivantara.com/community/products-and-solutions/pentaho/
- https://community.hitachivantara.com/docs/DOC-1009931-downloads
Run spoon.sh to open the GUI application in your local environment.
$ cd pentaho/data-integration
$ ./spoon.shCreate connections to both SQL Server and Postgres databases in PDI.
1. Create a New Job.
File → New → Job
2. Create Source Database Connection.
Click View in left sidebar → Right Click ‘Database Connections’ → Choose New → Provide SQL Server connection details
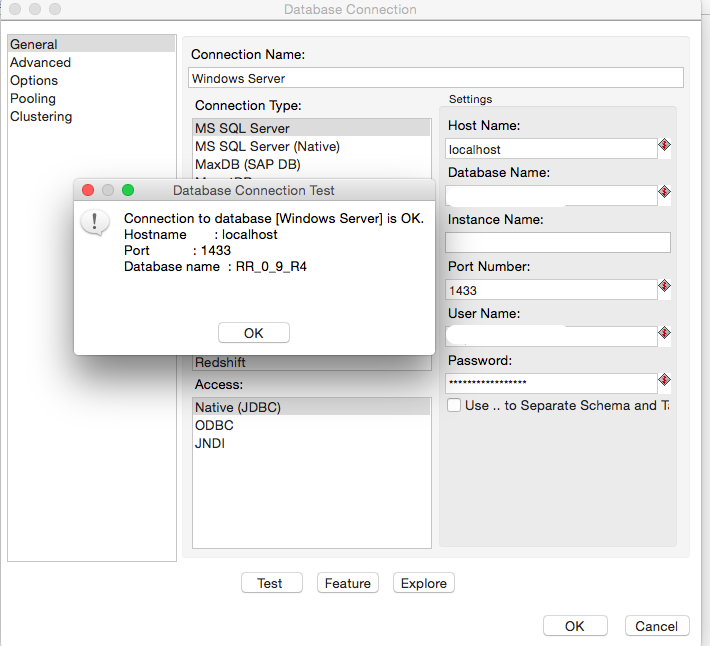
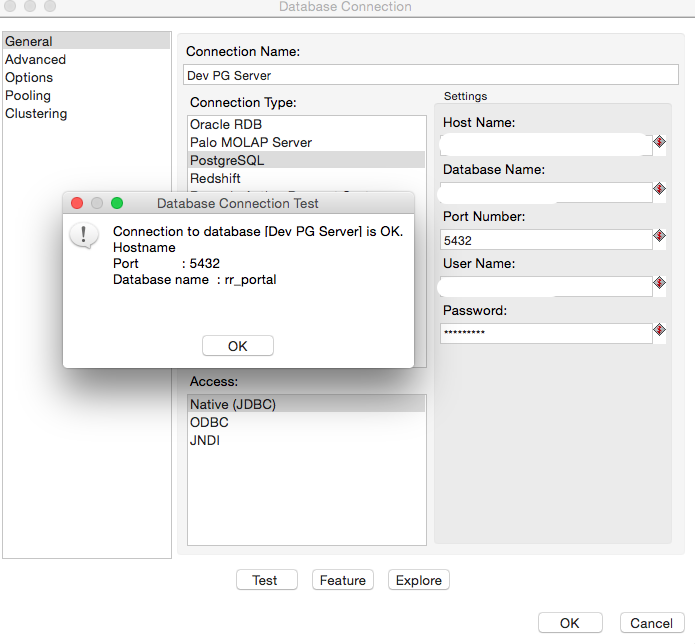
3. Create Destination Database Connection.
Click View in left sidebar → Right Click ‘Database Connections’ → Choose New → Provide Postgres connection details
4. From Wizard menu, choose Copy Tables Wizard.
Tools → Wizard → Copy Tables
5. Choose Source and Destination databases.
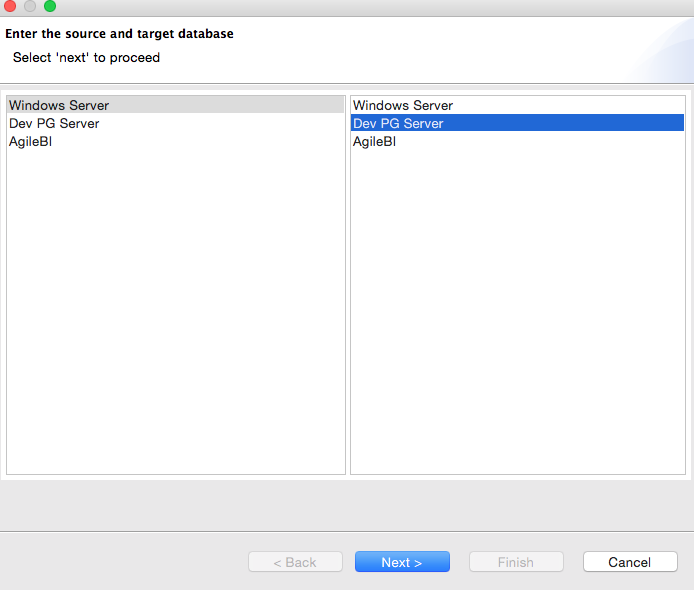
6. Select the list of tables to migrate.
7. Move forward to choose the path for job and transformation files.
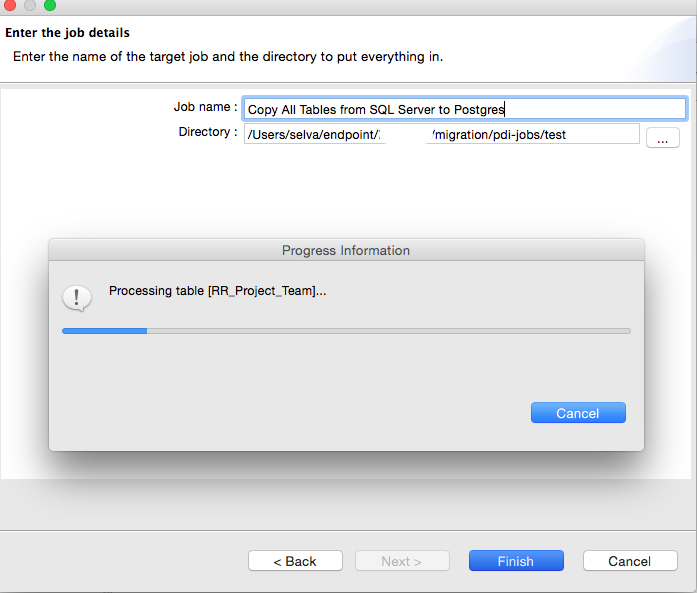
8. The transformations were created to copy data from source to destination database.
9. Copy the Pentaho Data Integration tarball and job with transformations to the Postgres server to avoid network latency on data migration.
$ tar -cvzf pdi-migration-job.tar.gz pdi-migration-job/
$ rsync -azP data-integration.zip pdi-migration-job.tar.gz user@server:10. Check Postgres server to SQL Server database access (based on architecture design at your end).
Establish SSH tunneling to connect to SQL Server through the application server.
$ cat config
host tunnel-server
Hostname <application_server>
Port 22
User root
LocalForward 1433 <ipaddress>:1433
$ ssh tunnel-server
$ telnet localhost 1433PDI Job Execution
Execute PDI job using Pentaho kitchen utility on the database server. Add a kettle configuration to avoid Pentaho considering empty values as NULL values which affects NOT NULL constraints.
$ cat .kettle/kettle.properties
KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL=YConfirm IP address for database servers’ connections and execute the job using kitchen.sh, a command-line utility to execute PDI jobs.
$ ./kitchen.sh -file="/path/to/pdi-migration-job.kjb" -level=Basic | tee pdi-migration-job.logThe data migration process took around 30 minutes to copy 10GB of data from SQL Server to Postgres database over network.
Output:
2018/08/23 11:16:52 - SQLServerToPostgres20180823 - Job execution finished
2018/08/23 11:16:52 - Kitchen - Finished!
2018/08/23 11:16:52 - Kitchen - Start=2018/08/23 10:51:00.701, Stop=2018/08/23 11:16:52.951
2018/08/23 11:16:52 - Kitchen - Processing ended after 25 minutes and 52 seconds (1552 seconds total).We ran into a space problem while copying a large table and handled it by reducing the number of rows size in the corresponding table transformation file. Here’s a discussion of the problem.
Fix:
vi **table_name**.ktr
<size_rowset>100</size_rowset>
sed 's/<size_rowset>10000<\/size_rowset>/<size_rowset>100<\/size_rowset>/' *table_name*Once the data migration is completed, execute the tables-after.sql schema-migration script to apply constraints.
Migrate Views
Follow the same steps to convert the views.sql schema. Right click on the database and click on Tasks → Generate Script → Export only views.
$ perl sqlserver2pgsql.pl -f views.sql -b views-before.sql -a views-after.sql -u views-unsure.sqlMigrate Functions
The functions migration requires skill and syntax awareness of both SQL Server and Postgres. The functions need to validated and tested properly after rewriting for Postgres. Place all rewritten functions into postgres-function.sql and load into the database as part of the migration process.
Most Common Errors
-
ERROR: syntax error at or near "["
Remove SQL Server square brackets quoting around column and table names.
SELECT [user_id] → SELECT user_id -
ERROR: operator does not exist: character varying = integer
Type casting on comparison
AND column_name in (1, -1) → AND column_name in (‘1’, ‘-1’) -
ERROR: syntax error at or near ","
Datatype conversion
convert(varchar(10),column_name) → column_name::text -
ERROR: column "user_id" of relation "user" does not exist
No double quotes on mixed-case column names (unless used everywhere)
INSERT INTO user (“user_id”) VALUES (1) → INSERT INTO user (user_id) VALUES (1) -
ERROR: column "mm" does not exist
DATEADD → INTERVAL
DATEADD(mm,-6,GETDATE()) → CURRENT_DATE - INTERVAL ‘6 months’ -
ERROR: column "varchar" does not exist
Convert date to USA format
convert(varchar, tc_agreed_dt, 101) → to_char(CURRENT_TIMESTAMP, ‘MM/DD/YYYY’)
Result
After migration, we performed extensive testing on the application and optimized the queries in various modules. We also performed a benchmark test on speed and performance between the new and old systems. The migration paid off with a promising result of 40% average gain on overall performance of the application. That reflects the newer server hardware as well as the query optimization work, not solely the move to Postgres.
The entire migration was automated with a script to test multiple times and reduce manual intervention to perform error-free process. The automated script is available to customize based on your scenario: sqlserver-postgres-migration-automation.sh
pentaho postgres database sql sql-server casepointer
Comments