How fast is pg_upgrade anyway?

By Greg Sabino Mullane
July 1, 2015

Back in the old days, upgrading Postgres required doing a pg_dump and loading the resulting logical SQL into the new database. This could be a very slow, very painful process, requiring a lot of downtime. While there were other solutions (such as Bucardo) that allowed little (or even zero) downtime, setting them up was a large complex task. Enter the pg_upgrade program, which attempts to upgrade a cluster with minimal downtime. Just how fast is it? I grew tired of answering this question from clients with vague answers such as “it depends” and “really, really fast” and decided to generate some data for ballpark answers.
Spoiler: it’s either about 3.5 times as fast as pg_dump, or insanely fast at a flat 15 seconds or so. Before going further, let’s discuss the methodology used.
I used the venerable pgbench program to generate some sample tables and data, and then upgraded the resulting database, going from Postgres version 9.3 to 9.4. The pgbench program comes with Postgres, and simply requires an –initialize argument to create the test tables. There is also a –scale argument you can provide to increase the amount of initial data—each increment increases the number of rows in the largest table, pgbench_accounts, by one hundred thousand rows. Here are the scale runs I did, along with the number of rows and overall database size for each level:
| --scale | Rows in pgbench_accounts | Database size |
|---|---|---|
| 100 | 10,000,000 | 1418 MB |
| 150 | 15,000,000 | 2123 MB |
| 200 | 20,000,000 | 2829 MB |
| 250 | 25,000,000 | 3535 MB |
| 300 | 30,000,000 | 4241 MB |
| 350 | 35,000,000 | 4947 MB |
| 400 | 40,000,000 | 5652 MB |
| 450 | 45,000,000 | 6358 MB |
| 500 | 50,000,000 | 7064 MB |
| 550 | 55,000,000 | 7770 MB |
| 600 | 60,000,000 | 8476 MB |
To test the speed of the pg_dump program, I used this simple command:
$ pg_dump postgres | psql postgres -q -p 5433 -f -I did make one important optimization, which was to set fsync off on the target database (version 9.4). Although this setting should never be turned off in production—or anytime you cannot replace all your data, upgrades like this are an excellent time to disable fsync. Just make sure you flip it back on again right away! There are some other minor optimizations one could make (especially boosting maintenance_work_mem), but for the purposes of this test, I decided that the fsync was enough.
For testing the speed of pg_upgrade, I used the following command:
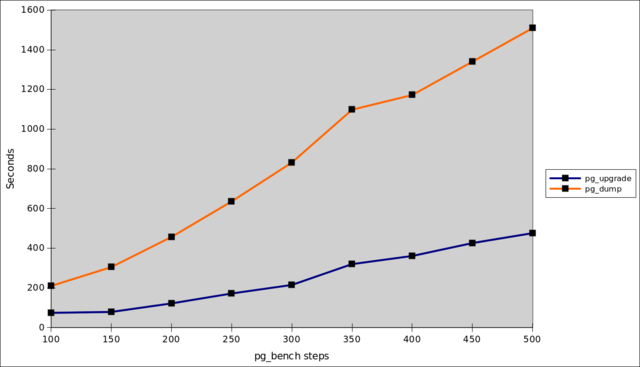
$ pg_upgrade -b $BIN1 -B $BIN2 -d $DATA1 -D $DATA2 -P 5433The speed difference can be understood because pg_dump rewrites the entire database, table by table, row by row, and then recreates all the indexes from scratch. The pg_upgrade program simply copies the data files, making the minimum changes needed to support the new version. Because of this, it will always be faster. How much faster depends on a lot of variables, e.g. the number and size of your indexes. The chart below shows a nice linear slope for both methods, and yielding on average a 3.48 increase in speed of pg_upgrade versus pg_dump:
| --scale | Database size | pg_dump (seconds) | pg_upgrade (seconds) | Speedup |
|---|---|---|---|---|
| 100 | 1.4 GB | 210.0 | 74.7 | 2.82 |
| 150 | 2.1 GB | 305.0 | 79.4 | 3.86 |
| 200 | 2.8 GB | 457.6 | 122.2 | 3.75 |
| 250 | 3.5 GB | 636.1 | 172.1 | 3.70 |
| 300 | 4.2 GB | 832.2 | 215.1 | 3.87 |
| 350 | 4.9 GB | 1098.8 | 320.7 | 3.43 |
| 400 | 5.7 GB | 1172.7 | 361.4 | 3.25 |
| 450 | 6.4 GB | 1340.2 | 426.7 | 3.15 |
| 500 | 7.1 GB | 1509.6 | 476.3 | 3.17 |
| 550 | 7.8 GB | 1664.0 | 480.0 | 3.47 |
| 600 | 8.5 GB | 1927.0 | 607 | 3.17 |
If you graph it out, you can see both of them having a similar slope, but with pg_upgrade as the clear winner:
I mentioned earlier that there were some other optimizations that could be done to make the pg_dump slightly faster. As it turns out, pg_upgrade can also be made faster. Absolutely, beautifully, insanely faster. All we have to do is add the –link argument. What this does is rather than copying the data files, it simply links them via the filesystem. Thus, each large data file that makes up the majority of a database’s size takes a fraction of a second to link to the new version. Here are the new numbers, generated simply by adding a –link to the pg_upgrade command from above:
| --scale | Database size | pg_upgrade --link (seconds) |
|---|---|---|
| 100 | 1.4 GB | 12.9 |
| 150 | 2.1 GB | 13.4 |
| 200 | 2.8 GB | 13.5 |
| 250 | 3.5 GB | 13.2 |
| 300 | 4.2 GB | 13.6 |
| 350 | 4.9 GB | 14.4 |
| 400 | 5.7 GB | 13.1 |
| 450 | 6.4 GB | 13.0 |
| 500 | 7.1 GB | 13.2 |
| 550 | 7.8 GB | 13.1 |
| 600 | 8.5 GB | 12.9 |
No, those are not typos—an average of thirteen seconds despite the size of the database! The only downside to this method is that you cannot access the old system once the new system starts up, but that’s a very small price to pay, as you can easily backup the old system first. There is no point in graphing these numbers out—just look at the graph above and imagine a nearly flat line traveling across the bottom of the graph :)
Are there any other options that can affect the time? While pgbench has a handy –foreign-keys argument I often use to generate a more “realistic” test database, both pg_dump and pg_upgrade are unaffected by any numbers of foreign keys. One limitation of pg_upgrade is that it cannot change the –checksum attribute of a database. In other words, if you want to go from a non-checksummed version of Postgres to a checksummed version, you need to use pg_dump or some other method. On the plus side, my testing found negligible difference between upgrading a checksummed versus a non-checksummed version.
Another limitation of the pg_upgrade method is that all internal stats are blown away by the upgrade, so the database starts out in a completely unanalyzed state. This is not as much an issue as it used to be, as pg_upgrade will generate a script to regenerate these stats, using the handy –analyze-in-stages argument to vacuum. There are a few other minor limitations to pg_upgrade: read the documentation for a complete list. In the end, pg_upgrade is extraordinarily fast and should be your preferred method for upgrading. Here is a final chart showing the strengths and weaknesses of the major upgrade methods.
| Method | Strengths | Weaknesses |
|---|---|---|
| pg_dump |
|
|
| pg_upgrade |
|
|
| Bucardo |
|
|
(As an addendum of sorts, pg_upgrade is fantastic, but the Holy Grail is still out of sight: true in-place upgrades. This would mean dropping in a new major version (similar to the way revisions can be dropped in now), and this new version would be able to read both old and new data file formats, and doing an update-on-write as needed. Someday!)
Comments