Postgres statistics and the pain of analyze

By Greg Sabino Mullane
December 7, 2016

Anytime you run a query in Postgres, it needs to compile your SQL into a lower-level plan explaining how exactly to retrieve the data. The more it knows about the tables involved, the smarter the planner can be. To get that information, it gathers statistics about the tables and stores them, predictably enough, in the system table known as pg_statistic. The SQL command ANALYZE is responsible for populating that table. It can be done per-cluster, per-database, per-table, or even per-column. One major pain about analyze is that every table must be analyzed after a major upgrade. Whether you upgrade via pg_dump, pg_upgrade, Bucardo, or some other means, the pg_statistic table is not copied over and the database starts as a clean slate. Running ANALYZE is thus the first important post-upgrade step.
Unfortunately, analyze can be painfully slow. Slow enough that the default analyze methods sometimes take longer that the entire rest of the upgrade! Although this article will focus on the pg_upgrade program in its examples, the lessons may be applied to any upgrade method. The short version of the lessons is: run vacuumdb in parallel, control the stages yourself, and make sure you handle any custom per-column statistics.
Before digging into the solution in more detail, let’s see why all of this is needed. Doesn’t pg_upgrade allow for super-fast Postgres major version upgrades, including the system catalogs? It does, with the notable exception of the pg_statistics table. The nominal reason for not copying the data is that the table format may change from version to version. The real reason is that nobody has bothered to write the conversion logic yet, for pg_upgrade could certainly copy the pg_statistics information: the table has not changed for many years.
At some point, a DBA will wonder if it is possible to simply copy the pg_statistic table from one database to another manually. Alas, it contains columns of the type “anyarray”, which means it cannot be dumped and restored:
$ pg_dump -t pg_statistic --data-only | psql -q
ERROR: cannot accept a value of type anyarray
CONTEXT: COPY pg_statistic, line 1, column stavalues1: "{"{i,v}","{v}","{i,o,o}","{i,o,o,o}","{i,i,i,v,o,o,o}","{i,i,o,o}","{i,o}","{o,o,o}","{o,o,o,o}","{o..."I keep many different versions of Postgres running on my laptop, and use a simple port naming scheme to keep them straight. It’s simple enough to use pg_dump and sed to confirm that the structure of the pg_statistic table has not changed from version 9.2 until 9.6:
$ for z in 840 900 910 920 930 940 950; do echo -n $z: ; diff -sq <(pg_dump \
> --schema-only -p 5$z -t pg_statistic | sed -n '/CREATE TABLE/,/^$/p') <(pg_dump \
> --schema-only -p 5960 -t pg_statistic | sed -n '/CREATE TABLE/,/^$/p'); done
840:Files /dev/fd/63 and /dev/fd/62 differ
900:Files /dev/fd/63 and /dev/fd/62 differ
910:Files /dev/fd/63 and /dev/fd/62 differ
920:Files /dev/fd/63 and /dev/fd/62 are identical
930:Files /dev/fd/63 and /dev/fd/62 are identical
940:Files /dev/fd/63 and /dev/fd/62 are identical
950:Files /dev/fd/63 and /dev/fd/62 are identicalOf course, the same table structure does not promise that the backend of different versions uses them in the same way (spoiler: they do), but that should be something pg_upgrade can handle by itself. Even if the table structure did change, pg_upgrade could be taught to migrate the information from one format to another (its raison d’être). If the new statistics format take a long time to generate, perhaps pg_upgrade could leisurely generate a one-time table on the old database holding the new format, then copy that over as part of the upgrade.
Since pg_upgrade currently does none of those things and omits upgrading the pg_statistics table, the following message appears after pg_upgrade has been run:
Upgrade Complete
----------------
Optimizer statistics are not transferred by pg_upgrade so,
once you start the new server, consider running:
./analyze_new_cluster.shLooking at the script in question yields:
#!/bin/sh
echo 'This script will generate minimal optimizer statistics rapidly'
echo 'so your system is usable, and then gather statistics twice more'
echo 'with increasing accuracy. When it is done, your system will'
echo 'have the default level of optimizer statistics.'
echo
echo 'If you have used ALTER TABLE to modify the statistics target for'
echo 'any tables, you might want to remove them and restore them after'
echo 'running this script because they will delay fast statistics generation.'
echo
echo 'If you would like default statistics as quickly as possible, cancel'
echo 'this script and run:'
echo ' vacuumdb --all --analyze-only'
echo
vacuumdb --all --analyze-in-stages
echo
echo 'Done'There are many problems in simply running this script. Not only is it going to iterate through each database one-by-one, but it will also process tables one-by-one within each database! As the script states, it is also extremely inefficient if you have any per-column statistics targets. Another issue with the –analyze-in-stages option is that the stages are hard-coded (at “1”, “10”, and “default”). Additionally, there is no way to easily know when a stage has finished other than watching the command output. Happily, all of these problems can be fairly easily overcome; let’s create a sample database to demonstrate.
$ initdb --data-checksums testdb
$ echo port=5555 >> testdb/postgresql.conf
$ pg_ctl start -D testdb
$ createdb -p 1900 alpha
$ pgbench alpha -p 1900 -i -s 2
$ for i in `seq 1 100`; do echo create table pgb$i AS SELECT \* FROM pgbench_accounts\;; done | psql -p 1900 alphaNow we can run some tests to see the effect of the –jobs option. Graphing out the times shows some big wins and nice scaling. Here are the results of running vacuumdb alpha –analyze-only with various values of –jobs:
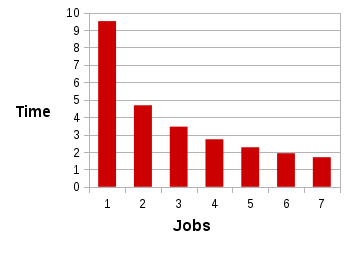
The slope of your graph will be determined by how many expensive-to-analyze tables you have. As a rule of thumb, however, you may as well set –jobs to a high number. Anything over your max_connections setting is pointless, but don’t be afraid to jack it up to at least a hundred. Experiment on your test box, of course, to find the sweet spot for your system. Note that the –jobs argument will not work on old versions of Postgres. For those cases, I usually whip up a Perl script using Parallel::ForkManager to get the job done. Thanks to Dilip Kumar for adding the –jobs option to vacuumdb!
The next problem to conquer is the use of custom statistics. Postgres’ ANALYZE uses the default_statistics_target setting to determine how many rows to sample (the default value in modern versions of Postgres is 100). However, as the name suggests, this is only the default—you may also set a specific target at the column level. Unfortunately, there is no way to disable this quickly, which means that vacuumdb will always use the custom value. This is not what you want, especially if you are using the –analyze-in-stages option, as it will happily (and needlessly!) recalculate columns with specific targets three times. As custom stats are usually set much higher than the default target, this can be a very expensive option:
$ ## Create a largish table:
$ psql -qc 'create unlogged table aztest as select * from pgbench_accounts'
$ for i in {1..5}; do psql -qc 'insert into aztest select * from aztest'; done
$ psql -tc "select pg_size_pretty(pg_relation_size('aztest'))"
820 MB
$ psql -qc '\timing' -c 'analyze aztest'
Time: 590.820 ms ## Actually best of 10: never get figures from a single run!
$ psql -c 'alter table aztest alter column aid set statistics 1000'
ALTER TABLE
$ psql -qc '\timing' -c 'analyze aztest'
Time: 2324.017 ms ## as before, this is the fastest of 10 runsAs you can see, even a single column can change the analyze duration drastically. What can we do about this? The –analyze-in-stages is still a useful feature, so we want to set those columns back to a default value. While one could reset the stats and then set them again on each column via a bunch of ALTER TABLE calls, I find it easier to simply update the system catalogs directly. Specifically, the pg_attribute table contains a attstattarget column which has a positive value when a custom target is set. In our example above, the value of attstattarget for the aid column would be 1000. Here is a quick recipe to save the custom statistics values, set them to the default (-1), and then restore them all once the database-wide analyzing is complete:
## Save the values away, then reset to default:
CREATE TABLE custom_targets AS SELECT attrelid, attname, attnum, attstattarget
FROM pg_atttribute WHERE attstattarget > 0;
UPDATE pg_attribute SET attstattarget = -1 WHERE attstattarget > 0;
## Safely run your database-wide analyze now
## All columns will use default_statistics_target
## Restore the values:
UPDATE pg_attribute a SET attstattarget = c.attstattarget
FROM custom_targets c WHERE a.attrelid = c.attrelid
AND a.attnum = c.attnum AND a.attname = c.attname;
## Bonus query: run all custom target columns in parallel:
SELECT 'vacuumdb --analyze-only -e -j 100 ' ||
string_agg(format('-t "%I(%I)" ', attrelid::regclass, attname), NULL)
FROM pg_attribute WHERE attstattarget > 0;As to the problems of not being able to pick the stage targets for –analyze-in-stages, and not being able to know when a stage has finished, the solution is to simply do it yourself. For example, to run all databases in parallel with a target of “2”, you would need to change the default_statistics_target at the database level (via ALTER DATABASE), or at the cluster level (via ALTER SYSTEM). Then invoke vacuumdb, and reset the value:
$ psql -qc 'alter system set default_statistics_target = 2' -qc 'select pg_reload_conf()'
$ vacuumdb --all --analyze-only --jobs 100
$ psql -qc 'alter system reset default_statistics_target' -qc 'select pg_reload_conf()'In summary, don’t trust the given vacuumdb suggestions for a post-upgrade analyze. Instead, remove any per-column statistics, run it in parallel, and do whatever stages make sense for you.
Comments